 东京大学内部芯片项目的名称译名是什么?
东京大学内部芯片项目的名称译名是什么?
挑战硬件的物理极限总是一件有趣的事,Preferred Networks公司正在做的事着实震惊了很多人。Preferred Networks公司是从东京大学(Tokyo University)衍生出来的,它正在将几个大芯片植入一张PCIe卡中,以实现峰值性能和峰值功率。他们已经准备将超过10,000张芯片部署到一台定制的超级计算机中。
让我们从7225平方毫米的封装开始。这是典型的BGA封装,带有其他6457个引脚。封装内有四个基于TSMC 12FFC的硅芯片,每个硅芯片面积为756.7 mm2(32.2 mm x 23.5 mm),这意味着该处理器总计有3026.8 mm2的硅面积。这比高端计算GPU中使用的800 mm2的硅面积以及高端EPYC CPU中使用的1000 mm2以上的硅面积多太多了。这实在是一个令人难以置信的数字,特别是对于要插入PCIe卡的产品而言。
与相关的散热片一起,芯片位于32GiB某种形式的存储器所包围的PCB上。整个设备是一个深度学习加速器,旨在为性能和功率提供关键指标。在半精度(FP16)的524万亿次浮点运算性能下,该芯片还有一个500W的TDP,这意味着该芯片的目标达到了每瓦1.05 TFLOPs。在0.55 V时,这意味着芯片最高工作电流接近1000安培,因此需要自定义PCB设计,但仍可通过PCIe启用。该卡是扩展的PCIe设计,具有强制冷却功能(即使在服务器中也是如此),并将安装在7U机架式机箱中。每个服务器都是一个双插槽CPU,最多可包含四个卡,从而提供半精度DL计算的2 PetaFLOPs算力。通过卡上的散热,现在每张卡在服务器内部的最大功率为600W。
该芯片是MN-Core系列的一部分。Preferred Networks是一家专门制造有特定需求的私有超级计算机的公司。自2014年成立以来,该公司已投入1.3亿美元资金,其中近9700万美元来自丰田。从2017年起,Preferred Networks公司已经为东京大学建造了三台人工智能超级计算机,大部分使用P100和V100 NVIDIA加速器,最新的MN-2使用了1024个V100 SXM2部件,达到了128 PetaFLOPs。这款新芯片位于Preferred Networks最新的MN-3超级计算机的中心,将是第一个采用定制芯片的。
MN-3将在每台7U服务器上配置4个这样的芯片,使性能提高到2.1 PF。每个机架将有4台服务器,大约300个机架,4800个网核板。这将提供2.5 ExaFLOPs的总半精度峰值性能。Wikichip的David Schor估计总耗电量约为3.36兆瓦,比市场上其他系统的效率要高得多。MN-3预计将于2020年投入使用。
戴维(David)还对这种芯片的结构做了一些挖掘。从图片中,我们可以在芯片上清楚地看到单词‘ GRAPE-PFN2 ’,它代表GRAPE(东京大学内部芯片项目的名称)和PFN2(或首选网络)。东京大学在GRAPE旗下有许多定制的芯片项目:可以用于重力计算,多物体计算和分子动力学等。Preferred Networks团队的成员以前曾在GRAPE-DR物理协处理器上工作,包括Hiraki教授,这就是为什么超级计算中显示的架构图如此相似的原因。
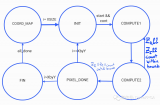
每个芯片都包含两个管芯到管芯的互连,并与一些调度引擎,PCIe架构配合使用,计算在四个大的“二级块(L2Bs)”中进行。每个L2B有8个L1B和一个共享缓存,L1B内部有16个矩阵运算块(abs)和一个L1共享缓存。每个MAB有四个处理引擎(PEs)和一个矩阵运算单元(MAU),它似乎是为执行矩阵乘法和加法而构建的。一个裸片总共将具有512个MAB,其中包括2048个PE和512个MAU。因此,整个芯片将具有2048个MAB,8192个PE和2048个MAU。不断扩大规模,显然可以实现高性能数字。通常,所有这些单元都以16位工作,尽管结合PE意味着可以实现更高的精度。
责任编辑:pj
-
芯片
+关注
关注
455文章
50711浏览量
423104 -
服务器
+关注
关注
12文章
9123浏览量
85319 -
管芯
+关注
关注
0文章
10浏览量
8177
发布评论请先 登录
相关推荐
名单公布!【书籍评测活动NO.50】亲历芯片产线,轻松图解芯片制造,揭秘芯片工厂的秘密
日本东京ip和子网掩码
合肥高校大学数字孪生可视化系统平台建设项目顺利通过验收
重庆高校大学智能制造实验室数字孪生可视化系统平台建设项目验收
哈尔滨高校大学智能制造实验室数字孪生可视化系统平台项目成功验收
日本初创企业Premo推出创新无线CPU芯片
芯片测试目的和方法有哪些
东京大学中野義昭教授一行莅临中光研究院和光峰科技进行学术交流
SOLIDWORKS教育版使学生了解如何加快设计项目的速度
硬件测试服务项目的重要性和作用

集成芯片内部引脚排列原理
日本研发双足混合机器人,水下行走、急转弯自如
国外大学的FPGA开发项目盘点





 工商网监
工商网监
评论