 答疑解惑探讨小样本学习的最新进展
答疑解惑探讨小样本学习的最新进展
编者按:深度学习和人类智能存在一个显著差异,即人类擅长通过极少量的样本识别新类别物体,而深度学习在此情况下很容易产生过拟合。因此,小样本问题成为了机器学习领域中重要的研究方向之一。目前已有基于度量学习、语义信息以及数据增强等多种方法,而至于大小样本的边界、小样本学习的方法论等问题还备受关注。在本文中,复旦大学付彦伟、上海科技大学何旭明、北京邮电大学马占宇、中科院计算所王瑞平(按发言顺序整理),将答疑解惑探讨小样本学习的最新进展。本文整理自VALSE Webinar 2019第29 期Panel。
议题1
小样本 vs 大样本,多“小”才算小,多“大”才算大?什么样的情况下,需要专门设计“小样本”学习算法?小样本学习在智能体学习过程中如何和不同大小样本的数据融合?如何在数据积累中过渡到大样本学习?
付彦伟:这个问题很基础也很有意思,我们其实做小样本,一般都考虑每个类只有一个三个五个、或者十来个样本,这种one-shot 、three-shot、five-shot情况。此外在深度学习之前,从partical learning这个角度来看其实有些问题可以借鉴,在统计学,小样本学习不叫one-shot learning,而叫做smoothing probability,也就是小样本可能还和特征维度有关系。假设你的特征维度是D的话,当样本量小于logD,就算一个比较小的样本。当然现在有深度学习了,我们可能并不会从这个角度去看。
至于什么样的情况需要专门设计小 样本学习算法,其实这是一个很实际或者很工业的问题,比如在医疗图像处理中解决很罕见的病变,样本量确实不够,我们想去学一个分类器就只能根据这个数据去设计小样本学习算法。
小样本学习在智能体学习过程如何和不同大小样本的数据融合,这其实有很多角度。比如李飞飞老师在 ICCV2003年的一篇文章,通过贝叶斯这条思路去融合;我们也可以和专家系统,或者通过一些专家知识融合,甚至可以和不同的领域,比如vocabulary inference learning领域,通过NLP去学习一些语义字典帮助小样本学习;如何在数据积累中过渡到大样本学习,这有一个很典型的增量学习问题。
何旭明:从视觉概念的认知角度来看,小样本的“大小”也体现在它与其他类别之间区分度的大小。即使有些类别样本数量比较小,如果它和其他类别相似度较高,可以用很多先验知识来帮助学习这些小样本,因此也可以不算“小样本”。如果碰到一个和其他类区别很大的类别,可能通常的学习就会变得非常困难,需要当作小样本看待。
如果利用一些先验知识能够帮助学习小样本类别,我觉得这种情况是可以设计相关算法的。但如果很难得到先验知识,那无论什么设计也学不到有用信息。
针对如何从不同大小样本中的数据融合问题,我认为可以从大样本入手开始学习,然后扩展到小样本。即使类别不同,如果有相关性的话,依然可以去借鉴大样本统计上的一些规律来帮助小样本学习。
最后,借鉴人类的学习过程来说,一开始可能是小样本,然后不断在数据积累和反馈机制下,可以获得更新的数据。这样可以把视觉概念的表征不断地细化,最后能够自然而然地就能过渡到大样本。
马占宇:关于如何与不同规模大小样本的数据融合,我觉得还有一个不平衡的学习问题。即首先分清哪些类别样本是小的,哪些类别是大的。这种情况下,不是简简单单真地把小样本变大,或者是说把大样本增强,理想的状况是能够在数据分布不平衡的情况下,去做一个比较好的分类器。
议题2
引入知识来弥补小样本的数据不足是一个较为公认的趋势,到底什么算是“知识”,有哪些形式?目前真正管用/好用的“知识”是什么,来自哪里?
王瑞平:现在模型能够取得成功,基本上都是依赖数据驱动。在数据不足的情况下,尤其在零样本学习(极端情况)里面,一定要利用语义的知识去辅助。到底什么算是“知识”,现在零样本里面可能会用一些属性的标注,包括一些类别在语义层面的相似性关系,都算比较底层的知识。从人类的认知角度来看,相关的知识库和应用也可称之为“知识”,这可能是一种更自然的方式。
那么目前真正管用或者是好用的“知识”有哪些?在零样本和小样本学习里面,大部分还是属性、词向量这种人类手工标注的语义描述,其实这种知识可扩展性比较差。我们不可能对所有类别标注它所需要的全部知识,将来更有实践意义的,应该是从大量原始文本数据中进行类别相关的语义挖掘和提纯,然后结合手工标注的属性。这方面目前很大程度上仍受限于自然语言处理技术的发展,所以真正地用知识去弥补数据不足应该是可努力的方向。
何旭明:在一些特定专业领域里面标注是很困难的,比如医学图像分析。但是很多医学学科已经建立了比较完整的知识体系,因此充分利用这些专业的知识体系,可以帮助弥补数据匮乏的弱点。
付彦伟:从贝叶斯的角度,我们可以把知识当做一个先验信息,把小样本或者这些知识建模成一个分布,来帮助小样本学习。甚至可能从图形学模型的角度去思考,比如把一些领域的知识建模成一个ontology或者是一个图形学模型。目前这方面还没有探索得特别清楚,掌握知识其实是一个很基础的问题。
议题3
在小样本学习的实际场景中,数据量缺乏会带来domain gap(域漂移)问题,怎么看待域漂移给小样本学习带来的挑战?
马占宇:我觉得域漂移和知识迁移都属于跨域问题,从不同域之间这个层面上来定义比较好。所以说域漂移给小样本学习带来了挑战,也带来了一些好处和机会,比如我们前面提到的跨模态、多模态,可以把不同域之间的知识融合起来,最终进行小样本学习。
议题4
什么样的小样本训练数据集能够产生较好的模型?
付彦伟:源数据和目标数据比较相近或者相似的时候,源数据上训练的模型用于目标数据的小样本学习,效果还是比较好的,如果差得比较大的话,其实还是有很大影响的,这个其实直接就和域漂移有很大关系。我们在做一些缺陷检测时也会遇到很多类似的问题。
何旭明:在实用场景里面可以依据情况来考虑样本选择,依据问题赋予的灵活性分两种情况:第一类问题,如果类别是可以选的,那就选择和源数据比较近的样本;第二类,如果类别是预规定好的,可以在每个类别通过数据选择产生一些比较好的数据帮助训练。
议题5
one-shot learning要解决的是仅有少量训练数据时模型的过拟合问题么?那传统解决过拟合的方法(如特征选取,正则化,提高训练样本多样性等)如何体现在现有的one-shot方法中呢?
付彦伟:之前基本就是以上的传统策略。但是有了深度学习之后,我们如果不用迁移学习,每个类5个训练样本来训练一个学习器,可能就要考虑特征选择、正则化这些问题。用深度学习的话,这个问题应该还是存在的,可能只是形式变了,我们采用batch normalization 或者instance normalization来进行正则化,特征选取可能也能对应得上。因为我们在深度学习中会隐含去做这些事情,比如说注意力机制本身也是一种特征选取。
何旭明:注意力机制实际上其实是在动态地特征选取。正则化的作用,除了BN,其实你的网络模型设计就体现了对模型的约束;还有模型训练的损失函数设计也体现了这点,比如添加额外的约束项。提高训练样本的多样性的话,现在很多的趋势,就是做feature augmentation(特征增广)。
议题6
机器学习(深度学习)如今依赖海量数据,样本量过小容易过拟合,模型表达能力不足。但某些实际场景下样本很难收集,应该如何处理这些问题,如何防止过拟合?
王瑞平:这应该就是小样本学习的背景,小样本和数据不平衡问题其实是共生的,实际生活当中这两个问题是普遍存在的。从企业界的项目经验来看,通过数据增广、相似类别之间的知识迁移、数据合成和domain adaptation(域自适应学习)。针对样本类别之间的不平衡问题,可以做数据的合成或者分类器的合成。
马占宇:样本量过小导致的过拟合不仅是小样本学习中面临的问题。传统机器学习里也同样面临这个问题,需要结合不同场景具体分析。
议题7
在小样本学习中如何考虑任务之间的相关程度?如何在新领域的任务中应用小样本学习方法?
何旭明:现在的很多假设任务是独立同分布的,也就是从一个分布中采样出独立的任务。在这个假设下,很难去探索任务之间的相关度。在实际应用中,这个假设是比较强的,很多时候任务之间的确是有相关度的。那么或许最后会变成一个类似于多任务学习的问题设定。
议题8
零样本学习中,辅助信息(属性,词向量,文本描述等)未来的发展趋势是怎样的?
付彦伟:无论图像识别、自然语言处理还是其他领域,都可能会存在零样本学习的问题。属性和词向量也有很多缺点,比如多义性,你说apple是apple公司还水果apple,这本身就有歧义性。
何旭明:如果利用这些辅助信息其中的内在关联建立起信息之间的联系,就可能是一种有结构的知识图谱。换个角度,因为这些属性词向量,就是知识表达的一个具体体现,而背后的应该是整个的一个知识体系。
议题9
可解释性学习能否促进零样本学习的发展?
马占宇:我先打一个比方,可能不太恰当。在信号处理领域里,我们接受到的是信号,然后从中获取信息,最后又把信息提炼成知识,这个是不同层次,不同内涵的事情。当然对于我们做视觉任务来说,也许就是图像中寻找一些显著区域,然后在该区域搜集某些特征、目标。因此,从这个角度讲,可解释性学习对零样本的发展是有帮助的,但是目前如何促进以及结合知识,我觉得还是一个比较有挑战或者开放的问题。
王瑞平:模型的可解释性肯定能促进零样本学习的发展,零样本学习之所以能做,就是因为能够去建立类别之间的关联,把所谓的已知类的语义信息迁移到未知类别上面。
类别通过什么关联的呢?其实类别背后的根本是一些概念的组合,比如有没有四条腿、皮毛、何种颜色等概念。那么如果能够从已有分类模型中学习出来样本和类别间的因果关系,并知道类别之间的差异何在,以及模型与概念的对应关系,试图去解决零样本和小样本之间的问题,就能追溯到可迁移的根本所在。
付彦伟:深度学习的可解释性可能更侧重于特征的描述,零样本学习最开始的一些工作,其实一直都是以可解释性这个思路去做,就是把X映射到一个Y,Y是H的空间,后来我们又通过这种语义的可解释性来做零样本学习。如果单纯地只是深度学习特征的可解释性,就相当于怎么去更好地提取X,由X去构造零样本学习.。
小结
正所谓“巧妇难为无米之炊”,在使用深度学习这一工具解决实际问题时,难免会遇到样本不足的情况。而受人类快速学习能力的启发,研究人员希望机器学习模型能够在习得一定类别数据后,只需少量样本就可以学习新的类别,这就是小样本学习(Few-shot Learning)要解决的问题。
“样本量与特征维度的大小关系“、”样本与其他类别的区分度”等因素,可能和大小样本的界定有紧密关联。小样本学习可以同专家系统、自然语言处理等领域融合,并借助大样本上的数据积累和一些反馈机制自然过渡到大样本学习。虽然小样本学习是人类学习的一个特长,但即便是人类,其本质上的学习也是基于大样本的,它包括漫长的进化过程和多模态共生信息的影响,人类的“举一反三”依旧是基于大数据和知识的转化问题。因此,通过引入知识来弥补小样本的数据不足是一个较为公认的趋势。人类手工标注或者提取自大数据的语义描述、特定领域的知识体系都是可利用的“知识”。在实际应用中,小样本和数据不平衡往往是共生的,通过数据增广、相似类别之间的知识迁移、数据合成、结构化的知识图谱、域自适应学习、借助模型的可解性等策略可提升小样本学习性能。
-
算法
+关注
关注
23文章
4607浏览量
92826 -
小样本
+关注
关注
0文章
7浏览量
6821 -
深度学习
+关注
关注
73文章
5500浏览量
121109
原文标题:小样本学习,路在何方?【VALSE Webinar】
文章出处:【微信号:deeplearningclass,微信公众号:深度学习大讲堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

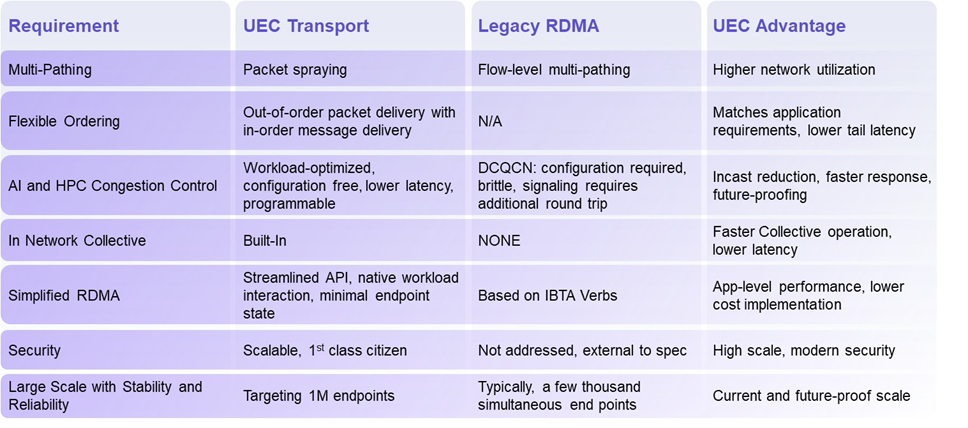
揭秘超以太网联盟(UEC)1.0 规范最新进展(2024Q4)
Qorvo在射频和电源管理领域的最新进展
小鹏汽车图灵芯片及L4自动驾驶新进展
芯片和封装级互连技术的最新进展
高燃回顾|第三届OpenHarmony技术大会精彩瞬间
5G新通话技术取得新进展
广东的5G-A、信号升格和低空经济,又有新进展!

百度首席技术官王海峰解读文心大模型的关键技术和最新进展

四个50亿+,多个半导体项目最新进展!
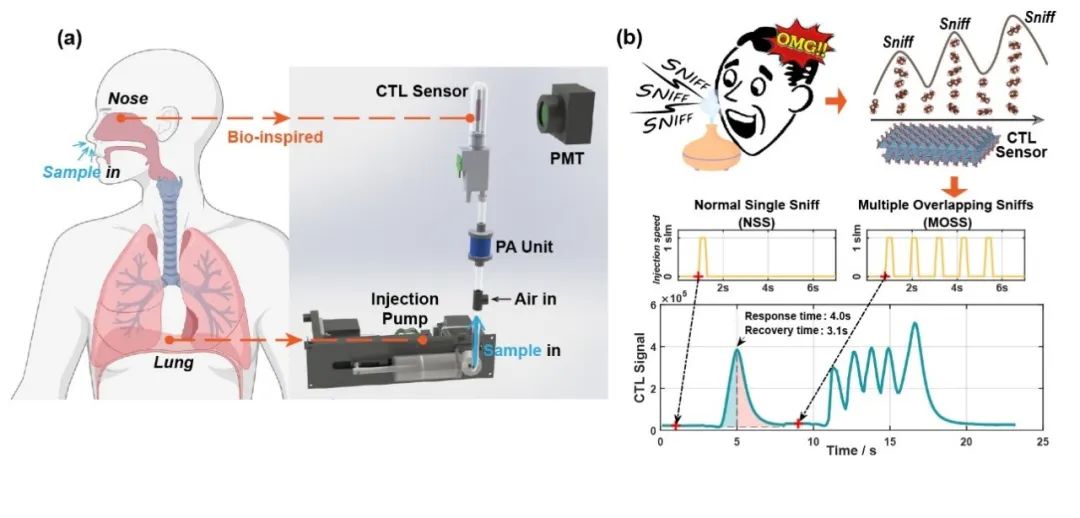
清华大学在电子鼻传感器仿生嗅闻方向取得新进展
WiFi 8,最新进展!
语音识别技术最新进展:视听融合的多模态交互成为主要演进方向






 工商网监
工商网监
评论