HBase分布式事务与SQL实现
大小:0.5 MB 人气: 2017-10-13 需要积分:1
目前看NewSQL代表未来(Google Spanner、F1、FoundationDB),HBase在国内有六个Committer,在目前主流的开源数据库里面几乎是最强的阵容。大家选型的时候会有一个犹豫,到底应该选择HBase还是选Cassandra。根据应用场景,如果需要一致性,HBase一定是你最好的选择,我推荐HBase。它始终保持强一致,我们非常喜欢一致性,丧失一致性的时候有些错误会特别诡异,很难查。对于Push-down特性的设计其实比较好,全局上是一个巨大的分布式数据库,但是逻辑上是分成了一个个Region,Region在哪台机器上是明确的。
比如要统计记录的条数,假设数据分布在整个系统里面,对数十亿记录做一个求和操作,就是说不同的机器上都要做一个sum,把条件告诉他要完成哪些任务,他给你任务你再汇总,这是典型的分布式的 MPP,做加速的时候是非常有效的。
2015年HBaseConf 上面有一句总结: “Nothing is hotter than SQL-on-Hadoop, and now SQL-on- HBase is fast approaching equal hotness status”, 实际上SQL-on-HBase 也是非常火。因为 Schema Less 没有约束其实是很吓人的一件事情,当然没有约束也比较爽,就是后期维护十分痛苦,规模进一步扩大了之后又需要迁移到 SQL。
现在无论从品质还是速度上要求已经越来越高,拥有SQL的同时还希望有ACID的东西(OLAP一般不追求一致性)。所以TiDB在设计时就强调这样的特点:始终保持分布式事务的支持,兼容MySQL协议。无数公司在SQL遇到Scale问题的时候很痛苦地做出了选择,比如迁移到HBase,Cassandra MongoDB已经看过太多的公司做这种无比痛苦的事情,现在不用痛苦了,直接迁过来,直接把数据导进来就OK了。TiDB最重要的是关注OLTP,对于互联网业务来说通常是在毫秒级内就需要返回一个结果。
我们到目前为止开发了六个月,开源了两个月。昨天晚上TiDB达到了第一个Alpha的阶段,现在可以拥有一个强大的数据库:支持分布式事务,始终保持同步的复制,强大的按需Scale能力,无阻塞的Schema变更。发布第一个Alpha版本的时候以前的质疑都会淡定下来,因为你可以阅读每一行代码,体验每个功能。选择这个领域也是非常艰难的决定,实在太Hardcore了,当初Google Spanner也做了5年。不过我们是真爱,我们就是技术狂,就是要解决问题,就是要挑大家最头痛的问题去解决。好在目前阿里的OceanBase给我们服了颗定心丸,大家也不会质疑分布式关系型数据库是否可行。
TiDB名字由来
为什么叫TiDB?大家起名字的时候特别喜欢用希腊神话里面的人物,但几乎所有的希腊神话人物的名字都被别的项目使用了,后来我们就找了化学元素周期表(理工科男与生俱来的特征),化学元素周期表里找到一个不俗且又能代表我们数据库特性的元素-Ti 。Ti是航空航天及航海里面很重要的设备都会用到的,特别稳定,也比较贵。
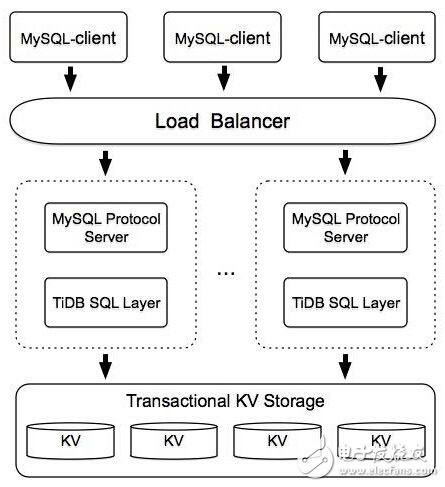
TiDB的系统架构图
TiDB怎么支持MySQL这个协议?这里会有一个协议解析层,它的作用就是去分析MySQL协议,转成内部可以识别的分发给自己的SQL Layer。当SQL Layer 拿到这个语句之后会把它拆成对应的分布式KV操作,所以这里会有一个Transactional KV Storage。接下来是在KV基础上增加事务的支持,再往上是普通的KV操作,理论上KV选什么都可以,如果选的是HBase有一个好处,它本身就是分布式,省掉分布式的工作。目前我们在小米的Themis基础上做了些优化和改进,和我们TiDB做了一个很好的结合。后期我们有一个计划,准备自己重写一套底层的分布式KV,把HBase换掉。因为HBase对于Container不友好,加上GC也是让人比较讨厌的问题,压力比较大的时候GC延迟会加长。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%