 使用Flask和Docker容器化一个简单的ML模型评分服务器
使用Flask和Docker容器化一个简单的ML模型评分服务器
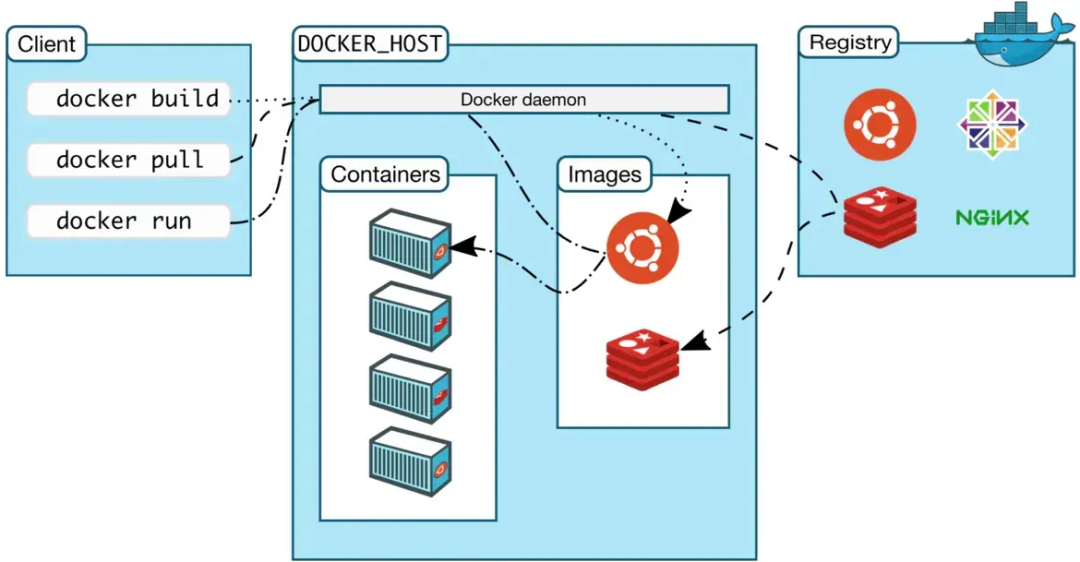
将机器学习(ML)模型部署到生产环境中的一个常见模式是将这些模型作为 RESTful API 微服务公开,这些微服务从 Docker 容器中托管,例如使用 SciKit Learn 或 Keras 包训练的 ML 模型,这些模型可以提供对新数据的预测。然后,可以将它们部署到云环境中,以处理维护连续可用性所需的所有事情,例如容错、自动缩放、负载平衡和滚动服务更新。
持续可用的云部署的配置详细信息对于不同的目标云提供商来说是不一样的——例如,Amazon Web 服务的部署过程和拓扑结构与微软 Azure 不同,后者又与谷歌云平台不同。这构成了每个云提供商需要获取的知识。此外,在本地测试整个部署策略是困难的(有些人会说几乎不可能),它使得网络等问题难以调试。
Kubernetes 是一个容器编排平台,旨在解决这些问题。简而言之,它提供了一种机制,用于定义整个基于微服务的应用程序部署拓扑及其维护连续可用性的服务级别要求。对于目标云提供商来说,它可以在本地运行,甚至可以在你的笔记本电脑上运行,而这一切所需的只是运行 Kubernetes 的虚拟机集群,即 Kubernetes 集群。
这篇博客适合与GitHub 存储库中的代码一起阅读,其中包含 Python 模块、Docker 配置文件和 Kubernetes 指令,用于演示如何使用 Docker 和 Kubernetes 将简单的 Python ML 模型转换为生产级 RESTful 模型评分(或预测)API 服务。这不是一个全面的指南,但它会帮助你快速启动和运行,熟悉基本概念和模式。
我们将使用两种不同的方法演示 ML 模型部署:使用 Docker 和 Kubernetes 的第一原则方法;然后使用 Seldon Core Kubernetes 本机框架来简化 ML 服务的部署。前者将有助于理解后者,后者构成一个强大的框架,用于部署和监视许多复杂的 ML 模型管道的性能。
使用 Flask 和 Docker 容器化一个简单的 ML 模型评分服务器
我们首先演示如何使用 api.py 模块中包含的简单 Python ML 模型评分 REST API 和 Dockerfile 来实现这一基本功能,这两个文件都位于 py-flask-ml-score-api 目录中,其核心内容如下:
py-flask-ml-score-api/
| Dockerfile
| Pipfile
| Pipfile.lock
| api.py
在 api.py 模块中定义 Flask Service
这是一个 Python 模块,它使用 Flask 框架定义一个 web 服务(app),带有一个函数(score),该函数在响应对特定 URL(或「route」)的 HTTP 请求时执行,这要归功于 app.route 函数的封装。相关代码复制如下,以供参考:
from flask import Flask, jsonify, make_response, request
app = Flask(__name__)
@app.route(‘/score’, methods=[‘POST’])
def score():features = request.json[‘X’] return make_response(jsonify({‘score’: features}))
if __name__ == ‘__main__’: app.run(host=‘0.0.0.0’, port=5000
如果在本地运行(例如,使用 python run api.py 启动 web 服务),我们就可以在 http://localhost:5000/score访问我们的函数。此函数接受以 JSON 形式发送给它的数据(该数据已自动反序列化为 Python dict,在函数定义中用作请求变量),并返回响应(自动序列化为 JSON)。
在我们的示例函数中,我们期望传递给 ML 模型一组特性 X,在我们的示例中,ML 模型将这些相同的特性返回给调用者,即我们选择的 ML 模型是 identity 函数,我们选择它纯粹是为了演示。我们可以很容易地加载一个 pickled SciKit Learn 或 Keras 模型,并将数据传递给 approproate predict 方法,以 JSON 的形式返回特性数据的分数。
用 Dockerfile 定义 Docker 映像
Dockerfile 本质上是 Docker 使用的配置文件,它允许你在操作时定义 Docker 容器的内容并配置其操作。此静态数据在未作为容器执行时称为「image」。作为参考,Dockerfile 复制如下:
FROM python:3.6-slim
WORKDIR /usr/src/app
COPY 。 .
RUN pip install pipenv
RUN pipenv install
EXPOSE 5000
CMD [“pipenv”, “run”, “python”, “api.py”]
在我们的示例 Dockerfile 中,我们:
首先使用一个预先配置好的 Docker 镜像(python:3.6-slim),它已经安装了 python 的 Alpine Linux 发行版;
然后将 py-flask-ml-score-api 本地目录的内容复制到图像上名为 /usr/src/app 的目录中;
然后使用 pip 为 Python 依赖管理安装 Pipenv 包;
然后使用 Pipenv 将 Pipfile.lock 中描述的依赖项安装到映像上的虚拟环境中;
将端口 5000 配置为暴露在运行容器上的「外部世界」;
启动 Flask RESTful web 服务——api.py。注意,这里我们依赖 Flask 的内部 WSGI 服务器,而在生产环境中,我们建议配置一个更鲁棒的选项(例如 Gunicorn)。
构建此自定义映像并要求 Docker 进程运行它(请记住,正在运行的映像是一个「容器」),将在端口 5000 上公开我们的 RESTful ML 模型评分服务,就像它在专用虚拟机上运行一样。有关这些核心概念的更全面的讨论,请参阅 Docker 官方文档。
为 ML Scoring Service 构建 Docker 映像
我们假设 Docker 在本地运行,客户端登录到 DockerHub 上的一个帐户,并且在这个项目的根目录中有一个打开的终端。要构建 Dockerfile 运行中描述的映像:
docker build --tag alexioannides/test-ml-score-api py-flask-ml-score-api
其中「AlxiiNANIDs」指的是 DockerHub 帐户的名称,我们将在对图像进行测试之后上传它。
测试
要测试印象是否可以用于创建一个 Docker 容器,该容器的功能与我们预期的一样,
docker run --rm --name test-api -p 5000:5000 -d alexioannides/test-ml-score-ap
我们已经从 Docker 容器(即我们的 ML 模型评分服务器正在监听的端口)映射到主机(localhost)上的端口 5000:
docker ps
然后检查容器是否正在使用:
curl http://localhost:5000/score \--request POST \ --header “Content-Type: application/json” \ --data ‘{“X”: [1, 2]}
你应该得到的输出是:
{“score”:[1,2]}
我们的测试模型所做的只是返回输入数据,即它是 identity 函数。修改此服务以从磁盘加载 SciKit Learn 模型并将新数据传递给生成预测的「predict」方法只需要几行额外的代码。现在容器已经确认可以使用了,我们可以停止它:
docker stop test-api
将印象推送到 DockerHub 注册表
为了让远程 Docker 主机或 Kubernetes 群集能够访问我们创建的映像,我们需要将其发布到映像注册表。所有能提供基于托管 Docker 服务的云计算提供商都将提供私有印象注册,但为了方便起见,我们将使用 DockerHub 的公共印象注册。将我们的新印象推到 DockerHub(我的帐户 ID 是「AlxiiNANIDs」)。
docker push alexioannides/test-ml-score-api
我们现在可以看到,我们为印象选择的命名约定与我们的目标图像注册表有内在的联系(需要时,你需要插入自己的帐户 ID)。上传完成后,登录 DockerHub,通过 DockerHub 用户界面确认上传成功。
安装 Kubernetes 供本机开发和测试
安装单节点 Kubernetes 集群有两个适合本机开发和测试的选项:通过 Docker 桌面客户端,或者通过 Minikube。
通过 Docker 桌面安装 Kubernetes
如果你一直在 Mac 电脑上使用 Docker,那么你很有可能是通过 Docker 桌面应用程序来完成的。如果没有,则可以在此处下载 Docker 桌面。Docker 桌面现在与 Kubernetes 捆绑在一起,可以通过进入 Preferences-》Kubernetes 并选择 Enable Kubernetes 来激活它。Docker 桌面需要一段时间才能下载运行 Kubernetes 所需的 Docker 印象,所以请耐心等待。完成后,转到 Preferences-》Advanced,确保至少为 Docker 引擎分配了 2 个 CPU 和 4 个 GiB,这是部署单个 Seldon ML 组件所需的最低资源。
要与 Kubernetes 集群交互,你需要 kubectl 命令行界面(CLI)工具,该工具需要单独下载。在 Mac 上执行此操作的最简单方法是使用 brew install kubernetes-cli。一旦安装了 kubectl 并启动并运行了 Kubernetes 集群,就可以通过运行它来测试是否能按预期工作。
kubectl cluster-info
返回应该如下:
Kubernetes master is running at https://kubernetes.docker.internal:6443KubeDNS is running at https://kubernetes.docker.internal:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use ’kubectl cluster-info dump‘。
通过 Minikube 安装 Kubernetes
在 Mac OS X 上,启动和运行 Minikube 所需的步骤如下:
确保安装了安装包管理器
使用安装 VirtualBox,使用 brew cask 安装 VirtualBox
使用安装 Minikube,使用 brew cask 安装 minicube
要启动测试群集:
minikube start --memory 409
其中,我们指定了部署单个 Seldon ML 组件所需的最小内存量。耐心点,Minikube 可能需要一段时间才能开始,要先测试该群集是否运行正常。
kubectl cluster-info
其中 kubectl 是用于与 Kubernetes API 交互的标准命令行界面(CLI)客户机。
将容器化的 ML 模型评分服务部署到 Kubernetes
要在 Kubernetes 上启动我们的测试模型评分服务,我们将首先在 Kubernetes Pod 中部署容器化服务,它的推出由部署管理,而部署又会创建一个 ReplicaSet,这是通过下面的代码实现的:
kubectl create deployment test-ml-score-api --image=alexioannides/test-ml-score-api:lates
要检查部署运行的状态,
kubectl rollout status deployment test-ml-score-api
为了看到运行的 pod,
kubectl get pod
可以使用端口转发来测试单个容器,而无需将其公开到公共网络。要使用此功能,请打开一个单独的终端并运行。例如,
kubectl port-forward test-ml-score-api-szd4j 5000:500
其中 body-ml-score-api-szd4j 是集群上当前活动的 pod 的确切名称,由 kubectl get pods 命令确定。然后从原来的终端,对运行在 Kubernetes 上的同一个容器重复我们的测试请求,
curl http://localhost:5000/score \--request POST \ --header “Content-Type: application/json” \ --data ’{“X”: [1, 2]}
要将容器作为(负载平衡)服务公开,我们必须创建引用它的 Kubernetes 服务。这是通过以下命令实现的:
kubectl expose deployment test-ml-score-api --port 5000 --type=LoadBalancer --name test-ml-score-api-lb
如果你使用的是 Docker 桌面,那么这将自动vwin http://localhost:5000上的负载平衡器。查找 Minikube 在何处公开其模拟负载平衡器运行:
minikube service list
现在我们测试我们的新服务器,例如,使用 Docker 桌面:
curl http://localhost:5000/score \--request POST \ --header “Content-Type: application/json” \ --data ‘{“X”: [1, 2]}
注意,Docker Desktop 和 Minikube 都没有设置一个真实的负载平衡器(如果我们在云平台上提出这个请求,就会发生这种情况)。要拆下负载平衡器,请依次运行以下命令:
kubectl delete deployment test-ml-score-apikubectl delete service test-ml-score-api-l
在 Google 云平台上配置多节点集群
该集群的资源远远大于笔记本电脑上 Kubernetes 管理器平台。我们将在 Google 云平台(GCP)上使用 Kubernetes 引擎。
启动并运行 Google 云平台
在使用 Google 云平台之前,请注册一个帐户并创建一个专门用于此工作的项目。接下来,确保 GCP SDK 安装在本地计算机上,例如:
brew cask install google-cloud-sdk
或者直接从 GCP 下载安装映像。注意,如果你还没有安装 Kubectl,那么现在就需要安装,这可以使用 GCP SDK 完成:
gcloud components install kubectl
然后我们需要初始化 SDK
gcloud init
它将打开浏览器并指导你完成必要的身份验证步骤,确保选择创建的项目以及默认区域。
初始化 Kubernetes 群集
首先,在 GCP UI 中,访问 Kubernetes 引擎页面以触发Kubernetes API 启动。然后从命令行启动一个集群:
gcloud container clusters create k8s-test-cluster --num-nodes 3 --machine-type g1-small
然后,在等待集群创建的同时,你可以泡杯咖啡。注意,这将自动切换 kubectl 上下文以指向 GCP 上的集群,如果运行 kubectl config get-contexts,你将看到这一点。要切换回 Docker 桌面客户端,请使用 kubectl config use-context docker-desktop。
在 GCP 上启动容器化 ML 模型评分服务器
这在很大程度上与我们在本地运行测试服务时所做的相同-依次运行以下命令:
kubectl create deployment test-ml-score-api --image=alexioannides/test-ml-score-api:latestkubectl expose deployment test-ml-score-api --port 5000 --type=LoadBalancer --name test-ml-score-api-lb
但是,要找到我们需要使用的 GCP 集群的外部 IP 地址:
kubectl get services
然后我们可以在 GCP 上测试我们的服务器,例如:
curl http://35.246.92.213:5000/score \--request POST \ --header “Content-Type: application/json” \ --data ’{“X”: [1, 2]}’
或者,我们可以再次使用端口来连接到单个 pod,例如:
kubectl port-forward test-ml-score-api-nl4sc 5000:5000
然后在一个单独的终端上:
curl http://localhost:5000/score \--request POST \ --header “Content-Type: application/json” \ --data ‘{“X”: [1, 2]}’
最后,我们拆除复制控制器和负载平衡器,
kubectl delete deployment test-ml-score-apikubectl delete service test-ml-score-api-lb
在 Kubectl 上下文之间切换
如果在本地运行 Kubernetes 和 GCP 上运行一个集群,那么可以将 Kubectl 上下文从一个集群切换到另一个集群,如下所示:
kubectl config use-context docker-desktop
其中上下文的列表可以使用,
kubectl config get-contexts
使用 YAML 文件定义和部署 ML 模型评分服务器
到目前为止,我们一直在使用 Kubectl 命令来定义和部署我们的 ML 模型评分服务器的基本版本。这对于演示来说是很好的,但是很快就受限,且无法控制。实际上,定义整个 Kubernetes 部署的标准方法是使用发布到 Kubernetes API 的 YAML 文件。py-flask-ml-score-api 目录中的 py-flask-ml-score.yaml 文件是一个示例,它说明了如何在单个 yaml 文件中定义我们的 ML 模型评分服务器。现在可以使用一个命令部署它:
kubectl apply -f py-flask-ml-score-api/py-flask-ml-score.yaml
注意,我们在这个文件中定义了三个单独的 Kubernetes 组件:一个名称空间、一个部署和一个负载平衡服务器,对于所有这些组件(及其子组件),使用 --- 来限定每个单独组件的定义。要查看部署到此命名空间中的所有组件的使用方法:
kubectl get all --namespace test-ml-app
同样,当使用任何 kubectl get 命令检查测试应用程序的不同组件时,设置 --namespace 标志。或者,我们可以将新的名称空间设置为默认上下文:
kubectl config set-context $(kubectl config current-context) --namespace=test-ml-app
然后运行:
kubectl get all
在这里,我们可以使用
kubectl config set-context $(kubectl config current-context) --namespace=default
拆掉我们可以使用的应用程序,
kubectl delete -f py-flask-ml-score-api/py-flask-ml-score.yaml
这样我们就不必使用多个命令单独删除每个组件。请参阅Kubernetes API 的官方文档,以更深入地了解此 YAML 文件的内容。
使用 Helm 图表定义和部署 ML 模型评分服务器
为 Kubernetes 编写 YAML 文件可能是重复性的工作,且难以管理,特别是如果涉及到大量的「复制粘贴」,那么从一个部署到下一个部署只需要更改少数参数,但有一堵「YAML 墙」需要修改。输入 Helm——一个用于创建、执行和管理 Kubernetes 部署模板的框架。下面是一个非常棒的演示,它是关于如何使用 Helm 来部署我们的 ML 模型评分服务器。要全面讨论 Helm 的全部功能,请参考官方文档。Seldon Core 也可以使用 Helm 部署,稍后我们将更详细地介绍这一点。
安装 Helm
和以前一样,在 Mac OS X 上安装 Helm 的最简单方法是使用自制包管理器,
brew install kubernetes-helm
Helm 依赖于一个专用的部署服务器,称为「Tiller」,它运行在我们希望部署应用程序的 Kubernetes 集群中。在部署 Tiller 之前,我们需要创建一个在集群范围内的超级用户角色来分配给它,以便它可以在任何命名空间中创建和修改 Kubernetes 资源。为了实现这一点,我们首先创建一个服务帐户,通过此方法,pod 在与服务帐户关联时,可以向 Kubernetes API 进行验证,以便能够查看、创建和修改资源。我们在 kube 系统名称空间中创建它,如下所示,
kubectl --namespace kube-system create serviceaccount tiller
然后在此服务帐户和群集角色之间创建绑定,顾名思义,该绑定会授予群集范围内的管理权限:
kubectl create clusterrolebinding tiller \--clusterrole cluster-admin \ --serviceaccount=kube-system:tiller
我们现在可以将 Helm Tiller 部署到 Kubernetes 集群,并使用所需的访问权限,
helm init --service-account tiller
使用 Helm 进行部署
要创建新的 Helm 布署定义,
helm create NAME-OF-YOUR-HELM-CHART
这将创建一个新的目录,例如 helm-ml-score-app,它包含在这个存储库中,具有以下高级目录结构,
helm-ml-score-app/| -- charts/ | -- templates/ | Chart.yaml | values.yaml
简而言之,charts 目录包含我们的新表所依赖的其他表(我们不会使用这个),templates 目录包含我们的 Helm 模板,Chart.yaml 包含图表的核心信息(例如名称和版本信息),values.yaml 包含用于呈现模板的默认值的信息(如果没有从命令行设置值)。
下一步是删除模板目录中的所有文件(NOTES.txt 除外),并用我们自己的文件替换它们。我们从 namespace.yaml 开始为应用程序声明命名空间,
apiVersion: v1kind: Namespacemetadata:name: {{ .Values.app.namespace }}
在此特定实例中 .Values.app.namespace 插入 app.namespace 变量,其默认值在 Values.yaml 中定义。接下来,我们在 deployment.yaml 中定义 pods 的部署:
apiVersion: apps/v1kind: Deploymentmetadata:labels: app: {{ .Values.app.name }} env: {{ .Values.app.env }} name: {{ .Values.app.name }} namespace: {{ .Values.app.namespace }}spec:replicas: 1 selector: matchLabels: app: {{ .Values.app.name }} template:metadata: labels: app: {{ .Values.app.name }} env: {{ .Values.app.env }}spec: containers: - image: {{ .Values.app.image }} name: {{ .Values.app.name }} ports: - containerPort: {{ .Values.containerPort }}protocol: TCP
以及 service.yaml 中的负载平衡器服务的详细信息,
apiVersion: v1kind: Servicemetadata:name: {{ .Values.app.name }}-lblabels: app: {{ .Values.app.name }} namespace: {{ .Values.app.namespace }}spec: type: LoadBalancer ports: - port: {{ .Values.containerPort }} targetPort: {{ .Values.targetPort }} selector:app: {{ .Values.app.name }}
实际上,我们所做的是将部署细节的每个组件从 py-flask-ml-score.yaml 拆分到自己的文件中,然后为配置的每个参数定义模板变量。要测试和检查呈现的模板,请运行:
helm install helm-ml-score-app --debug --dry-run
如果您对「dry run」的结果感到满意,则执行部署并使用:
helm install helm-ml-score-app --name test-ml-app
这将自动打印发布的状态,以及 Helm 赋予它的名称和呈现给终端的 NOTES.txt 的内容。列出所有可用的 Helm 版本及其名称:
helm list
以及其所有组成组件(如 pod、复制控制器、服务器等)的状态,例如:
helm status test-ml-app
ML 评分服务器现在可以用与上面完全相同的方式进行测试。一旦你确信它按预期工作,就可以使用了:
helm delete test-ml-app
使用 Seldon 将 ML 模型评分服务器部署到 Kubernetes
Seldon 的核心任务是简化 Kubernetes 上复杂 ML 预测管道的重复部署和管理。在本演示中,我们将重点介绍最简单的示例,即我们已经使用的简单的 ML 模型评分 API。
为 Seldon 构建 ML 组件
要使用 Seldon 部署 ML 组件,我们需要创建 Seldon 兼容的 Docker 映像。我们首先遵循相关指导原则来定义一个 Python 类,该类封装了一个用于 Seldon 部署的 ML 模型。它包含在 seldon-ml-score-component 目录中,其内容类似于 py-flask-ml-score-api 中的内容:
seldon-ml-score-component/| Dockerfile | MLScore.py | Pipfile | Pipfile.lock
构建 Docker 印像以用于 Seldon
Seldon 要求 ML 评分服务器的 Docker 映像以特定的方式构造:
ML 模型必须封装在一个 Python 类中,其中包含一个带有特定签名(或接口)的 predict 方法,例如,在 MLScore.py(故意以其中包含的 Python 类命名)中:
class MLScore: “”“ Model template. You can load your model parameters in __init__ from a location accessible at runtime ”“” def __init__(self): “”“ Load models and add any initialization parameters (these will be passed at runtime from the graph definition parametersdefined in your seldondeployment kubernetes resource manifest)。 ”“”print(“Initializing”) def predict(self, X, features_names): “”“ Return a prediction. Parameters ---------- X : array-like feature_names : array of feature names (optional) ”“” print(“Predict called - will run identity function”) return X
必须安装 seldon core Python 包
容器首先使用 seldon-core 包提供的 Seldon core microservice 入口点运行 Seldon 服务,它和上面的点都可以看到 DockerFile
FROM python:3.6-slimCOPY 。 /appWORKDIR /appRUN pip install pipenvRUN pipenv installEXPOSE 5000# Define environment variableENV MODEL_NAME MLScoreENV API_TYPE RESTENV SERVICE_TYPE MODELENV PERSISTENCE 0CMD pipenv run seldon-core-microservice $MODEL_NAME $API_TYPE --service-type $SERVICE_TYPE --persistence $PERSISTENCE
有关详细信息,请参阅 Seldon 官方文件。接下来,建立这个印象:
docker build seldon-ml-score-component -t alexioannides/test-ml-score-seldon-api:latest
在将此印像推送到注册表之前,我们需要确保它按预期工作。在本地 Docker 守护进程上启动映像:
docker run --rm -p 5000:5000 -d alexioannides/test-ml-score-seldon-api:latest
然后向它发送一个请求:
curl -g http://localhost:5000/predict \--data-urlencode ‘json={“data”:{“names”:[“a”,“b”],“tensor”:{“shape”:[2,2],“values”:[0,0,1,1]}}}’
如果响应与预期一致(即它包含与请求相同的负载),则推送印象:
docker push alexioannides/test-ml-score-seldon-api:latest
使用 Seldon Core 部署 ML 组件
我们现在继续将 Seldon 兼容的 ML 组件部署到 Kubernetes 集群,并从中创建一个容错和可缩放的服务器。为了实现这一目标,我们将使用 Helm 表部署 Seldon Core。我们首先创建一个包含 seldon core 操作符的命名空间,这是使用 seldon 部署任何 ML 模型所需的自定义 Kubernetes 资源:
kubectl create namespace seldon-core
然后我们使用 Helm 部署 Seldon Core,并在 https://storage.googleapis.com/Seldon-charts上部署 Seldon Helm 图表库:
helm install seldon-core-operator \--name seldon-core \ --repo https://storage.googleapis.com/seldon-charts \ --set usageMetrics.enabled=false \ --namespace seldon-core
接下来,我们为 Kubernetes 部署 Ambassador API 网关,它将充当 Kubernetes 集群的入口点。我们将为 Ambassador 部署创建一个专用名称空间:
kubectl create namespace ambassador
然后使用 Helm 官方库中最新的图表部署 Ambassador:
helm install stable/ambassador \--name ambassador \ --set crds.keep=false \ --namespace ambassador
如果我们现在运行 helm list --namespace seldon-core,我们应该看到 seldon core 已经部署好了,并且正在等待 seldon ML 组件的部署。为了部署我们的 Seldon ML 模型评分服务器,我们为它创建了一个单独的名称空间:
kubectl create namespace test-ml-seldon-app
然后配置并部署另一个官方 Seldon Helm,如下所示:
helm install seldon-single-model \--name test-ml-seldon-app \ --repo https://storage.googleapis.com/seldon-charts \ --set model.image.name=alexioannides/test-ml-score-seldon-api:latest \ --namespace test-ml-seldon-app
注意,通过重复最后两个步骤,现在可以使用 Seldon 部署多个 ML 模型,它们都将通过同一个 Ambassador API 网关自动访问,我们现在将使用该网关测试 Seldon ML 模型评分服务器。
通过 Ambassador 网关 API 测试 API
为了测试基于 Seldon 的 ML 模型评分服务器,我们遵循与上面 Kubernetes 部署相同的方法,但是我们将通过 Ambassador API 网关路由我们的请求。要查找 Ambassador 服务运行的 IP 地址:
kubectl -n ambassador get service ambassador
如果使用 Docker 桌面,则为 localhost:80;如果在 GCP 或 Minikube 上运行,则为 IP 地址(如果在后一种情况下需要记住使用 minikuke 服务列表)。现在测试预测的终结点,例如:
curl http://35.246.28.247:80/seldon/test-ml-seldon-app/test-ml-seldon-app/api/v0.1/predictions \--request POST \ --header “Content-Type: application/json” \ --data ‘{“data”:{“names”:[“a”,“b”],“tensor”:{“shape”:[2,2],“values”:[0,0,1,1]}}}’
如果你想了解路由背后的完整逻辑,请参阅Seldon 文档,但 URL 实际上使用的是:
http://《ambassadorEndpoint》/seldon/《namespace》/《deploymentName》/api/v0.1/predictions
如果你的请求成功了,那么你应该会看到如下的结果:
{“meta”: { “puid”: “hsu0j9c39a4avmeonhj2ugllh9”, “tags”: { }, “routing”: {}, “requestPath”: { “classifier”: “alexioannides/test-ml-score-seldon-api:latest” }, “metrics”: [] }, “data”: { “names”: [“t:0”, “t:1”], “tensor”: {“shape”: [2, 2], “values”: [0.0, 0.0, 1.0, 1.0] } }}
清理
要删除使用上述步骤部署的单个 Seldon ML 模型及其命名空间,请运行:
helm delete test-ml-seldon-app --purge &&kubectl delete namespace test-ml-seldon-app
按照同样的模式移除 Seldon 核心操作器和 Ambassador:
helm delete seldon-core --purge && kubectl delete namespace seldon-corehelm delete ambassador --purge && kubectl delete namespace ambassador
如果有一个 GCP 集群需要终止运行:
gcloud container clusters delete k8s-test-cluster
同样,如果使用 Minikube:
minikube stopminikube delete
如果在 Docker 桌面上运行,导航到 Preferences-》Reset 重置集群。
接下来做什么
以下资源列表将帮助你深入了解我们在上面略过的主题:
the full set of functionality provided by Seldon;
running multi-stage containerised workflows (e.g. for data engineering and model training) using Argo Workflows;
the excellent ‘Kubernetes in Action‘ by Marko Luka available from Manning Publications;
‘Docker in Action‘ by Jeff Nickoloff and Stephen Kuenzli also available from Manning Publications;
‘Flask Web Development’ by Miguel Grinberg O’Reilly.
via:https://alexioannides.com/2019/01/10/deploying-python-ml-models-with-flask-docker-and-kubernetes/
-
应用程序
+关注
关注
37文章
3265浏览量
57677 -
ML
+关注
关注
0文章
149浏览量
34642 -
python
+关注
关注
56文章
4792浏览量
84627
发布评论请先 登录
相关推荐
云服务器与容器的区别和联系
docker-compose配置文件内容详解以及常用命令介绍

Kubernetes集群搭建容器云需要几台服务器?
入门级攻略:如何容器化部署微服务?
容器云跟服务器有啥区别?五个区别要知道
常见的服务器容器和漏洞类型汇总
ARM平台实现Docker容器技术
ARM平台实现Docker容器技术
Jtti:Docker会替代调虚机吗

宝塔面板Docker一键安装:部署GPTAcademic,开发私有GPT学术优化工具
Docker容器实现开机自动启动策略
ARM平台实现Docker容器技术





 工商网监
工商网监
评论