 德赢Vwin官网
App
德赢Vwin官网
App


人脸识别越来越流行,我们大多数人已经在使用它,甚至没有意识到它。无论是简单的 Facebook 标签建议、Snapchat 过滤器还是高级机场安全监控,人脸识别已经在其中发挥了魔力。中国已开始在学校使用人脸识别来监控学生的出勤和行为。零售店已开始使用人脸识别对其客户进行分类并隔离有欺诈历史的人。随着更多的变化正在进行中,毫无疑问,这项技术将在不久的将来随处可见。
在本教程中,我们将学习如何使用 Raspberry Pi 上的 OpenCV 库构建我们自己的人脸识别系统。将此系统安装在便携式 Raspberry Pi 上的优势在于,您可以将其安装在任何地方以将其用作监控系统。与所有人脸识别系统一样,本教程将涉及两个 python 脚本,一个是Trainer 程序,它将分析特定人的一组照片并创建一个数据集(YML 文件)。第二个程序是识别器程序它检测人脸,然后使用这个 YML 文件来识别人脸并提及人名。我们将在此处讨论的两个程序都适用于 Raspberry Pi (Linux),但也适用于 Windows 计算机,只需稍作改动。
如前所述,我们将使用 OpenCV 库来检测和识别人脸。因此,在继续本教程之前,请确保在 Pi 上安装 OpenCV 库。还要使用 2A 适配器为您的 Pi 供电,并通过 HDMI 电缆将其连接到显示器,因为我们将无法通过 SSH 获得视频输出。
人脸识别如何与 OpenCV 配合使用
在我们开始之前,重要的是要了解人脸检测和人脸识别是两个不同的东西。在人脸检测中,仅检测到一个人的脸,该软件将不知道该人是谁。在人脸识别中,软件不仅会检测人脸,还会识别人。现在,应该清楚我们需要在执行人脸识别之前执行人脸检测。我无法解释 OpenCV 是如何准确检测人脸或任何其他物体的。
来自网络摄像头的视频馈送只不过是一长串不断更新的静止图像。这些图像中的每一个都只是将不同值的像素放在各自的位置上的集合。那么程序如何从这些像素中检测出人脸并进一步识别其中的人呢?它背后有很多算法,试图解释它们超出了本文的范围,但由于我们使用的是 OpenCV 库,因此执行面部识别非常简单,无需深入了解概念
在 OpenCV 中使用级联分类器进行人脸检测
只有当我们能够检测到一张脸时,我们才能识别或记住它。为了检测诸如人脸之类的对象,OpenCV 使用了一种叫做分类器的东西。这些分类器是预先训练的数据集(XML 文件),可用于检测我们案例中的特定对象,即人脸。您可以在此处了解有关人脸检测分类器的更多信息。除了检测人脸,分类器还可以检测鼻子、眼睛、车牌、微笑等其他物体。
Python中对象检测的分类器
或者,OpenCV 还允许您创建自己的分类器,该分类器可用于通过训练级联分类器来检测图像中的任何其他对象。在本教程中,我们将使用一个名为“haarcascade_frontalface_default.xml”的分类器,它将从正面位置检测人脸。我们将在编程部分看到更多关于如何使用分类器的信息。
安装所需的软件包
确保已安装 pip,然后继续安装以下软件包。
安装dlib: Dlib 是一个用于现实世界机器学习和数据分析应用程序的工具包。要安装 dlib,只需在终端中输入以下命令
点安装 dlib
这应该会安装dlib,成功后您将看到这样的屏幕。
安装枕头:枕头也称为 PIL 代表 Python Imaging Library,用于以不同格式打开、操作和保存图像。要安装 PIL,请使用以下命令
点安装枕头
安装后,您将收到一条成功消息,如下所示
安装 face_recognition: python 的 face_recognition 库被认为是识别和操作人脸的最简单的库。我们将使用这个库来训练和识别人脸。要安装这个库,请按照命令
pip install face_recognition –no –cache-dir
成功安装后,您应该会看到如下所示的屏幕。该库很重,大多数人会面临内存超出问题,因此我使用“--no –cache-dir”代码安装库而不保存缓存文件。
面部训练师计划
让我们看一下Face_Traineer.py程序。该程序的目标是打开Face_Images目录中的所有图像并搜索人脸。一旦检测到人脸,它会裁剪人脸并将其转换为灰度,然后转换为 numpy 数组,然后我们最终使用我们之前安装的face_recognition库来训练并将其保存为名为face-trainner.yml的文件。此文件中的数据稍后可用于识别人脸。最后给出了完整的 Trainer 程序,这里将解释最重要的几行。
我们通过导入所需的模块开始程序。cv2 模块用于图像处理,numpy 用于将图像转换为数学等价物,os模块用于导航目录,PIL 用于处理图像。
import cv2 #用于图像处理 import numpy as np #用于将图像转换为数值数组 import os #用于处理 来自 PIL 的目录 import Image #用于处理图像的枕头库
接下来我们必须使用 haarcascade_frontalface_default.xml 分类器来检测图像中的人脸。确保您已将此 xml 文件放在项目文件夹中,否则您将面临错误。然后我们使用识别器变量来创建局部二进制模式直方图 (LBPH) 人脸识别器。
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
识别器 = cv2.createLBPHFaceRecognizer()
然后我们必须进入Face_Images目录才能访问其中的图像。该目录应放在您当前的工作目录 (CWD) 中。以下行用于进入放置在 CWD 中的文件夹。
Face_Images = os.path.join(os.getcwd(), "Face_Images") #告诉程序我们将人脸图像保存在哪里
然后我们使用for循环进入目录Face_Images的每个子目录并打开任何以 jpeg、jpg 或 png 结尾的文件。每个图像的路径存储在一个名为 path 的变量中,而放置图像的文件夹名称(将是人名)存储在一个名为person_name的变量中。
for root, dirs, files in os.walk(Face_Images): #转到人脸图像目录
for file in files: #检查其中的每个目录
if file.endswith("jpeg") or file.endswith("jpg") or file.endswith("png"): #对于以jpeg,jpg or png结尾的图片文件
路径 = os.path.join(根,文件)
person_name = os.path.basename(root)
如果这个人的名字发生了变化,我们会增加一个名为Face_ID的变量,这将有助于我们为不同的人拥有不同的Face_ID,我们稍后将使用它来识别这个人的名字。
if pev_person_name!=person_name: #检查人名是否改变 Face_ID=Face_ID+1 #如果是则增加ID计数 pev_person_name = person_name
正如我们所知,OpenCV 处理灰度图像比处理彩色图像要容易得多,因为可以忽略 BGR 值。因此,为了减少图像中的值,我们将其转换为灰度,然后将图像大小调整为 550,以使所有图像保持一致。确保图像中的脸部位于中间,否则脸部将被裁剪掉。最后将所有这些图像转换为 numpy 数组以获得图像的数学值。然后使用级联分类器检测图像中的人脸,并将结果存储在一个名为faces的变量中。
Gery_Image = Image.open(path).convert("L") # 使用 Pillow
Crop_Image = Gery_Image.resize( (550,550) , Image.ANTIALIAS) 将图像转换为灰度图 #Crop the Gray Image to 550*550 (确保你的face is in center in all image)
Final_Image = np.array(Crop_Image, "uint8")
faces = face_cascade.detectMultiScale(Final_Image, scaleFactor=1.5, minNeighbors=5) #检测所有样本图像中的人脸
一旦检测到人脸,我们将裁剪该区域并将其视为我们的感兴趣区域 (ROI)。ROI 区域将用于训练人脸识别器。我们必须将每个 ROI 面附加到一个名为x_train的变量中。然后我们将这个 ROI 值与 Face ID 值一起提供给识别器,识别器将为我们提供训练数据。这样获得的数据将被保存
for (x,y,w,h) in faces:
roi = Final_Image[y:y+h, x:x+w] #crop the Region of Interest (ROI)
x_train.append(roi)
y_ID.append(Face_ID)
识别器.train(x_train, np.array(y_ID)) #创建训练数据矩阵
识别器.save("face-trainner.yml") #将矩阵保存为YML文件
当你编译这个程序时,你会发现face-trainner.yml文件每次都会更新。因此,每当您对Face_Images目录中的照片进行任何更改时,请务必编译此程序。编译后,您将获得打印的人脸 ID、路径名、人名和 numpy 数组,如下所示,用于调试目的。
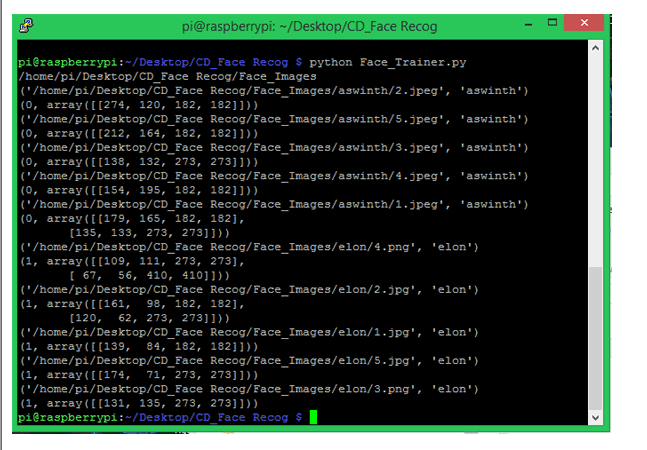
人脸识别程序
现在我们已经准备好经过训练的数据,我们现在可以使用它来识别人脸了。在人脸识别程序中,我们将从 USB 网络摄像头获取实时视频,然后将其转换为图像。然后我们必须使用我们的人脸检测技术来检测这些照片中的人脸,然后将其与我们之前创建的所有人脸 ID 进行比较。如果我们找到匹配项,我们就可以将脸部框起来并写下已识别的人的姓名。最后再次给出完整的程序,解释如下。
该程序与训练程序有很多相似之处,因此导入我们之前使用的相同模块并使用分类器,因为我们需要再次执行人脸检测。
import cv2 #用于图像处理 import numpy as np #用于将图像转换为数值数组 import os #用于处理 来自 PIL 的目录 import Image #用于处理图像的枕头库
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
识别器 = cv2.createLBPHFaceRecognizer()
接下来在变量标签中,您必须写下文件夹中提到的人员的姓名。确保您遵循相同的顺序。就我而言,我的名字是“Aswinth”和“Elon”。
标签 = [“阿斯温斯”,“埃隆马斯克”]
然后我们必须将face-trainner.yml文件加载到我们的程序中,因为我们必须使用该文件中的数据来识别人脸。
识别器.load("face-trainner.yml")
视频源是从USB 网络摄像头获得的。如果您连接了多个摄像头,请将 0 替换为 1 以访问辅助摄像头。
cap = cv2.VideoCapture(0) #从摄像头获取视频源
接下来,我们将视频分解为帧(图像)并将其转换为灰度,然后检测图像中的人脸。一旦检测到人脸,我们必须像之前一样裁剪该区域并将其单独保存为roi_gray。
ret, img = cap.read() # 将视频分成帧 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #convert Video frame to Greyscale faces = face_cascade.detectMultiScale(gray, scaleFactor=1.5, minNeighbors=5) #Recog . faces for (x, y, w, h) in faces: roi_gray = gray[y:y+h, x:x+w] #Convert Face to grayscale id_, conf = Recognizer.predict(roi_gray) #recognize the Face
变量conf告诉我们软件识别人脸的信心。如果置信度大于 80,我们使用下面的代码行获取使用 ID 号的人的姓名。然后在人的脸上画一个框,在框的顶部写下人的名字。
if conf>=80:
font = cv2.FONT_HERSHEY_SIMPLEX #名称的字体样式
name = labels[id_] #使用ID号从List中获取名称
cv2.putText(img, name, (x,y), font, 1 , (0,0,255), 2)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
最后,我们必须显示我们刚刚分析的视频源,然后在按下等待键(此处为 q)时中断源。
cv2.imshow('Preview',img) #显示视频
if cv2.waitKey(20) & 0xFF == ord('q'):
break
执行此程序时,请确保 Pi 通过 HDMI 连接到显示器。运行程序,您会发现弹出一个窗口,其中包含名称预览和您的视频源。如果在视频提要中识别出一张脸,您会在它周围找到一个框,如果您的程序可以识别这张脸,它也会显示该人的姓名。我们已经训练了我们的程序来识别我自己和埃隆马斯克,你可以在下面的快照中看到他们都被识别了。
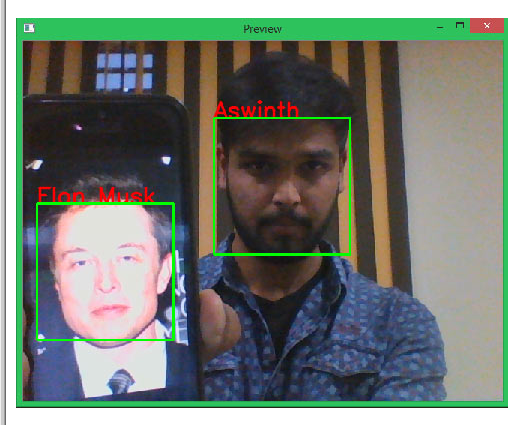
曾经值得注意的问题是帧速率非常慢。我每 3 秒就会变得像一帧。在我的笔记本电脑上执行相同的程序(稍作改动)给了我非常令人印象深刻的结果。也不要期望它非常准确,我们的培训师数据非常简单,因此程序不会很可靠。您可以查看如何使用深度学习来训练您的数据集以提高准确性。有一些方法可以提高 FPS(每秒帧数),但让我们将其留给另一个教程。
实时人脸识别程序
#基于 face-trainner.yml 的数据检测人脸并识别人的程序
import cv2 #用于图像处理
import numpy as np #用于将图像转换为数值数组
import os #处理目录
from PIL import Image #Pillow lib 用于处理图像
标签 = [“阿斯温斯”,“埃隆马斯克”]
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
识别器 = cv2.createLBPHFaceRecognizer()
识别器.load("face-trainner.yml")
cap = cv2.VideoCapture(0) #从摄像头获取视频源
而(真):
ret, img = cap.read() # 将视频分成帧
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #将视频帧转换为灰度
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.5, minNeighbors=5) #Recog。面孔
对于面中的 (x, y, w, h):
roi_gray = gray[y:y+h, x:x+w] #将人脸转灰度
id_, conf = Recognizer.predict(roi_gray) #recognize the Face
如果 conf>=80:
font = cv2.FONT_HERSHEY_SIMPLEX #名称的字体样式
name = labels[id_] #使用ID号从List中获取名字
cv2.putText(img, name, (x,y), font, 1, (0,0,255), 2)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('Preview',img) #显示视频
如果 cv2.waitKey(20) & 0xFF == ord('q'):
休息
# 一切完成后,释放捕获
帽释放()
cv2.destroyAllWindows()
人脸检测培训师计划
#Program 用于训练人脸并创建 YAML 文件
import cv2 #用于图像处理
import numpy as np #用于将图像转换为数值数组
import os #处理目录
from PIL import Image #Pillow lib 用于处理图像
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
识别器 = cv2.createLBPHFaceRecognizer()
Face_ID = -1
pev_person_name = ""
y_ID = []
x_train = []
Face_Images = os.path.join(os.getcwd(), "Face_Images") #告诉程序我们将人脸图像保存在哪里
打印(Face_Images)
for root, dirs, files in os.walk(Face_Images): #进入人脸图片目录
for file in files: #检查其中的每个目录
if file.endswith("jpeg") or file.endswith("jpg") or file.endswith("png"): #对于以jpeg,jpg or png结尾的图片文件
路径 = os.path.join(根,文件)
person_name = os.path.basename(root)
打印(路径,人名)
if pev_person_name!=person_name: #检查人名是否改变
Face_ID=Face_ID+1 #如果是则增加ID计数
pev_person_name = 人名
Gery_Image = Image.open(path).convert("L") # 使用 Pillow 将图像转换为灰度图
Crop_Image = Gery_Image.resize( (550,550) , Image.ANTIALIAS) #将灰度图像裁剪为550*550(确保你的脸在所有图像的中心)
Final_Image = np.array(Crop_Image, "uint8")
#print(Numpy_Image)
faces = face_cascade.detectMultiScale(Final_Image, scaleFactor=1.5, minNeighbors=5) #检测所有样本图像中的人脸
打印(Face_ID,面孔)
对于面中的 (x,y,w,h):
roi = Final_Image[y:y+h, x:x+w] #裁剪感兴趣区域(ROI)
x_train.append(roi)
y_ID.append(Face_ID)
识别器.train(x_train, np.array(y_ID)) #创建训练数据矩阵
识别器.save("face-trainner.yml") #将矩阵保存为YML文件












 工商网监
工商网监
评论