 文本生成领域一些常见的模型进行了梳理和介绍
文本生成领域一些常见的模型进行了梳理和介绍
本文章对文本生成领域一些常见的模型进行了梳理和介绍。Seq2Seq 是一个经典的文本生成框架,其中的Encoder-Decoder思想贯彻文本生成领域的整个过程。Pointer-Generator Networks是一个生成式文本摘要的模型,其采用的两种经典方法对于其他文本生成领域也有很重要的借鉴价值。SeqGAN模型将强化学习和GAN网络引入到文本生成的过程中,是对文本生成领域的一个方向上的尝试。GPT 对于文本生成领域有重大意义,是在文本生成领域使用预训练模型的一个重大尝试。生成句子是否符合正常语句表达也是文本生成领域的一个重大问题,生成的句子不仅需要没有语法问题,同时符合正常的表达方式和逻辑也是一个很重要的评价指标,最后一节将介绍一种方法来对该指标进行评价。
1 分享内容
介绍 Seq2Seq 模型
介绍 Pointer-Generator Networks模型
介绍 SeqGAN 模型
介绍 GPT-2 预训练模型
介绍如何判断生成句子是否符合正常语句表达
2 Seq2Seq模型介绍
seq2seq 是一个 Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
快乐大本营有一期节目,嘉宾之间依次传话,有趣的是传到后面经常会出现意思完全相反的现象,这个传话可以类比成一个Encoder–Decoder过程。每个人对上一个人的声音会在脑海里面形成一个理解,这个过程类似于Encoder,即将上一个人的声音编码成一个脑海里面形成的理解。最后我们把对脑海里面形成的理解用声音表达出来,这个过程类似于Decoder阶段。
2.1 Seq2Seq 工作流程
Seq2Seq的经典应用场景是机器翻译。如下是 Seq2Seq 模型工作的流程:
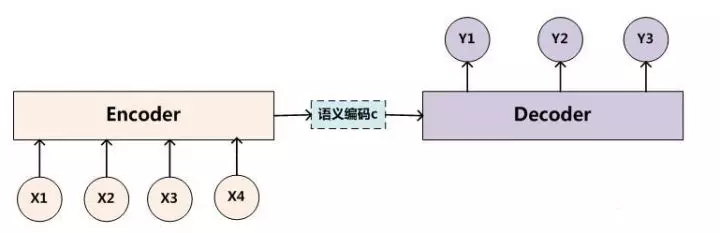
最基础的 Seq2Seq模型 包含了三个部分, Encoder、Decoder 以及连接两者的中间状态向量 C,Encoder通过学习输入,将其编码成一个固定大小的状态向量 C(也称为语义编码),继而将 C 传给Decoder,Decoder再通过对状态向量 C 的学习来进行输出对应的序列。
Encoder和decoder里面包含多个RNN 单元,通常是 LSTM 或者 GRU 。Basic Seq2Seq 有很多弊端的,首先 Encoder 将输入编码为固定大小状态向量(hidden state)的过程实际上是一个“信息有损压缩”的过程。如果信息量越大,那么这个转化向量的过程对信息造成的损失就越大。同时,随着 sequence length的增加,意味着时间维度上的序列很长,RNN 模型也会出现梯度弥散。最后,基础的模型连接 Encoder 和 Decoder 模块的组件仅仅是一个固定大小的状态向量,这使得Decoder无法直接去关注到输入信息的更多细节。
由于 Basic Seq2Seq 的种种缺陷,随后引入了 Attention 的概念,Attention在decoder过程中的每一步,都会给出每个encoder输出的特定权重,然后根据得到权重加权求和,从而得到一个上下文向量,这个上下文向量参与到decoder的输出中,这样大大减少了上文信息的损失,能够取得更好的表现,对于attention如何在Seq2Seq中使用,下一节将会有更加详细的讲解。
3 Pointer-Generator Networks模型
Pointer-Generator Networks 用于生成式文本摘要领域,其相比较于普通的Seq2Seq模型,主要的改点在于
(1) 避免SeqSeq模型在摘要生成时经常出现的重复词现象
(2)解决了OOV现象,即生成的词除了包含上下文已有的词以外,也可以生成上下文中没有的词。
3.1 基线 Seq2Seq+Attention 模型
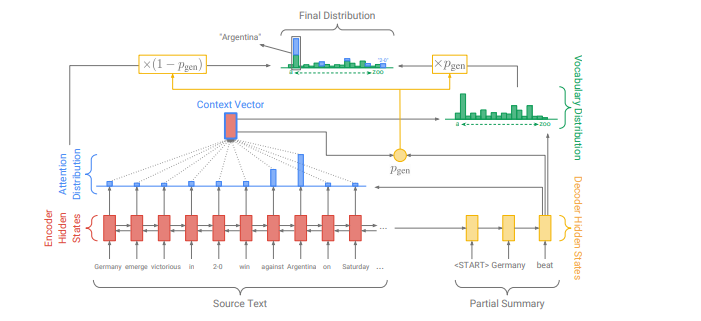
这里是一个标准的attention计算。encoder的第i个hidden_state,是t时刻decoder的状态,是学习参数。attention计算一般有两种方式,第一种方式是先经过decoder单元(LSTM或者GRU,这里使用的LSTM)之后,再使用其输出来计算attention。第二种则表示使用上一个单元(t-1时刻)的hidden_state先计算attention,得到context vector,将其作为t时刻单元的输入。该模型使用的是第二种方式。
(1)
(2)
(3)
利用LSTM单元的输出和context vector()的contact来计算词的概率,并定义其损失函数。
(4)
(5)
(6)
(7)
3.2 Pointer-generator network 网络
增加,区间范围[0,1],表示decoder网络生成一个vocab中的词,还是从原文本中抽取一个词的概率。当>=0.5时,=0,当其小于0.5时,=0。的计算公式如下所示:
(8)
(9)
3.3 Coverage mechanism:
实现方式,在计算t时刻的attention,即context vector 时,不仅仅考虑t时刻的hidden_state, 同时考虑已经生成的内容,这里通过0到t-1刻的attention的权重来体现,权重比较大的词表示已经考虑过了,在后面的计算过程中减少其比重。计算公式:(10)
同时,式(1)中计算权重矩阵的公式也做了相应修改,如式(11)。
(11)
定义了coverage loss,这在实验部分被证明是非常有必要的。关于这个损失函数的定义,取得是当前词前面所有时刻的累计权重和当前时刻权重的最小值,这种方式综合考虑到一个词在文中多次出现和一个词在当前状态最大概率出现的的情况,既不完全偏向于多次出现的词,同时也不过分考虑当前状态最大概率出现的词。
(12)
整体的损失函数:
(13)
4 SeqGAN 模型介绍
核心思想是将GAN与强化学习的Policy Gradient算法结合到一起,这也正是D2IA-GAN在处理Generator的优化时使用的技巧。
SeqGAN的出发点也是意识到了标准的GAN在处理像序列这种离散数据时会遇到的困难,主要体现在两个方面:Generator难以传递梯度更新,Discriminator难以评估非完整序列。
对于前者,给出的解决方案相对比较熟悉,即把整个GAN看作一个强化学习系统,用Policy Gradient算法更新Generator的参数;对于后者,则借鉴了蒙特卡洛树搜索(Monte Carlo tree search,MCTS)的思想,对任意时刻的非完整序列都可以进行评估。
对于强化学习和对抗神经网络在文本生成领域的结合,可以做个简单的类比,从而可以加深对SeqGAN的理解。我们可以将文本生成过程中的生成器,理解成强化学习的策略器,每次选择生成词可以看作是强化学习过程中的动作选择,判别器可以看作是强化学习的环境,其作用是对每次的动作给出相应的反馈。
4.1 SeqGAN 数学推导过程
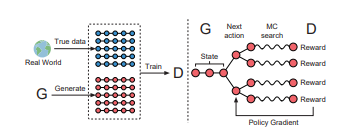
根据强化学习相关知识,我们可以定义SeqGAN的的回报函数。优化过程就是最大化强化学习的回报函数
(1)
由于判别器只能评价一个完成序列,因此可以计算前T-1个序列已经生成的情况下,最后一个动作的Q值。
(2)
但是在强化学习的过程中不仅需要的是最后一个动作的Q值,而且需要任意时刻的Q值,因此,对于一个任意时刻的Q值,可以通过MC采样的方式来进行近似计算,MC会采样多个完整的序列,通过计算采样后的完整序列回报的均值,当作当前时刻的Q值。
(3)
判别器的训练,判别器的训练目标是给出真实样本和生成样本的分数,目标是最大化真实样本的分数,最小化生成样本的分数,下面是其损失函数的公式。
(4)
将(1)中的公式展开成按照时间累计求和的形式,可以得到下面的的公式
(5)
将任意时刻的期望回报用累计回报近似代替,可以得到下面公式。
(6)
利用反向传播更新生成器的参数。
(7)
4.2 SeqGAN缺点
SeqGAN模型主要耗时操作是在MC的采样过程,因为对于每一个时刻的累计回报都是通过采样的方式的进行估算近似,当需要生成的序列比较长时,采样需要的次数会急速的增长。同时当采样次数比较少的情况下,近似估计的结果会偏差较大。
5 GPT-2 预训练模型
bert 模型虽然在文本分类领域取得了惊人的效果,但是考虑到BERT是一个双向语言模型,充分利用了上下文信息,所以在文本分类领域效果优于GPT无可厚非,但是BERT模型也正是因为双向的语言模型的特点,导致其在文本生成领域表现不佳。由于文本生成本身的特性,每次生成时候,只能看见上文,并不能看见下文,所以并不适合双向的语言模型。GPT-2在文本生成领域的惊人表现,让我们不禁想要去探索,是因为什么使得GPT-2在本文生成领域表现如此强力,下面我们对比BERT模型来详细介绍GPT-2。
从结构上来说GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。二者一个很关键的不同之处在于:GPT-2 就像传统的语言模型一样,一次只输出一个单词(token)。这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归(auto-regression),同时也是令 GPT-2模型效果拔群的重要思想。
GPT-2,以及一些诸如 TransformerXL 和 XLNet 等后续出现的模型,本质上都是自回归模型,而 BERT 则不然。这就是一个权衡的问题了。虽然没有使用自回归机制,但 BERT 获得了结合单词前后的上下文信息的能力,从而取得了更好的效果。XLNet 使用了自回归,并且引入了一种能够同时兼顾前后的上下文信息的方法。
5.1 带掩码的注意力模型
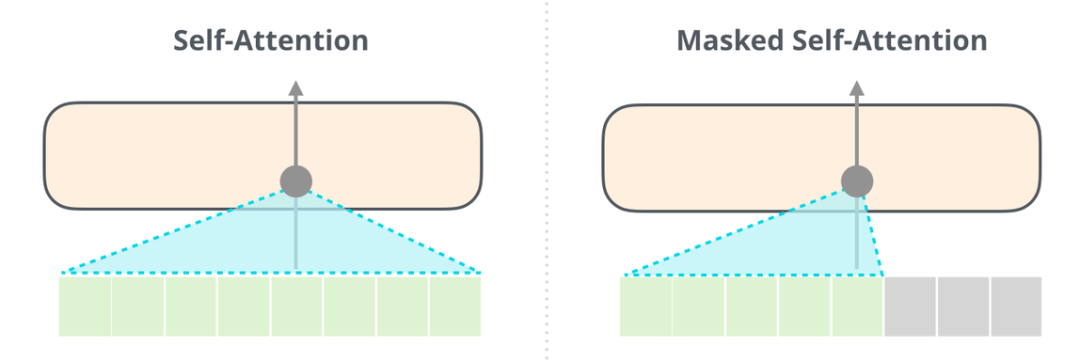
能够清楚地区分 BERT 使用的自注意力(self-attention)模块和 GPT-2 使用的带掩码的自注意力(masked self-attention)模块很重要。普通的自注意力模块允许一个位置看到它右侧单词的信息(如下左图),而带掩码的自注意力模块则不允许这么做,他会将该词后面的词通过掩码的方式将其屏蔽掉。
利用掩码方式一个最大的优势在于,我们后续的注意力机制模块,可以通过矩阵运算的方式直接进行,大大优化了计算效率。
5.2 只包含解码器的模块
这些解码器模块和 transformer 原始论文中的解码器模块相比,并没有很大的差别,仅仅只是将第二层的自注意力层给去掉,原本的自注意力层中,会把encoder层的输出和上一层的结果进行注意力计算。但是GPT-2使用的是循环结构,每次把新生成的词添加到原有的序列后面,然后再重新参与计算。通过这种方式,将encoder给去掉了。这样OpenAI 的 GPT-2 模型就用了这种只包含编码器(decoder-only)的模块。
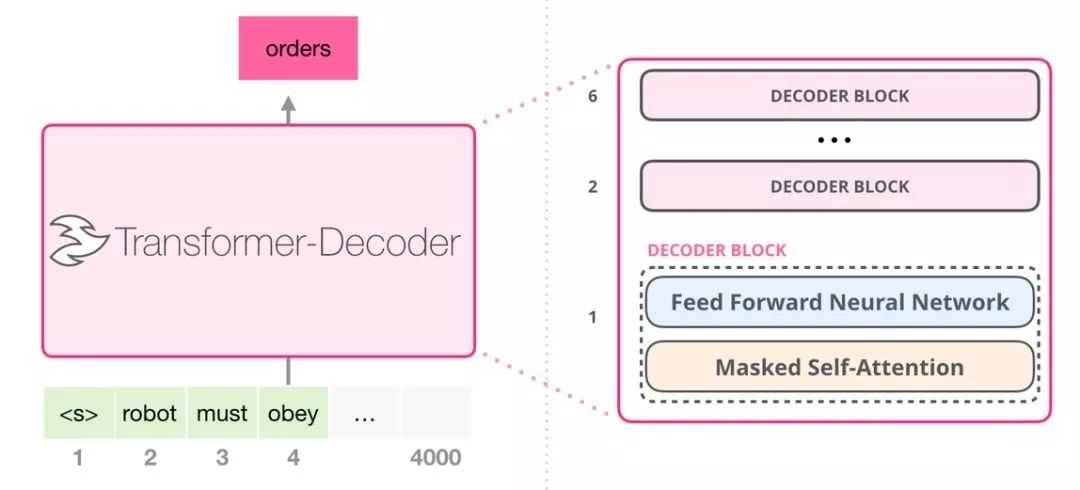
5.3 GPT-2 内部生成机制
给定GPT-2一点提示,然后GPT-2根据提示开始进行生成,每次只能生成一个单词,然后将生成的单词加入到提示中,层层开始处理,最终生成一个完整的序列。但是会存在一个问题,每次选择第一个单词,这样的生成序列变成唯一了,只有选择第二个或者第三个推荐词以后,才能跳出唯一的现象,因此GPT-2有一个top-k参数,模型会从概率前k大的单词中选择下一个单词。
6 如何判断生成句子是否符合正常语句表达
在我们生成的句子中,总是存在一些句子看起来通顺,但是实际并没有意义,或者存在逻辑错误。比如“北京是新中国的首都”,这句话是没有问题的,但是我们将北京替换成南京,显然这样的句子并没有语法错误,但是如果生成的句子是这样的话,很可能会被请去喝茶。
句子符合正常语句表达,对于机器而言我们应该怎么评价呢,显然,如果我们注意到新中国、首都这两个词,那么我们能够很快判断出现北京明显比南京更加常见。按照这个思想,可以把这个问题换个角度来描述,我们是希望在前面词出现的条件下,后续词出现的概率应该最大,并且后面词出现的前提下,前面词出现的概率也应该最大。
6.1 模型损失函数
对于一个给定的序列Y{}我们可以定义其损失为:
其中对于Loss函数而言是一个超参数,我们可以通过调整其来达到一个更好的效果,通常而言,根据总体序列的长度来选择一个合理的。
6.2 判别模型的选择
当序列比较长时,推荐使用Transform结构模型,考虑到长文本需要预测的次数比较多,Transform比起RNN结构更加有利于并行运算,速度会更快。
-
模型
+关注
关注
1文章
3226浏览量
48804 -
文本
+关注
关注
0文章
118浏览量
17082 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:AI也能精彩表达:几种经典文本生成模型一览
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
分享一些常见的电路

如何训练自己的LLM模型
如何使用 Llama 3 进行文本生成
如何评估AI大模型的效果
AI大模型在自然语言处理中的应用
【《大语言模型应用指南》阅读体验】+ 基础知识学习
llm模型本地部署有用吗
llm模型和chatGPT的区别
生成式AI的基本原理和应用领域
Chrome浏览器新增Gemini Nano,实现文本生成等本地功能
【大语言模型:原理与工程实践】揭开大语言模型的面纱
讯飞星火大模型V3.5春季升级,多领域知识问答超越GPT-4 Turbo
OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径
高级检索增强生成技术(RAG)全面指南





 工商网监
工商网监
评论