 ShardingSphere的框架及应用解决方案
ShardingSphere的框架及应用解决方案
一、NewSQL的概念
NewSQL的概念,最开始来源于国外的一份商业分析报告。它是各种新的可扩展/高性能数据库的简称,这类数据库不仅具有NoSQL海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。
提及SQL,很多朋友最先想到的就是MySQL数据库和PostgreSQL数据库。对我们来说,它其实一个单点、很可靠,有ACID事务,也有查询语言的关系型数据库。其中,ACID事务和查询语言是我们最关心的两点。
伴随互联网的蓬勃发展,数据量的持续膨胀,NoSQL出现了。NoSQL泛指非关系型数据库,具备Scalability(扩展性)和Resilience(弹性)。扩展性是指可以无限的把一个单点变成一个集群,从而提升整个系统的可用性。弹性保证了在宕机集群崩溃后,数据的自动修复且上层业务无感知。
那么就有人提出来了,我能不能既可以拥有像SQL的关系模型,拥有它的ACID事务,同时还拥有像NoSQL的扩展性、弹性伸缩,以及高可用性。于是,NewSQL应运而生,它最开始的定义就叫做Scalability SQL。
在分布式的场景中,没有办法同时保证Consistency(一致性)和Availability(可用性),以及分区的容错性。CAP原则就是,你只能保证整个系统更关注于强一致性,或者高可用性。
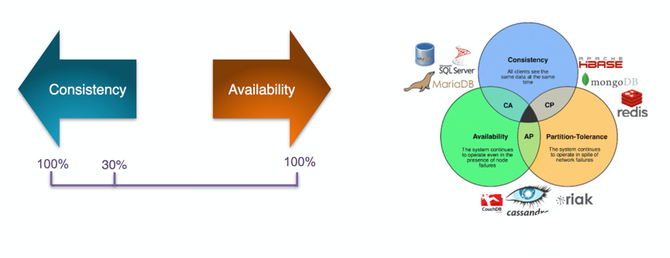
综上所述,NewSQL是为了综合SQL和NoSQL的特性。它的存在并不是完全颠覆了CAP理论,而是需要基于这套理论,根据我们自身的实际情况,选择一个Consistency和Availability之间的平衡点。
对于用户来说,NewSQL其实就是A single logical DB,即单个逻辑数据库。从开发的角度,NewSQL具有New Architecture(新架构)、Transparent Sharding(透明化分片中间件)、Database as a Service(云数据库)三种形态。
二、Apache ShardingSphere的架构
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由JDBC、Proxy和Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于Java同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。Apache ShardingSphere目前已提供数十个SPI作为系统的扩展点,仍在不断增加中。

如上图所示,这是Apache ShardingSphere最新的部署框架。Apache ShardingSphere最开始定位于NewSQL的中间件,后面它的盘子越来越大,逐渐超越了中间件的范畴,但又未达到新架构的范畴,处在一个中间的状态。
首先,中间件的数据库集群,可能有自己的主库或者从库,包括同步、复制、备份等都是靠MySQL或者PG数据库来实现的。
其次,用户真正能够接触三个产品,第一个产品叫ShardingSphere-JDBC,它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它具备解析SQL、分片管理、分布式事务,脱敏等功能。
第二个产品叫ShardingSphere-Proxy,定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。适用于任何兼容MySQL/PostgreSQL协议的的客户端,可以管理数据库集群。
三、功能介绍
仔细观察ShardingSphere的框架,我们不难发现中间件左侧的Sharding-Scaling,它是一个提供给用户的通用的ShardingSphere数据接入迁移,及弹性伸缩的调度平台。
JDBC的核心功能就是Orchestration,即编排治理,配置集中化与动态化、数据治理。ShardingSphere提供了界面治理模块——Sharding-UI,可以快速维护Sharding-Proxy集群,方便用户一键式的操作。
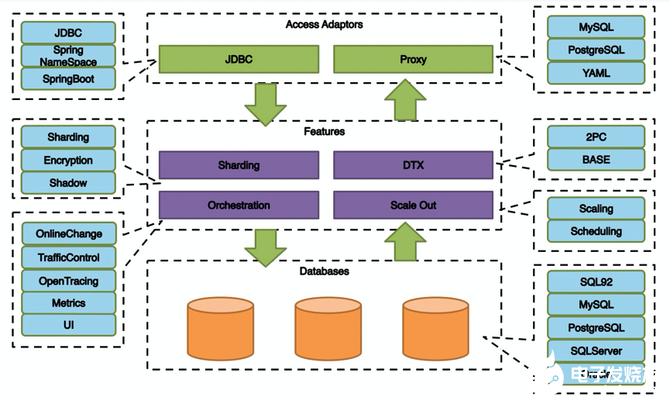
如上图所示,从研发的角度来看Apache ShardingSphere的框架,最上面的接入端有JDBC和Proxy,中间层的核心功能是数据分片、分布式事务、数据库治理,最下层是数据库集群。

其实,Sharding是Apache ShardingSphere的立足之本。除了分库分表,它还还支持Encrypt(脱敏)和Shadow(影子库),所有压测的数据都会分配的影子库中。Sharding最核心的还是底层四个模块来做支撑。
我们必须要解析SQL,才能理解用户需要什么。Parser(解析器)已经重构过很多遍,为了实现自主可控,保证高效性和正确性。除此之外,Router代表着路由,Rewriter改写一些SQL,Executor做并行的控制,提高整体效率。

分布式事务主要有两个方面,ACID强一致性事务和BASE柔性事务。值得一提的是,ShardingSphere分为自研的分布式数据库(DTX)、对接其他公司的解决方案两部分。对于用户来说,他无需过多了解ShardingSphere,就可以拥有多种分布式事务的选型,这其实是一种非常有意思的方式。

ShardingSphere不只是一个分布式数据库的原因在于,它的Orchestration模块提供了很多功能,比如在线变更、分片规则的在线推送,以及限流和熔断等。用户在了解分片的基础上,可以慢慢去探索这个开放生态,找到自己想要的功能。
潘娟强调道,分库分表、强一致事务、柔性事务、分布式治理、可视化链路追踪、读写分离等所有的功能都是可以组合在一起的。完全的自由组合,从而形成一个只满足公司所需要的产品。

当存储系统或者性能不够的时候,数据库就要通过Scaling(迁移平台)进行Scale out(扩展)。目标不是放在提高单机性能上,而是要做成分布式,多个机器来解决。
四、社区
-
互联网
+关注
关注
54文章
11148浏览量
103211 -
数据库
+关注
关注
7文章
3794浏览量
64352
发布评论请先 登录
相关推荐
SSM开发中的常见问题及解决方案
SSM框架的优缺点分析 SSM在移动端开发中的应用
晶科储能与嘉实多签署战略合作框架协议

解决方案 | 基于TSMaster的平板电脑解决方案

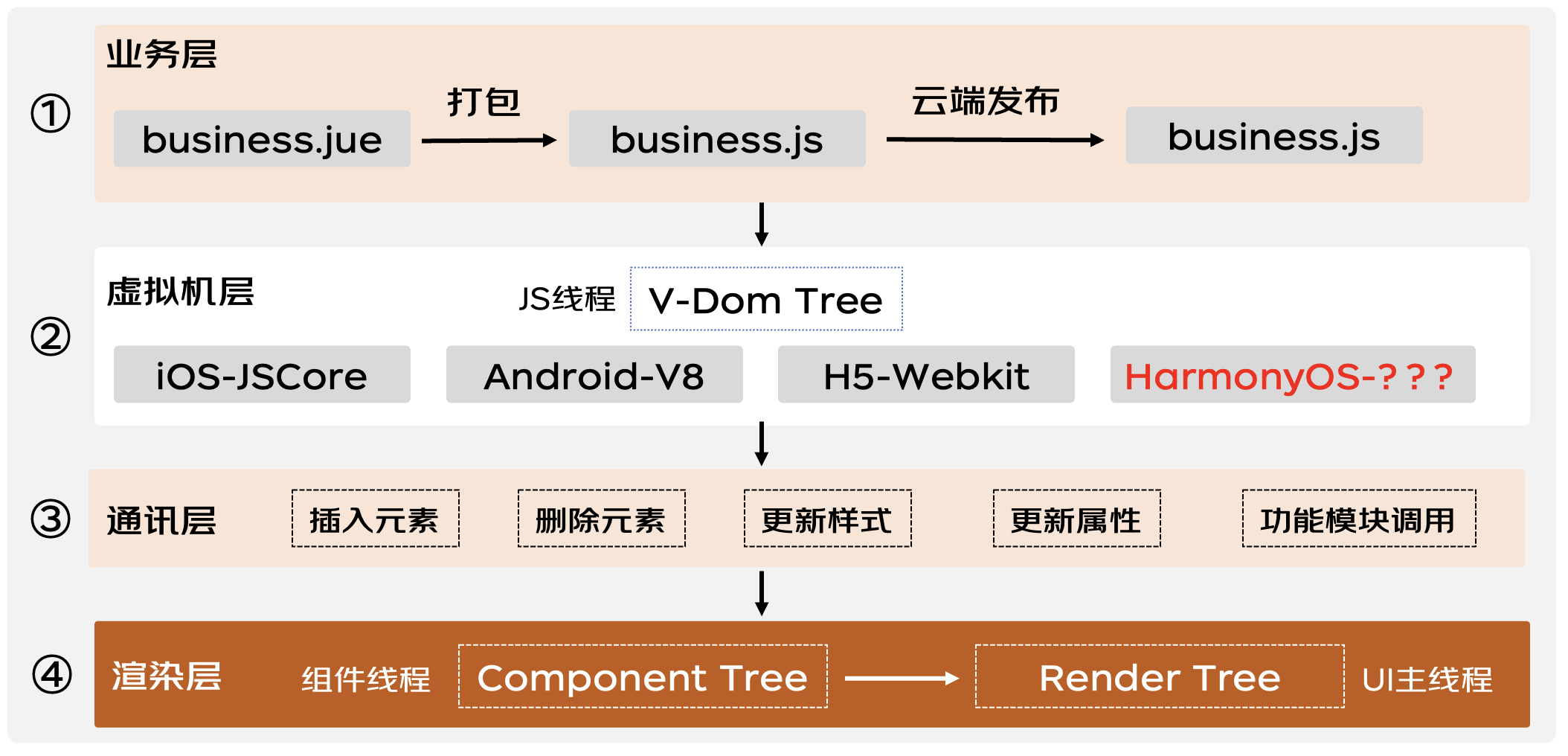
揭秘动态化跨端框架在鸿蒙系统下的高性能解决方案
BCM中的开关检测:集成MSDI解决方案与半分立解决方案






 工商网监
工商网监
评论