给CPU直接开挂!从OpenPOWER的CAPI+FPGA看第二代异构计算
什么是异构计算?可能在很多人看来感觉高深莫测,我们可以先用一个比喻来简单的解释一下。比如在做简单的整数算数时,知道算法口诀的人,心算即可,但遇到比较复杂的算数问题时,就得需要一个计算器了,但在这个运算过程中,一些简单的计算可以提前由心算完成再输入计算器,比如计算“(5+2)÷26”,可能我们直接就输入“7÷26”了。又或者是完全交给计算器进行计算,但这也需要人脑控制手指进行计算器的数值输入,此时你的大脑与计算器就构成了完成这道数学计算任务的“异构计算系统”。
日常生活中最常见的异构计算——人脑+计算器
就像你的大脑的结构与计算器完全不一样,异构计算,顾名思义就是在系统内参与计算的执行单元在指令集架构(ISA, Instruction Set Architectures)层面是不同的。最为典型的例子,就是通用计算图形处理器(GPGPU,General-Purpose computing on Graphics Processing Units),与现场可编程门阵列 (FPGA,Field-Programmable Gate Array)。从严格意义上讲,ISA相同,只是处理核心大小同的组合,并不算是异构计算,比如英特尔的x86处理器+MIC(集成众核加速器),以及ARM处理器的big.LITTLE大小核心的混合设计。
异构计算简史
为什么要用异构计算,想想开头的例子就清楚了,如果人脑就是主流的通用处理器的话,那么异构计算就是为这个处理器额外配备的“计算器”,用来执行更高复杂度的计算或应用,而这种复杂度主要指的就是超大规模的并行处理,对于更擅长串行处理的CPU来说是一个极大的互补。
异构计算的概念本身其实并不新鲜,最早可以追溯到30年前(在某些定义中,则是以指令集的处理模式来区分异构,但基本上已并非是主流概念),可要谈到异构计算的真正崛起,则要从2001年用GPU实现通用矩阵计算开始,而标志性事件发生在2005年,GPU终于在执行LU分解(用于解线性方程组)的性能方面战胜了CPU,从那之后,基于GPU的大规模并行计算方案开始崭露头角。
CPU+GPGPU是目前最为知名的异构计算组合,也是第一代异构计算的典型代表
2007年,NVIDIA推出了专门用于简化GPU应用编程的统一计算设备架构(CUDA,Compute Unified Device Architecture),它标志着GPU的通用计算应用开发开始走向易用、成熟。时至今日,GPU+CPU的异构计算系统已经越来越多的出现在高性能计算系统(HPC),大大弥补了CPU在浮点运算方面的能力。
当然,在GPGPU之前其实还有多种芯片在向通用计算领域迈进,其中之一就是FPGA,它是最可匹敌于GPGPU的异构计算技术。
2012年英特尔发布的Atom E6x5C嵌入式处理器,就已经在单Socket封装上整合了Altera的FPGA,但这个FPGA的主要任务不是计算,而是针对不同应用场景的I/O定制化与指定的信号处理,很难用于通用场合
FPGA于1985年诞生,很快就开始尝试在通用计算领域的运用,可以说比GPGPU的出现还要早。GPGPU所擅长的浮点运算,FPGA同样也在积极参与,但成果远没有GPGPU显著(看看超级计算机全球TOP500的排名配置就知道了),而在整数型运算方面,虽然FPGA更有优势,可惜那时的计算量除非个别应用,普遍并不大,CPU自己就能搞定,所以FPGA加速更多用于细分应用市场,应用规模相对来说并不大。不过,随着物联网、大数据、人工智能、机器学习等新兴的大规模数据处理需求的不断涌现,现在它的机会要来了,而且底层互联 技术也比当前的异构系统更为先进,它就是由OpenPOWER CAPI所开辟的新一代异构计算平台,主打CAPI+FPGA的组合。
而在我看来,它们其实是开启了第二代异构计算的时代。
FPGA如何为应用加速?
从第一款FPGA芯片于1985年由Xilinx(赛灵思)正式推出至今,已经有30年历史,它是在可编程阵列逻辑(PAL,Programmable Array Logic)、通用阵列逻辑(GAL,Generic Array Logic)、复杂可编程逻辑器件(CPLD,Complex Programmable Logic Device) 等技术的基础上进一步发展的产物。与CPU不同的是,它的逻辑是硬件可编程的,而CPU则是通过软件编程来执行相应的计算,和专用集成电路(ASIC,Application Specific Integrated Circuit)相比,它又相当于一种半成品的逻辑芯片,ASIC则是针对某类应用进行专门的固化设计,以达到最优的性能。
从字面意思上就可以想像得到FPGA是一个可随意定制内部逻辑的阵列,并且可以在用户现场进行即时编程修改内部的硬件逻辑,这一点是CPU和ASIC都无法做到的。要想明白FPGA的原理,的确需要一定的数字电路基础,在此只做简要的介绍,以解释为什么FPGA可以在某些工作上比CPU更为出色。

FPGA的内部主要是由用于实现硬件逻辑的逻辑块(LB,Logic Block)、负责LB互联的内部互联交换节点(IS,Interconnection Switch)以及负责输入输出的I/O Block组成,它们都是可编程的,而随着技术的进步,FPGA芯片里也越来越多的集成相关的固定器件与硬核(IP)电路,如乘法器、数字信号处理器(Digital Signal Processor)等,以进一步加速相关的运算,并完善相关的功能(比如I/O)

LB是FPGA内的基本逻辑单元,是FPGA可实现逻辑编程的基础,而在LB中最常用的逻辑编程器件就是查找表(LUT,Look Up Table,又称直译表),通过编程它可以实现输入与输出的直接对应关系,从而实现了输入与输出的硬逻辑,在应用时,直接根据输入的值,通过LUT给出相应的输出值。输入的组合根据输入端口数量而定,比如4个端口就可实现16种输入组合(2的4次方),而一个LB可以包含有多个LUT,实现更复杂的逻辑组合
FPGA的内部总体架构,主要是由实现硬件逻辑的逻辑块(LB)、负责LB互联的内部互联交换节点(IS)以及负责输入输出的I/O Block组成。由于几乎所有的逻辑电路都是通过不同门电路的组合来实现的,所以FPGA其实就是提供了数量众多的门电路,让用户用硬件描述语言(HDL,Hardware Description Language)自行设计它们各自的逻辑状态与相互之间的逻辑关系,从而让被编程的FPGA变成为某种专用芯片,所以说FPGA是ASIC的半成品,不无道理。
事实上,FPGA在早期的一个重要的用途就是为了更好的设计ASIC,毕竟等ASIC生产出来再实验的成本太大,而通过FPGA可以提供进行复杂的逻辑测试,来验证ASIC的设计,并进行反复的优化,当逻辑优化到相当水平后,再以更为直接的逻辑实现方法形成ASIC电路,以达到更好的性能。但随着FPGA自身的性能、能力与可实现逻辑的复杂度的不断提升,已经逐渐可以直接代替一些中等规模的ASIC来使用,并在整体功耗上,保持对CPU的明显优势。
在国内率先开发CAPI+FPGA加速卡解决方案的恒扬科技股份有限公司,大数据采集与分析产品经理张军这样形容FPGA,“FPGA就是一张白纸,(最终的逻辑电路)想画什么完全由设计师决定,而 CPU或者等其他软件编程的器件就像铅笔画素描画(已经有了框架),设计师是在上面涂色彩。” 事实上,FPGA可以实现怎样的能力,主要就取决于它所提供的门电路的规模。
现在主流的FPGA内部均采用了SRAM编程方式(SRAM本身就是一个逻辑部件可用于LUT,而SRAM晶体管可用于内部互联链路的选通组合),可以实现快速的硬件编程,并能无限次的重复使用。虽然SRAM的特性决定了关机后内部逻辑组合就会消失,但基于SRAM的编程在每次开机时都可以从外部的Flash芯片即时加载FPGA配置文章,加载(编程)速度为毫秒级,所以完全不影响使用。在处理性能上,由于FPGA的逻辑实现是通过硬件编程来获得,所以开发人员可以将指定的算法逻辑,直接以FPGA内部不同门电路的硬逻辑组合来实现,而且现在越来越多的FPGA内部都增加了固化的乘法器、DSP等处理单元,进一步加快了相关运算的处理速度。
从某种角度上说,FPGA内部其实并没有所谓的“计算”,最终结果几乎是“电路直给”,因此执行效率就大幅提高。当然,由于采用的是通用的门电路组合,在某些效率上FPGA仍然不及ASIC极致,但是可重复更新内部逻辑的灵活性,再加上在固定算法上远高于CPU的效率,让FPGA在应用领域迅速得到重视。然而需要指出的是,用FPGA的门电路实现整数运算逻辑,要比实现浮点运算逻辑简单得多,所以FPGA的加速优势也更多的体现在整数性运算,而整数运算正是当前主流企业级应用的主要运算方式,而这也是为什么GPGPU更多的用于浮点运算领域(如HPC),FPGA更多用于整数加速领域的一大原因。
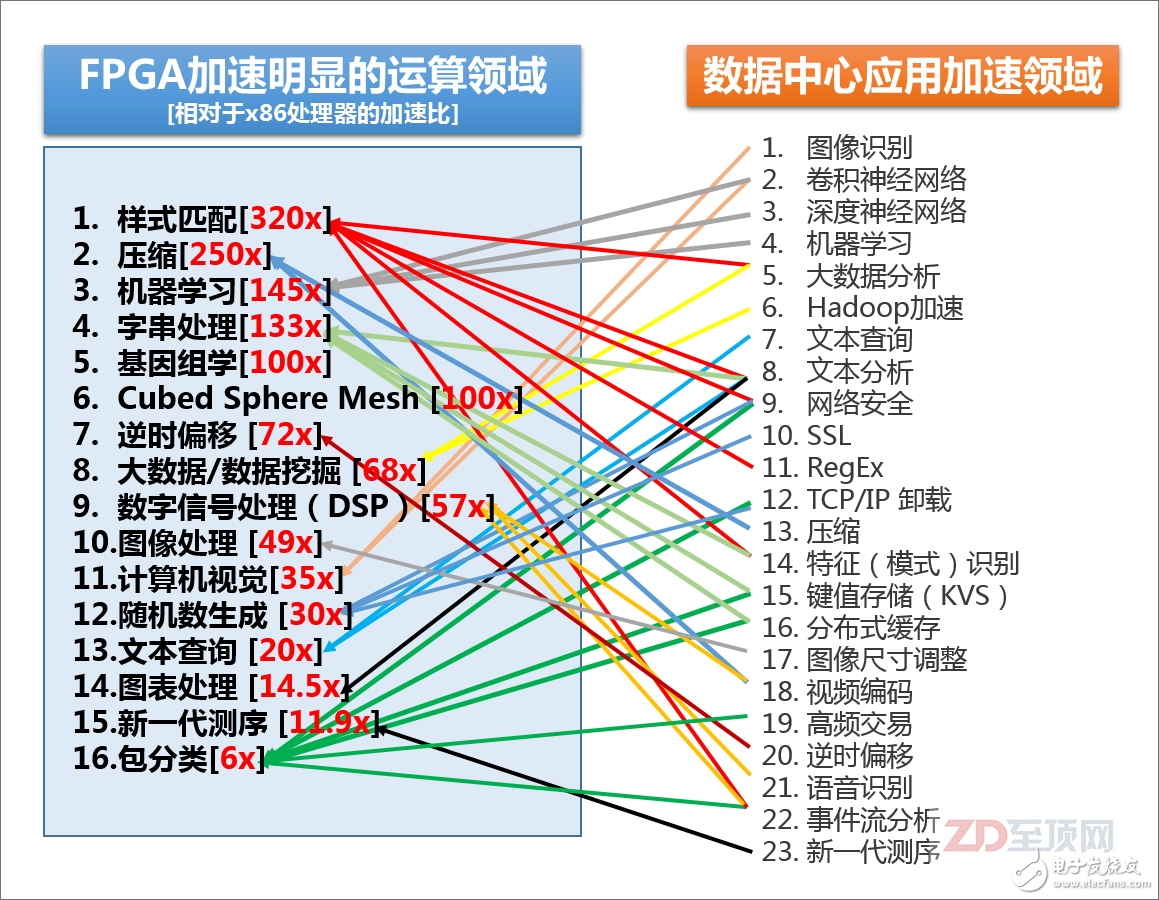
赛灵思总结的,目前FPGA相对于主流的x86处理器,在某些领域里的加速比,以及目前数据中心里可用到FPGA加速的领域,可以说80-90%的大规模并行密集应用都可以被FPGA加速,尤其是以整数应用为主。当然,并不是说FPGA不能用于浮点运算,但相对来说,整数型加速对于FPGA更容易实现,相对于GPGPU也有更明显的优势。另外,请注意很多IT基础设施的底层信息处理方面,如安全、加密、网络加速、键值存储也在FPGA的应用范畴之内,其“实用性”显然比GPGPU更为广泛
但是,传统的FPGA加速设计,均是以I/O总线与CPU平台相连,比如常见的PCIe,在系统内部以一个I/O设备存在,所以在实际的应用中,对于应用开发者本身来说仍然有较大的难度。这次CAPI的出现,则从根本上解决了这个难题,从而以FPGA的加速优势得以获得更充分的发挥。
- 第 1 页:给CPU直接开挂!从OpenPOWER的CAPI+FPGA看第二代异构计算
- 第 2 页:OpenPOWER CAPI简介
- 第 3 页:第二代异构计算与未来应用愿景
本文导航
非常好我支持^.^
(1) 100%
不好我反对
(0) 0%
相关阅读:
- [电子说] Blackwell GB100能否在超级计算机和AI市场保持领先优势? 2023-10-24
- [电子说] 3线串行数据通讯EEPROM的使用 2023-10-23
- [电子说] 浩辰软件深耕CAD领域 致力于成为行业标杆企业 2023-10-23
- [电子说] SymPy:四行代码秒解微积分 2023-10-21
- [电子说] 强固型智慧工厂解决方案:BOXER-6406-AND 2023-10-21
- [电子说] 飞秒激光器在医学上的应用 2023-10-21
- [电子说] TCP/IP协议和OPC协议的区别 2023-10-20
- [电子说] 机器视觉系统的基本原理 机器视觉技术的发展现状和应用 2023-10-19
( 发表人:郭婷 )