 大数据计算引擎,你pick哪个?
大数据计算引擎,你pick哪个?
不知道你是否有过和我类似的经历?
我是 2018 年 6 月加入公司,一直负责监控平台的告警系统。之后,我们的整个监控平台架构中途换过两次,其中一次架构发生了巨大的变化。我们监控告警平台最早的架构如下图所示:
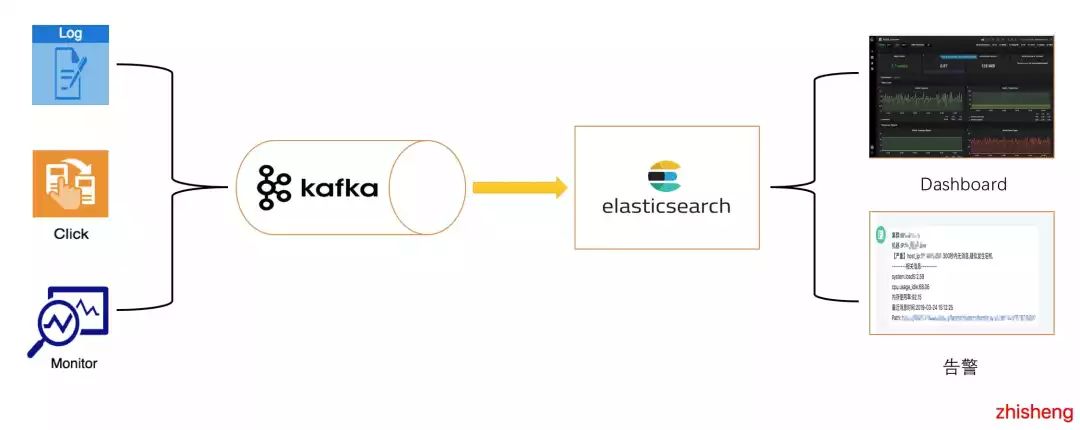
这个架构的挑战难点在于:
海量的监控数据(Metric & Log & Trace 数据)实时写入 ElasticSearch;
多维度的监控指标页面展示(Dashboard) 查 ElasticSearch 的数据比较频繁;
不断递增的告警规则需要通过查询 ElasticSearch 数据来进行判断是否要告警。
从上面的几个问题我们就可以很明显的发现这种架构的瓶颈就在于 ElasticSearch 集群的写入和查询能力,在海量的监控数据(Metric & Log & Trace 数据)下实时的写入对 ElasticSearch 有极大的影响。 我依然清楚记得,当时经常因为写入的问题导致 ElasticSearch 集群挂掉,从而让我的告警和监控页面(Dashboard)歇菜(那会老被喷:为啥配置的告警规则没有触发告警?为啥查看应用的 Dashboard 监控页面没数据)。我也很无奈啊,只想祈祷我们的 ElasticSearch 集群稳一点。
01
初次接触 Flink
在如此糟糕的架构情况下,我们挺过了几个月,后面由于一些特殊的原因,我们监控平台组的整体做了一个很大的架构调整,如下图:
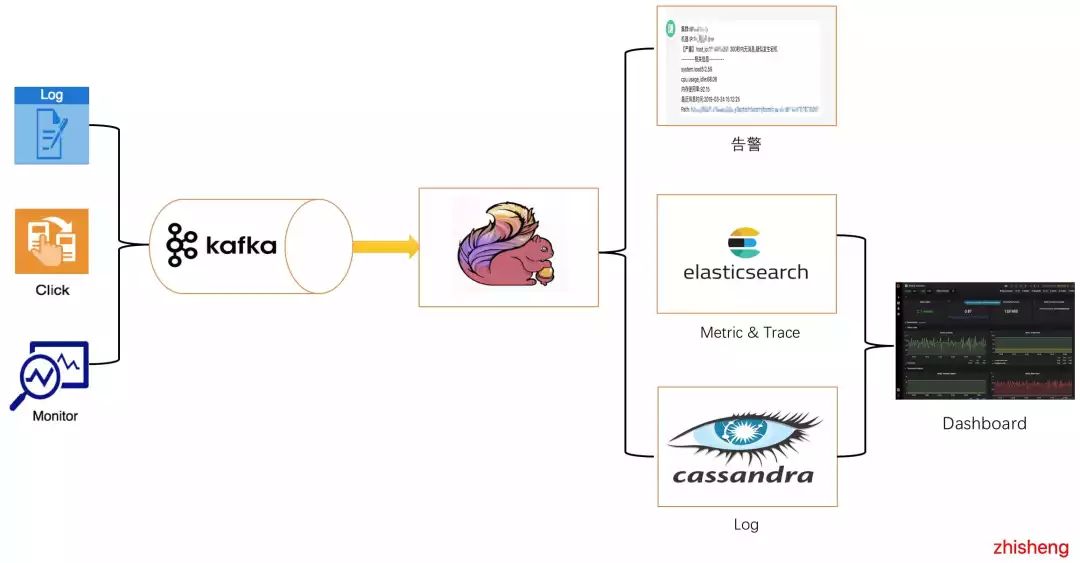
主要做了四点改变:
接入 Flink 集群去消费 Kafka 数据,告警的 Flink Job 消费 Kafka 数据去判断异常点,然后做告警
Metric & Trace 数据存储到 ElasticSearch,之前还存储在 ElasticSearch 中的有 Log 数据
Log 数据存储到 Cassandra
Dashboard 查询数据增加 API 查询 Cassandra 的日志数据
原先因为 Metric & Trace & Log 的数据量一起全部实时写入到 ElasticSearch 中,对 ElasticSearch 的压力很大,所以我们将 Log 的数据拆分存储到 Cassandra 中,分担了一些 ElasticSearch 的写入压力。 但是过后我们发现偶尔还会出现数据实时写入到 ElasticSearch 集群把 ElasticSearch 写挂的情况。所以那会不断调优我们的写入数据到 ElasticSearch 的 Flink Job,然后也对 ElasticSearch 服务端做了不少的性能调优。 另外那会我们的监控数据是以 10s 一次为单位将采集的数据发上来的,后面我们调整了下数据采集的策略(变成 30s 一次为单位采集数据),采取多种调优策略后,终于将我们的 ElasticSearch 弄稳定了。
02
遇到 Flink 相关的挑战
替换成这种新架构后,由于组里没人熟悉 Flink,再加上那会儿 Flink 的资料真的很少很少,所以当时在组里对 Flink 这块大家都是从 0 开始学习,于大家而言挑战还挺大的。
那时候我们跑在 Flink 上面的 Job 也遇到各种各样的问题:
消费 Kafka 数据延迟
checkpoint 失败
窗口概念模糊、使用操作有误
Event Time 和 Processing Time 选择有误
不知道怎么利用 Watermark 机制来处理乱序和延迟的数据
Flink 自带的 Connector 的优化
Flink 中的 JobManager 和 TaskManager 经常挂导致 Flink Job 重启
Flink 集群模式的选型
...
因为碰到的各种各样的问题,所以才会促使我们不断地学习 Flink 的原理和内部机制,然后慢慢去解决上面遇到的各种问题,并逐步稳定我们监控平台运行的 Flink Job。
03
为什么要学习 Flink?
随着大数据的不断发展,对数据的及时性要求越来越高,实时场景需求也变得越来越多,主要分下面几大类:
那么为了满足这些实时场景的需求,衍生出不少计算引擎框架,现有市面上的大数据计算引擎的对比如下:
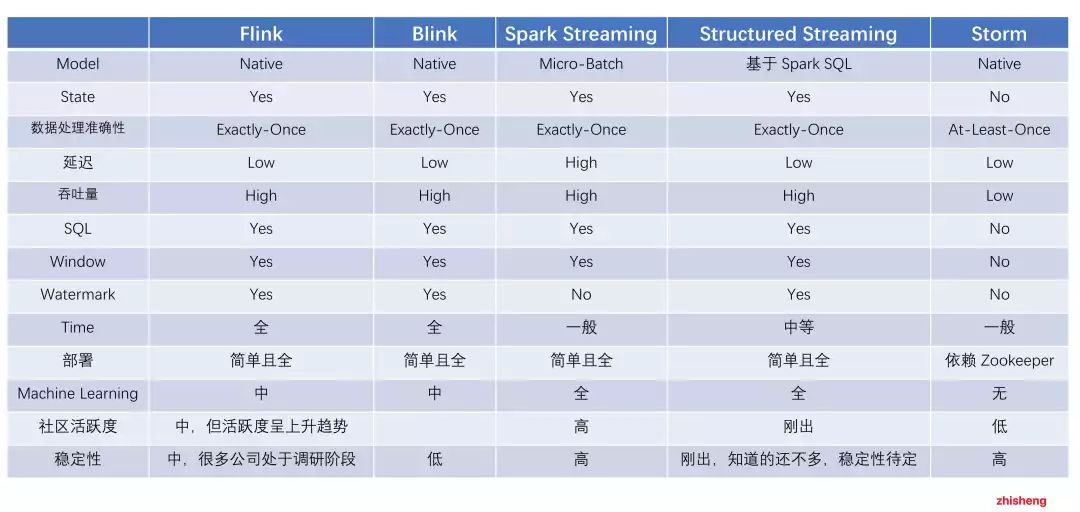
可以发现无论从 Flink 的架构设计上,还是从其功能完整性和易用性来讲都是领先的,再加上Flink 是阿里巴巴主推的计算引擎框架,所以从去年开始就越来越火了! 虽然市面上讲 Flink 的太少太少,国内的中文资料太欠缺,已有的几本书籍也不甚详尽,但是国内在阿里的推动下,我相信 Flink 会越来越火的,并且阿里内部也将 Flink 做了一定的优化和修改,叫 Blink,今年年初也将源码贡献到 Flink 上面,后面在 Flink 1.9 版本会将 Blink 的功能进行合并到 Flink 上去。 目前,阿里巴巴、腾讯、美团、华为、滴滴出行、携程、饿了么、爱奇艺、有赞、唯品会等大厂都已经将 Flink 实践于公司大型项目中,带起了一波 Flink 风潮,势必也会让 Flink 人才市场产生供不应求的招聘现象。
04
我为什么要写 FLink 专栏?
在这个过程中我持续记录自己的 Flink 学习之路,目前已经对外公布了 20+ 篇 Flink 的个人学习博客,同时好多对 Flink 感兴趣的童鞋也加我一起讨论问题。 每天群里的童鞋会提很多遇到的 Flink 问题,但是我发现得到的回答比较少,其实这并不是因为群里大佬不活跃,而是因为大家对 Flink 的了解还不是很多,比如有的是大数据工程师但之前是搞 Spark 这块的,有的是转大数据开发的后端开发工程师,有的是对 Flink 这块比较感兴趣的研究生等。 因为自己就是从 Flink 小白过来的,所以知道初学者可能会遇到的哪些问题。当你回首的时候,你可能会发现,这么简单的问题自己当时那么费力地折腾了半天都出不来。这种时候要是有人指点一下,可以节省多少功夫啊! 所以自己在心里萌生了一个想法:写一个 Flink 专栏帮助大家尽快地从小白阶段过渡到入门阶段,然后再从入门到能够将 Flink 用上,在生产环境真正把你的 Flink Job 运行起来,再做到能够根据你生产环境出现的错误进行排查并解决,还能根据你的 Job 的运行状况进一步优化!
专栏亮点
全网首个使用最新版本 Flink 1.9 进行内容讲解(该版本更新很大,架构功能都有更新),领跑于目前市面上常见的 Flink 1.7 版本的教学课程。
包含大量的实战案例和代码去讲解原理,有助于读者一边学习一边敲代码,达到更快,更深刻的学习境界。目前市面上的书籍没有任何实战的内容,还只是讲解纯概念和翻译官网。
在专栏高级篇中,根据 Flink 常见的项目问题提供了排查和解决的思维方法,并通过这些问题探究了为什么会出现这类问题。
在实战和案例篇,围绕大厂公司的经典需求进行分析,包括架构设计、每个环节的操作、代码实现都有一一讲解。
专栏内容
预备篇
介绍实时计算常见的使用场景,讲解 Flink 的特性,并且对比了 Spark Streaming、Structured Streaming 和 Storm 等大数据处理引擎,然后准备环境并通过两个 Flink 应用程序带大家上手 Flink。
基础篇
深入讲解 Flink 中 Time、Window、Watermark、Connector 原理,并有大量文章篇幅(含详细代码)讲解如何去使用这些 Connector(比如 Kafka、ElasticSearch、HBase、Redis、MySQL 等),并且会讲解使用过程中可能会遇到的坑,还教大家如何去自定义 Connector。
进阶篇
讲解 Flink 中 State、Checkpoint、Savepoint、内存管理机制、CEP、Table/SQL API、Machine Learning 、Gelly。在这篇中不仅只讲概念,还会讲解如何去使用 State、如何配置 Checkpoint、Checkpoint 的流程和如何利用 CEP 处理复杂事件。
高级篇
重点介绍 Flink 作业上线后的监控运维:如何保证高可用、如何定位和排查反压问题、如何合理的设置作业的并行度、如何保证 Exactly Once、如何处理数据倾斜问题、如何调优整个作业的执行效率、如何监控 Flink 及其作业?
实战篇
教大家如何分析实时计算场景的需求,并使用 Flink 里面的技术去实现这些需求,比如实时统计 PV/UV、实时统计商品销售额 TopK、应用 Error 日志实时告警、机器宕机告警。这些需求如何使用 Flink 实现的都会提供完整的代码供大家参考,通过这些需求你可以学到 ProcessFunction、Async I/O、广播变量等知识的使用方式。
系统案例篇
讲解大型流量下的真实案例:如何去实时处理海量日志(错误日志实时告警/日志实时 ETL/日志实时展示/日志实时搜索)、基于 Flink 的百亿数据实时去重实践(从去重的通用解决方案 --> 使用 BloomFilter 来实现去重 --> 使用 Flink 的 KeyedState 实现去重)。
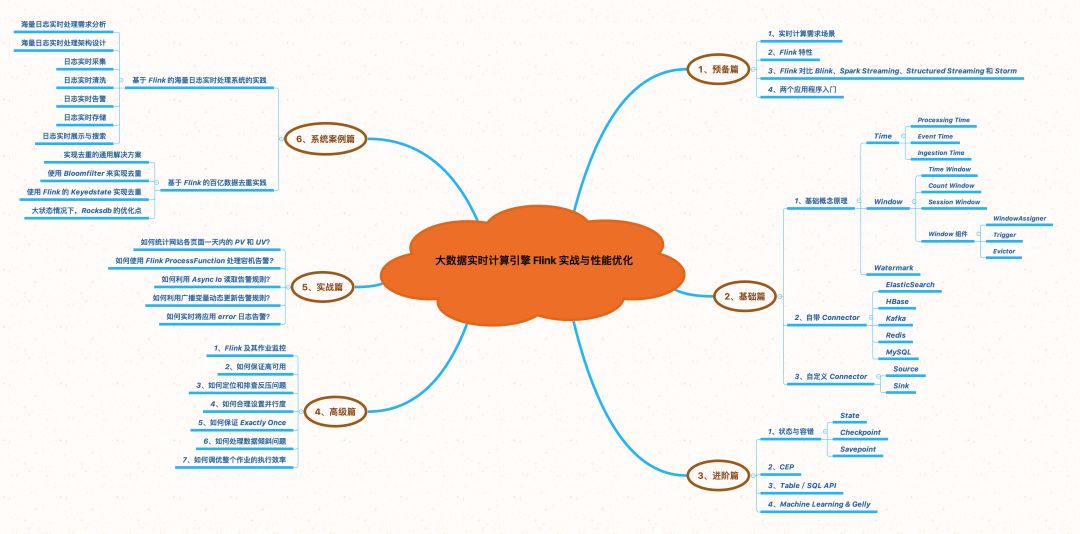
▲Flink 专栏思维导图
多图讲解 Flink 知识点
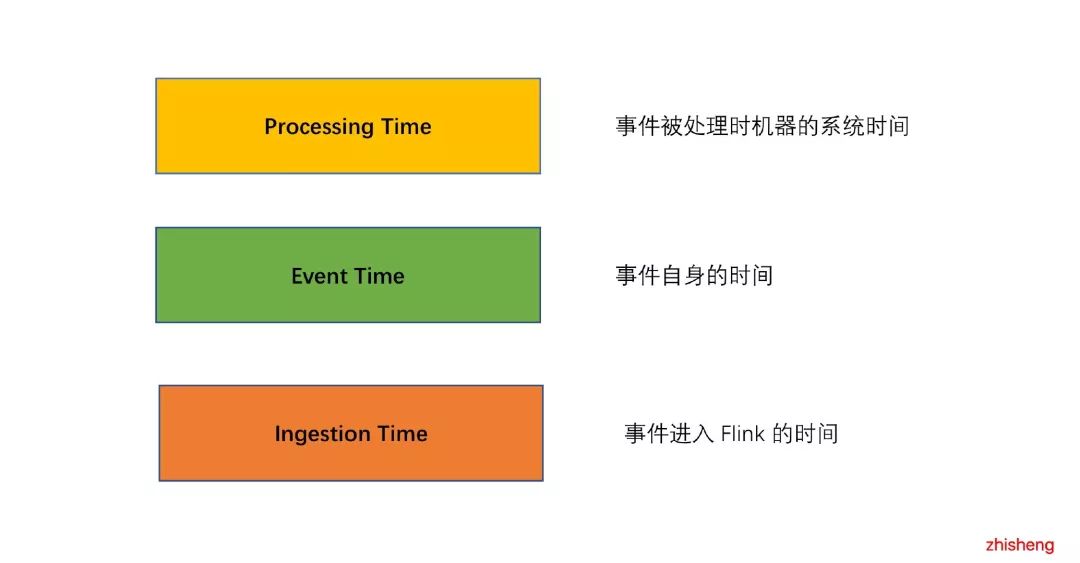
▲Flink 支持多种时间语义
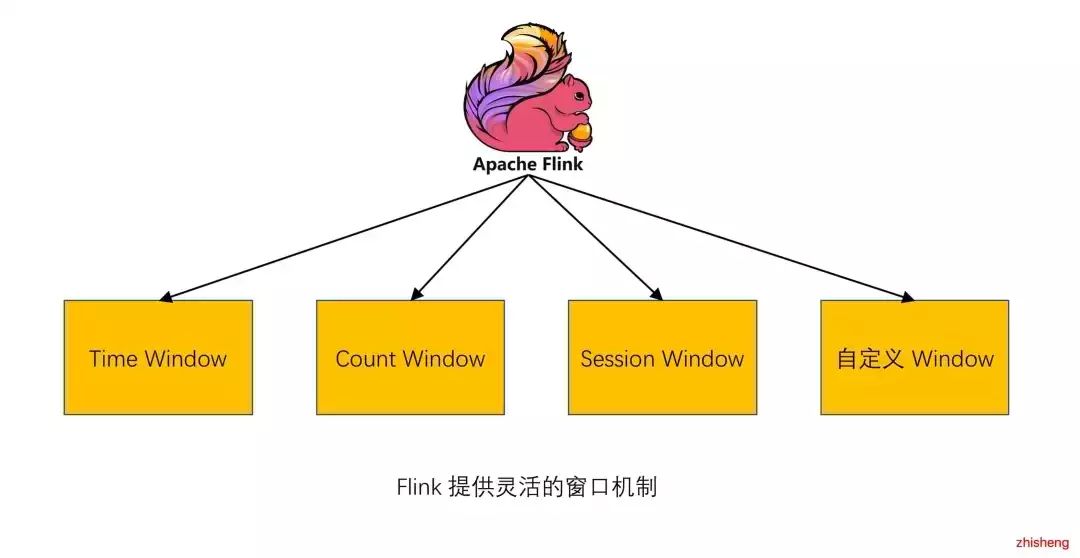
▲Flink 提供灵活的窗口

▲Flink On YARN
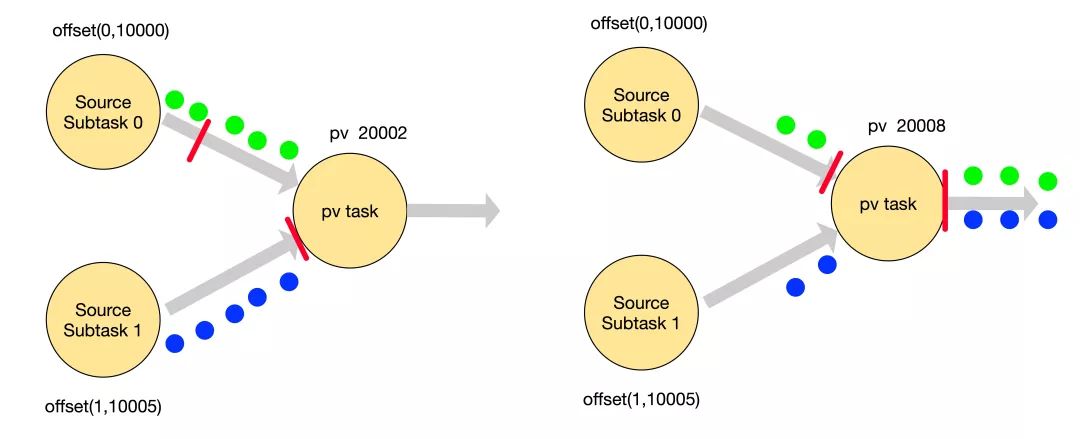
▲Flink Checkpoint

▲Flink 监控
-
监控平台
+关注
关注
0文章
28浏览量
8515 -
大数据
+关注
关注
64文章
8882浏览量
137391
原文标题:大数据计算引擎,你 pick 哪个?
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
缓存对大数据处理的影响分析
使用 AMD Versal AI 引擎释放 DSP 计算的潜力
ADS1675最大数据吞吐率是是多少?
人工智能云计算大数据三者关系
智慧城市与大数据的关系
云计算在大数据分析中的应用
大数据采集系统分为几类
“Spark+Hive”在DPU环境下的性能测评 | OLAP数据库引擎选型白皮书(24版)DPU部分节选
分布式存储与计算:大数据时代的解决方案
CYBT-343026传输大数据时会丢数据的原因?
阿里云在海外市场发布一系列AI大数据产品
大数据技术是干嘛的 大数据核心技术有哪些
OpenHarmony Sheet 表格渲染引擎
GPU:大数据时代的强力引擎







 工商网监
工商网监
评论