 XIlinx利用HLS进行加速设计进度
XIlinx利用HLS进行加速设计进度
据观察,HLS的发展呈现愈演愈烈的趋势,随着Xilinx Vivado HLS的推出,intel也快马加鞭的推出了其HLS工具。HLS可以在一定程度上降低FPGA的入门门槛(不用编写RTL代码),也可以在某些场合加速设计与验证(例如在FPGA上实现OpenCV函数),但个人还是喜欢直接从RTL入手,这样可以更好的把握硬件结构。Xilinx官方文档表示利用HLS进行设计可以大大加速设计进度:

XIlinx官方文档片段
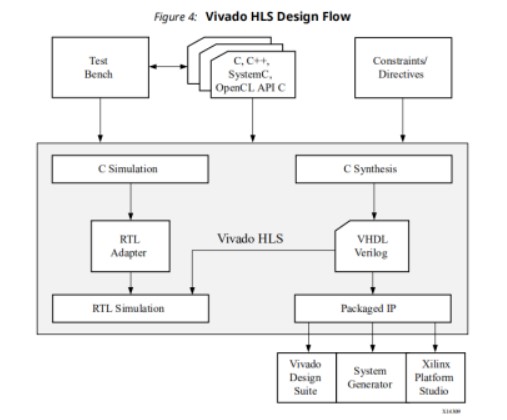
所以为了紧随时代潮流,所以也抽空玩了一下Xilinx的HLS工具,下面把整个过程分享给大家。我这里选择Cordic算法作为我的实现目标。Cordic算法原理很简单,所以这里不再赘述。首先介绍一下Vivado HLS设计流程:
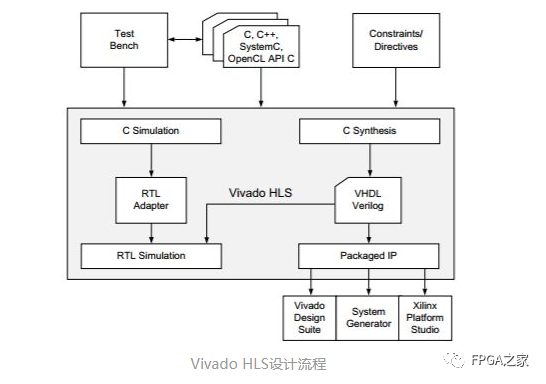
Vivado HLS设计流程
可以看出我们需要做的是完成C/C++设计、Testbench编写以及Constraints/directives的添加。其中Constraints/directives是指利用约束/指令使HLS综合出的RTL代码更符合要求。接着,我们就可以利用HLS进行C层仿真与验证、C/RTL混合仿真与验证以及RTL代码的生成与打包。综上,HLS设计的主要工作内容包括三点:C/C++设计、Testbench设计以及约束的添加。下面就从这三点开始介绍。
一. Cordic算法的C++实现
算法头文件Cordic.h代码如下:
#include
头文件的重点是声明数据类型。这里采用HLS中特有的定点数形式,包含ap_fixed.h与ap_int.h即可。由于输入为有符号弧度制(-3.1415~+3.1415),输出为-1~+1,所以定义两种数据精度:
di_t :17bits = 1bit符号位 + 2bit整数 + 14bit小数
do_t:16bits = 1bit符号位 + 1bit整数 + 14bit小数
接着声明了函数与两个算法所需参数。
算法文件Cordic.cpp代码如下(注意:由于使用C++头文件ap_fixed.h,所以必须采用.cpp文件,否则编译出错):
#include"Cordic.h"void pre_cir_cordic(di_t full_alpha, di_t &alpha, flag_t &flag){ if(full_alpha > PI/2) { alpha = PI - full_alpha; flag = 2; } else if(full_alpha < -PI/2) { alpha = -PI - full_alpha; flag = 3; } else { alpha = full_alpha; flag = 0; }}void cir_cordic_calculate(di_t alpha, flag_t flag, do_t &mysin, do_t &mycos, flag_t &flag_delay){ const int N = 15; do_t xi[N]; do_t yi[N]; di_t zi[N]; flag_t flag_delay_a[N]; xi[0] = Kn; yi[0] = 0; zi[0] = alpha; flag_delay_a[0] = flag; const di_t myarctan[15] = { 0.7853981, 0.4636476, 0.2449787, 0.1243549, 0.0624188, 0.0312398, 0.0156237, 0.0078123, 0.0039062, 0.0019531, 0.0009765, 0.0004883, 0.0002441, 0.0001221, 0.0000610 }; int m = 0; for(m = 0; m
算法主要有三个函数组成:
1.pre_cir_cordic:将输入角度从-π~+π映射到 -π/2~+π/2中。
2.cir_cordic_calculate:利用旋转公式进行Cordic算法计算,这里设置旋转次数为15次,精度较高。
3.post_cir_cordic:根据输入角度矫正输出值正负。
最后,通过cir_cordic函数实现上述三个函数的整合。至此,Cordic算法的C++设计结束。
二. Testbench设计
为了验证设计的正确性,需要编写Testbench对C++代码以及综合后的RTL进行测试。本文的Testbench.cpp代码如下:
#include "Cordic.h"#include
本测试平台利用随机数生成-π~+π的测试向量对程序进行测试。以math.h中的三角函数作为评判标准。为了缩短时间,选择100组测试向量进行测试,若算法误差大于给定值,则报错;若算法误差均小于给定值,则输出验证通过信息。C验证平台设计完成。
三. 验证与directives的添加
1.初步算法的C仿真与综合
根据上述代码,可以对工程进行C仿真,仿真结果如下:
C仿真结果
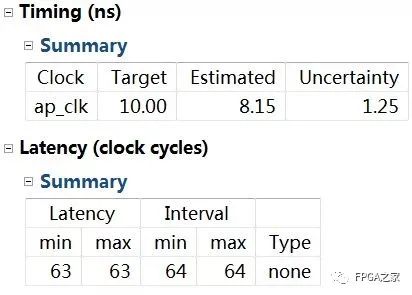
可以看出C仿真通过,算法正确。接着综合工程,得到综合结果如下:
C综合报告
可以看出代码时钟符合要求,但是Latency(延迟)和Interval(吞吐量倒数)较大。此时吞吐量较小,64个时钟输出一个计算结果,并没有发挥FPGA的并行优势,所以需要添加Directives对工程综合进行约束。
2.Directives添加
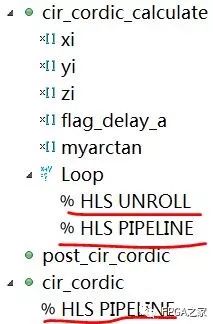
由于Cordic算法中旋转公式部分为循环,所以将循环展开并加入流水线可以大大减小延时以及增加吞吐量。同时也对计算函数加入流水线以提高吞吐量。建立一个新的solution:Add_Directives,其Directive添加结果如下:
Directive添加结果
此时再对算法进行综合,得到综合报告对比如下:
综合报告对比
可以看出添加Directives后,吞吐量大大提高,已经达到最大值,即每个时钟都输出一个计算结果。算法延时也从63个clk减小到4个clk,此时RTL代码已经较为理想。
3.C/RTL联合仿真
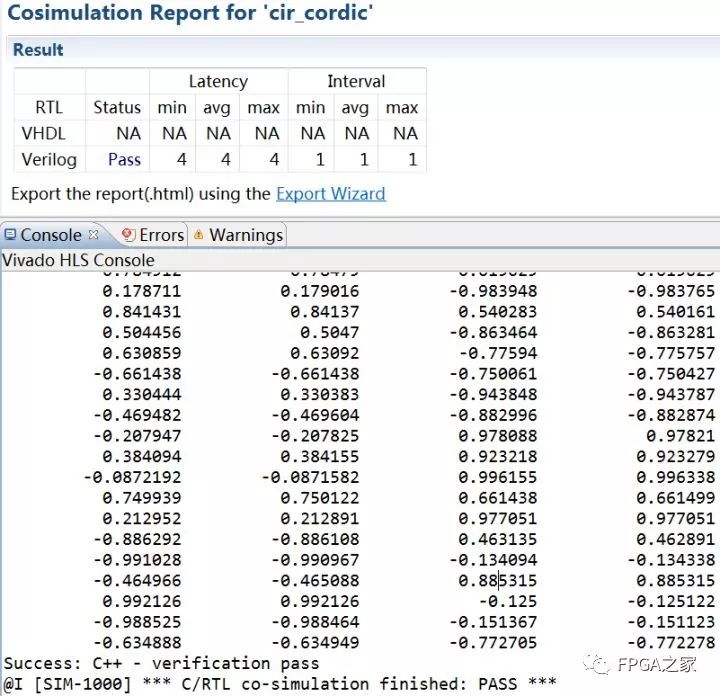
由上,代码设计部分与约束添加已经全部完成,下面进行联合仿真,对RTL代码进行验证。验证报告如下:
混合仿真报告
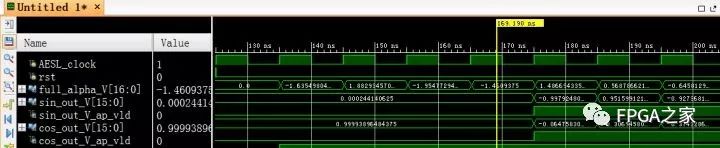
可以看出RTL仿真与C仿真均通过,说明设计正确。利用Vivado simulator打开RTL仿真波形,如下:
RTL仿真波形
可以看出RTL波形中明显体现出4 clk的Latency和1 clk的Interval,并且利用计算器进行验算,证明计算结果正确,所以RTL代码综合成功。
四. IP打包
直接利用HLS进行IP打包即可生成IP核。在相应工程中引入IP核路径(在对应solution内的impl文件夹内)即可调用HLS生成的IP核。本IP核接口如下:
Cordic IP
那么根据上节仿真波形进行接口输入的描述就可以使用该IP。至此,整个HLS设计过程结束。
五. 总结
整个HLS设计过程还是比较清晰的,重点在于了解HLS的支持范围以编写符合规范的高层次代码,其次是对硬件有一定认识以引入合适的directives。HLS的确在很大程度上加快了设计进度,使用也非常方便,所以我以后决定还是从RTL层面进行设计,因为那样觉得自己更NB一点。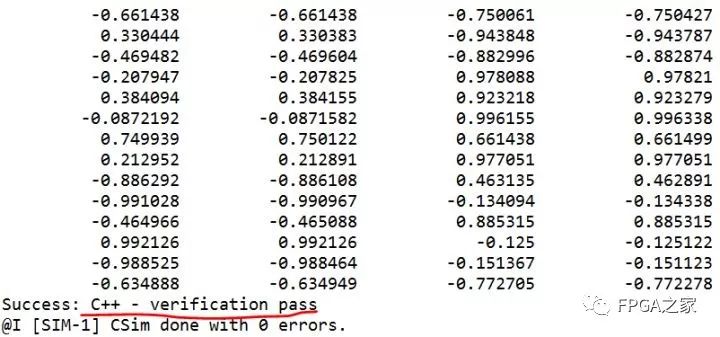


-
RTL
+关注
关注
1文章
385浏览量
59759 -
HLS
+关注
关注
1文章
129浏览量
24097
原文标题:利用Xilinx HLS将C++代码快速部署于FPGA(Cordic算法)
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Vivado HLS视频库加速Zynq-7000 All Programmable SoC OpenCV应用
熟悉Vivado HLS基本功能要多少时间?
嵌入式硬件开发学习教程——Xilinx Vivado HLS案例 (流程说明)
嵌入式HLS 案例开发步骤分享——基于Zynq-7010/20工业开发板(4)
嵌入式HLS 案例开发步骤分享——基于Zynq-7010/20工业开发板(3)
嵌入式HLS 案例开发步骤分享——基于Zynq-7010/20工业开发板(3)
嵌入式HLS 案例开发步骤分享——基于Zynq-7010/20工业开发板(4)
【KV260视觉入门套件试用体验】硬件加速之—使用PL加速矩阵乘法运算(Vitis HLS)
关于ZYNQ HLS图像处理加速总结的分享
利用Vivado HLS加速运行慢的软件
利用Vitis HLS tcl shell一键跑通视觉加速例程
基于Vitis HLS的加速图像处理





 工商网监
工商网监
评论