 十大机器学习算法中的线性判别分析的详细介绍
十大机器学习算法中的线性判别分析的详细介绍
先前呢,我们在最受欢迎的十大机器学习算法-part1和最受欢迎的十大机器学习算法-part2两篇文章中简单介绍了十种机器学习算法,有的读者反映看完还是云里雾里,所以,我会挑几种难理解的算法详细讲解一下,今天我们介绍的是线性判别分析。
线性判别分析(Linear Discriminant Analysis)简称LDA,是分类算法中的一种。LDA通过对历史数据进行投影,以保证投影后同一类别的数据尽量靠近,不同类别的数据尽量分开。并生成线性判别模型对新生成的数据进行分离和预测。
LDA投影矩阵
在维基百科中对投影的定义是:“投影是从向量空间映射到自身的一种线性变换,是日常生活中“平行投影”概念的形式化和一般化”。例如,在日常生活中,阳光会在大地上留下各种物体的影子。阳光将三维空间中的物体映射到影子的二维空间中,而影子随着一天中太阳照射角度的变化也会发生变化。
如果你玩过游戏《Shadowmatic》就能理解LDA投影的过程。《Shadowmatic》是一款由TRIADA Studio开发的3D解谜游戏。游戏需要玩家在灯光下旋转,扭动悬浮在空中的不明物体,并通过灯光的投影在墙上寻找不明物体的真面目。只要找对角度就能成功。如下面的游戏截图中,不明物体在某个角度的投影是一只可爱的小兔子。
LDA投影矩阵与《Shadowmatic》相似。其中的不明物体是历史数据样本。我们需要通过“旋转”和“扭动”这些历史数据,找到正确的角度发现其中的模式。以下是银行对企业贷款的样本数据,其中包含了企业经营时间和拖延还款天数以及最终是否还款的数据。

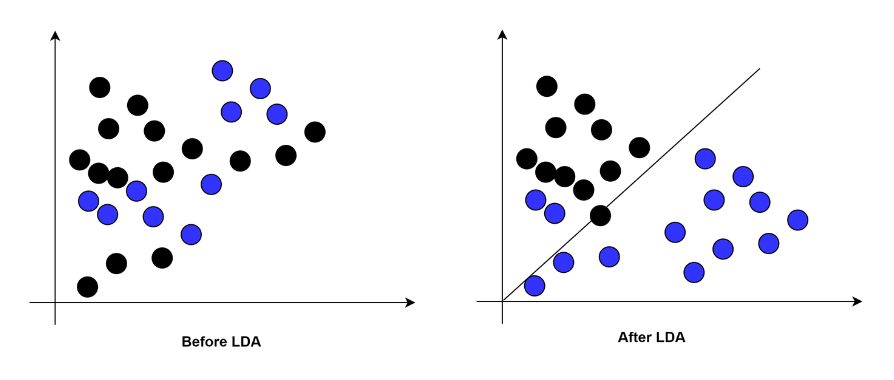
我们把这些样本数据生成散点图,其中X轴是企业经营时间,Y轴是拖延还款天数,蓝色三角表示未还款数据,红色方框表示已还款数据。在散点图中未还款和已还款数据相互交织,无法发现其中的模式。这就是游戏中的不明物体。

与游戏中不同的是我们无法“旋转”和“扭动”样本数据,而是要通过移动背景墙的位置来发现最终的“小兔子”。在下面的图中,无论我们将样本数据投影到X轴,还是Y轴,已还款和未还款的两类数据都交织在一起,我们无法发现其中的模型。更无法对数据进行分类和预测。因为任何一个单独的维度都无法判断企业最终是否会还款。我们需要变换投影背景墙的位置来找到能将两类数据分离的“角度”。

在LDA中这个投影背景墙是一个新的Y轴,角度是向量W。我们通过计算获得向量W并生成新的Y轴,使两个类别的样本数据在新Y轴的投影中能最大程度的分离。计算向量W的方法是使用两类数据的平均值差的平方除以两类数据各自的方差之和。在这个公式中,我们希望分母越小越好,分子越大越好。换句话说就是两类数据的均值相差的越大越好,这样可以保证两类数据间的分离程度。而同一类数据的方差越小越好,这样可以保证每一类数据都不会太分散。这样我们就可以找出一个W使J(W)的值最大。而这个最大值就是新的投影背景墙Y轴的方向。(这里需要通过拉格朗日来求W的最大值)

当历史样本数据被投影到新的Y轴背景墙时,可以看到数据与之前的情况不同,被明显的分为了两组。并且两组数据间的交叉很少。这符合了LDA的预期,不同类别的数据间分离的越远越好,同一类别的数据越集中越好。

到这里我们对两类数据进行了分离,但这还不能实现对数据分类和预测。因此我们还需要找到一个点来区分这两类数据。这个点就是线性辨别模型中。
LDA模式分类
线性辨别模型(Z=b1x1+b2x2)是一条直线方程,通过这条直线方程我们可以在散点图中发现可以将两组数据进行区分的数据点。并对新产生的数据进行分类和预测。如下图所示,我们通过线性辨别模型获得一条可以区分不同类别的直线。其中X1是企业经营时间,X2是拖延还款天数。而b1和b2是我们所要求的模型系数。

方差,协方差,协方差矩阵
在求线性辨别模型中的b1和b2时,需要用到协方差矩阵,因此我们先来简单介绍与协方差有关的一些概念和计算方法。
均值
首先是均值,均值的计算很简单。但要了解协方差和方差的概念,就必须先从均值开始。以下是均值的计算公式。均值表示一组数的集中程度。

方差
方差与均值正好相反,用来表示一组数的离散程度,也就是一组数中每一个数到均值的距离。由于均值通常是一组数的中心点,为了避免左右两侧的数据由于正负相互抵消无法准确的表示平均距离。我们先对距离取平方在进行汇总,汇总的结果就是方差的值。方差开平方就是标准差。

协方差
协方差是在方差的基础上扩展得到的,从计算公式中就能看出来。协方差与方差有两个最大的区别,第一个区别是方差是用来描述一组数的而协方差是用来描述两组数的。第二个区别是方差用来描述一组数的离散程度,也就是离均值的距离,而协方差是用来描述两组数直接的联系的。
方差与协方差计算公式:


协方差是一种用来度量两个随机变量关系的统计量。
当cov(X, Y)>0时,表明 X与Y 正相关;
当cov(X, Y)<0时,表明X与Y负相关;
当cov(X, Y)=0时,表明X与Y不相关。
协方差矩阵
协方差只能处理两组数(两维)间的关系,当要计算的数据多于两组(多维)时,就要用到协方差矩阵。协方差矩阵其实是分别计算了不同维度之间的协方差。通过下图可以发现协方差矩阵是一个对称的矩阵,对角线是各个维度上的方差。

计算线性辨别模型
在开始计算线性辨别模型之前,我们按企业是否还款将历史数据分为已还款和未还款两个类别。用以进行后面的计算。

计算均值,概览及协方差矩阵
我们分别计算出已还款和未还款两个类别中条目的数量,在整体样本数据中出现的概率以及企业经营时间和拖延还款天数的均值。

按照前面介绍的协方差矩阵公式分别计算出两个类别的协方差矩阵。从下图中可以发现,协方差矩阵是一个对称的矩阵,并且对角线上的两个数字就是企业经营天数和拖延还款天数的方差值。

合并协方差矩阵
按照合并协方差的公式我们将两个类别的协方差矩阵按出现的概率合并为一个协方差矩阵。以下是合并协方差的公式。

按照上面的公式,将每个类别的协方差矩阵乘以该类别的概率我们获得了合并协方差矩阵。

逆协方差矩阵
最后我们对两个类别的协方差矩阵求他的逆协方差矩阵。。

这是我们求得的合并协方差矩阵的逆矩阵。

计算线性辨别模型系数
求得逆协方差矩阵后,就可以通过两个类别的均值差和逆协方差矩阵计算线性辨别模型的系数。下面分别给出了两个类别的均值,逆协方差矩阵的对应表。


通过公式分别求出线性辨别模型的两个系数b1和b2,以下是公式和计算步骤。

b1=0.0001(116.23-115.04)+0.0003(16.89-55.32)=-0.009696

b2=0.0003(116.23-115.04)+0.0037(16.89-55.32)=-0.143453
两个系数分别为b1=-0.009696,b2=-0.143453。将系数值代入到模型中,就是我们所求的线性辨别模型。


责任编辑:gt
-
3D
+关注
关注
9文章
2875浏览量
107474 -
游戏
+关注
关注
2文章
742浏览量
26312 -
机器学习
+关注
关注
66文章
8406浏览量
132553
发布评论请先 登录
相关推荐
【专辑精选】机器学习之算法教程与资料
基于核函数的Fisher判别分析算法在人耳识别中的应用
近邻边界Fisher判别分析

不相关判别分析算法在人脸识别中应用
核局部Fisher判别分析的行人重识别
基于逐步判别分析的血液气味识别

python机器学习工具sklearn使用手册的中文版免费下载

利用基于线性判别分析的多变量分析模型对豇豆种子进行分类
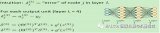
线性判别分析LDA背后的数学原理
机器学习的基本流程和十大算法





 工商网监
工商网监
评论