 德赢Vwin官网 App
德赢Vwin官网 App

COVA 协议拥有可以信任的TEE 节点,并将通过设计社区激励结构、多方秘密共享和计算方案,以激励各方诚实行事。
新的数据传输协议
过去的几年,以下几个技术都取得了新的进展:运用字节运行监控(Bytecode Runtime Monitoring)、可验证的秘密共享、可信执行环境(Trusted Execution Environment)以及基于博弈论的市场激励方案。通过利用上述技术创新,COVA 创建了一个新的 Web 3.0 分布式数据传输协议,从而实现网络的帕累托最优状态。
COVA协议由七层实现。在本文中,我们将为这七个层中的每一层提供简要说明:
第一层:数据所有者:dApp和数据存储
COVA 用户可以很容易地构建自己的 dApp,在测试阶段,我们构建了一个基于 electronjs 的多平台分散式应用程序(dApp)。这使得数据所有者能够在自己的个人计算机中安全地离线处理、编码和加密数据,具体如下:
1. 在数据处理阶段,敏感的数据集被用一个矢量 v 进行缩放。这样做的原因是为 TEE 节点增加安全防护——虽然TEE节点本身已经非常安全,极不可能被攻破。
2. 然后,数据将被编码为 COVA 的智能数据格式,其中包含数据所有者指定的数据使用权限条款(例如不能在下周日之前读取数据),再用 nacl 加密库进行加密。
3. 在完成处理、编码和加密步骤之后,这个 dApp 将加密密钥 K 和其他敏感信息(例如矢量 v)分割成 N(在我们的设计中,N=100)块:
在这里,我们使用受AdiShamir 秘密共享方案启发的阈值加密算法来生成这些秘密。然后,dApp将元数据记录到我们的数据目录区块链(第二层),并通过加密通道将 100 个秘密部分发送到 100 个路由节点。数据所有者还可以通过此界面与数据用户创建智能合约(或者在稍后阶段,数据使用者可以从目录中查找数据集并与数据所有者创建智能合约)。
在后续的文章更新中,我们将公布上述方案的各种细节,包括多方秘密共享方案,如何在保持结构的情况下进行矢量 v 缩放等。
此外,对于测试阶段的数据存储,我们不限制任何数据存储解决方案,大家可以选择许多现有的数据存储提供者(ipfs、s3、Dropbox 等)。数据所有者可以将加密数据上传到他们选择的任何存储解决方案中,并将数据集链接到我们的 dApp接口中。这些行为都是安全的,因为检索实际数据集的唯一方法是让某人同时访问密钥 K 和矢量 v,而这两者都是通过阈值加密方案保护的。如果没有大多数路由节点的共识,即使对手能够攻击大量的路由节点,他们也不能检索密钥。
第二层:数据目录区块链
数据目录区块链是分布式的分类帐本,用于保存数据集的元数据。获得许可的各方(通常是数据所有者或 TEE)可以更新分类账的元数据,但不能删除条目。我们在测试网络中使用了 tendermind 和 bigchaindb 来实现这个分类。
元数据字段是完全可定制的。dApp builder 可以让数据所有者设计所需的规范,根据数据用户平台的规范更改元数据(或格式),比如根据医疗数据集的分散式市场要求更改。
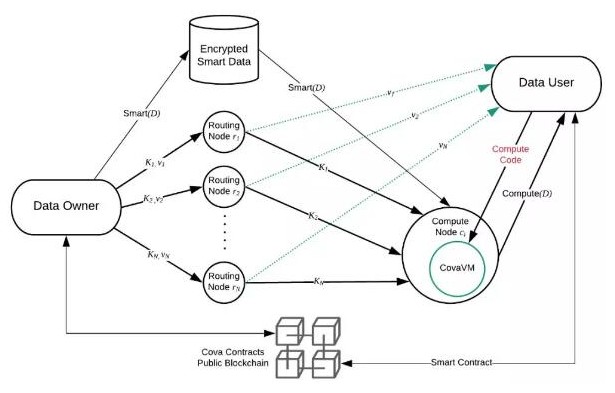
第三层:路由节点和计算节点池
COVA 的 TEE 节点分为两种:
路由节点:主要用于路由、验证和传输计算状态。每个池100个节点,高可用性、更高的安全押金和更高的奖励。
计算节点:主要用于计算,对退出中间计算有一个惩罚。其可以是 TEE 节点,也可以是 TEE 控制的云计算节点(CS2)。
为了保证高可用性,我们拥有多个由 100 个路由节点组成的池。正如我们将在第四层讨论的,我们需要多数人的共识和可用性来检索加密密钥,我们希望激励节点高度可用,同时将冗余计算的数量保持在最低限度。
我们有各种激励和惩罚,以尽量减少恶意行为和最大限度地利用网络。例如,如果某一个路由节点不满足我们的可用性标准(比如确保 99% 以上正常运行时间),其他路由节点可以集体投票将此路由节点降级到计算节点,其他一些激励和惩罚措施,我们将在介绍第六层时补充。
最后,路由节点和计算节点都具有极高的安全性,它们都是运行IntelSGX 军事级别隐私保护技术的 TEE 节点,唯一的区别是路由节点是根据可用性和较高的押金投入而选择的社区。而且,包括多方秘密共享、扩展或激励结构在内的机制都已到位,足以防止节点主机在出现某些 zero-day 漏洞攻击下损害 TEE 节点——虽然这种情况出现的可能性极小。
第四层:路由节点上的阈值加密密钥存储
COVA 使用可验证的多方秘密共享方案,而不是完全信任一个 TEE 路由节点(比如数据加密密钥)。我们使用了 Shamir 秘密共享方案的一个延伸方案。当我们拥有大多数诚实路由节点时,它可以生成秘密。此外,它还可以检测一个路由节点是否诚实,这样我们就可以禁止某些不诚实的路由节点。这个方案背后的数学概念如下:
1. 数据所有者生成一个 100m 个随机多项式,其中 m 是诚实路由节点的最小分数,常数多项式是加密密钥。
2. 然后,数据所有者在 100 个不同的点上计算该多项式,并将这些秘密共享发送到路由节点。路由节点不能重新创建密钥,除非至少有 m 个节点提供了它们的秘密共享。
3. 此外,在至少有 m 个诚实的情况下,如果其他节点不诚实,我们可以检测到恶意用户。
在我们的设计中,秘密共享方案被用于共享加密密钥和缩放矢量 v。
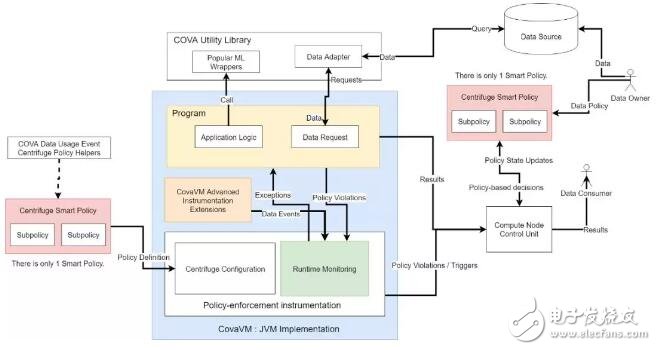
第五层:智能条款执行器
智能条款执行器指的是在 TEE 节点上运行的 Centrifuge 语言和 CovaVM 虚拟机。举个例子,假定我们需要运行一个来自数据使用者的不可信代码,就需要创建一个沙盒,CovaVM,并启用一个运行时监视系统,以确保代码遵循数据所有者设置的数据使用条款。目前为止,我们已经实现了开放源代码的安全模型,确保数据用户只能运行pythonsklearn 或者Tensorflow库中 28 个已批准的机器学习模型,我们会使用 Centrifuge 来验证。
第六层:社区经济:支付和激励
社区经济是一个抽象的层次。它帮助我们实现目标,即通过 COVA 基金会的最小干预,创建一个自我维持的、分散的网络。要做到这一点,我们需要精心设计支付和奖励措施。我们需要支付各种步骤,包括计算奖励的 TEE 计算节点、路由奖励的 TEE 路由节点和奖励数据所有者的贡献。在我们的测试网中,COVA Token由以太坊智能合约提供支持,以最大限度适应和易于开发。
理论上讲,TEE 是完全安全的,不过为了防止安全漏洞和攻击载体(比如 spectre、meltdown 和 foreshadowing)的影响,我们将最敏感信息的检索移动到路由节点共识上。我们的基本假设是,大多数节点是诚实的。此外,如果任何节点是不诚实的,我们可以使用多数共识中找到的信息立即检测到这类节点。在这种情况下,该路由节点将完全丧失其大量押金,并且特定CPU(由唯一的 CPUID 标识)和该路由节点所有者将被禁止进入网络。
在计算节点这一侧,虽然很难在不重新运行整个计算的情况下计算整个输出,但我们在路由节点和数据使用者中都有一个验证阶段。为了简单起见,如果我们假设一个参与者是恶意的(手段:破坏 TEE enclave)的独立概率是 ε,那么对于 k 方验证,所有这些都是恶意的概率是 εᵏ,ε 本身就是一个很小的数,εᵏ 值就更小了。
虽然用户冒着押金(或法律行动)风险以获得一些缩放数据集或不正确的计算以获得小额计算奖励的动机相当小,但我们还是严阵以待,并且使用各种随机验证器来确保安全。
第七层:数据使用界面
数据使用界面是一个简单的界面,允许数据使用者在启动与数据所有者的智能合约时运行一些自定义代码(策略允许)。此部分的实现细节将留给协议用户或 dApp builder。目前,数据使用者可以编写 python 代码,这些代码将由 Centrifuge 和 CovaVM 验证。
代码在 TEE 中运行完毕后,TEE 将缩放的计算值返回给数据使用者,路由节点提供最多 100 个由矢量 v 构成的秘密位,数据使用者可以运用 Shamir 的秘密共享方案组合生成矢量 v。为了完成数据分析和聚合计算,数据使用者可以通过导出的缩放矢量来找到在未缩放数据上训练的等效模型。例如:如果我们使用矢量 v 任何监督机器学习模型(Supervised Machine Learning Model)来缩放训练数据,则相当于在使用 Centrifuge 模型之前使用 v 缩放测试数据和预测。
最后
虽然这七层可能看起来令人很复杂,但与任何协议(如 HTTP 或 FTP)类似,最终用户只需要熟悉这个胖协议的第一层或第七层就可以。在接下来的深度文章中,我们将继续为大家解释各个层以及每层设置的各种激励。
















 工商网监
工商网监
评论