 从 Linux 内核的角度谈线程栈和进程栈
从 Linux 内核的角度谈线程栈和进程栈
1.进程栈
进程栈是属于用户态栈,和进程虚拟地址空间(Virtual Address Space)密切相关。那我们先了解下什么是虚拟地址空间:在32位机器下,虚拟地址空间大小为4G。这些虚拟地址通过页表(Page Table)映射到物理内存,页表由操作系统维护,并被处理器的内存管理单元(MMU)硬件引用。每个进程都拥有一套属于它自己的页表,因此对于每个进程而言都好像独享了整个虚拟地址空间。
Linux内核将这4G字节的空间分为两部分,将最高的1G字节(0xC0000000-0xFFFFFFFF)供内核使用,称为内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
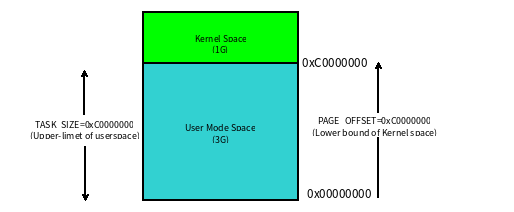
Linux对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成(Memory Segment),主要的内存段如下:
-程序段(Text Segment):可执行文件代码的内存映射
-数据段(Data Segment):可执行文件的已初始化全局变量的内存映射
- BSS段(BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
-堆区(Heap) :存储动态内存分配,匿名的内存映射
-栈区(Stack) :进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
-映射段(Memory Mapping Segment):任何内存映射文件
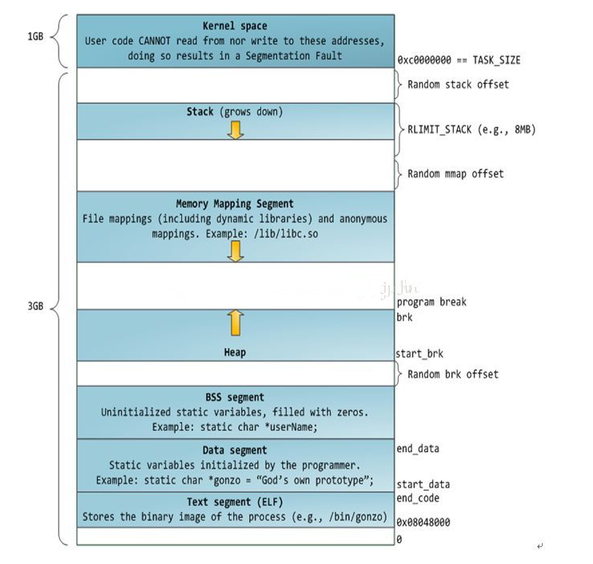
而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制RLIMIT_STACK (一般为8M),我们可以通过ulimit来查看或更改RLIMIT_STACK的值。
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个缺页异常(page fault)。通过异常陷入内核态后,异常会被内核的expand_stack()函数处理,进而调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
2.线程栈
从Linux内核的角度来说,其实它并没有线程的概念。Linux把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了task_struct中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和Linux中所谓线程的唯一区别。线程创建的时候,加上了CLONE_VM标记,这样线程的内存描述符将直接指向父进程的内存描述符。
点击(此处)折叠或打开
if(clone_flags&CLONE_VM){
/*
*current 是父进程而 tsk 在 fork()执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm=current->mm;
}
虽然线程的地址空间和进程一样,但是对待其地址空间的stack还是有些区别的。对于Linux进程或者说主线程,其stack是在fork的时候生成的,实际上就是复制了父亲的stack空间地址,然后写时拷贝(cow)以及动态增长。然而对于主线程生成的子线程而言,其stack将不再是这样的了,而是事先固定下来的,使用mmap系统调用(实际上是进程的堆的一部分),它不带有VM_STACK_FLAGS标记。这个可以从glibc的nptl/allocatestack.c中的allocate_stack()函数中看到:
点击(此处)折叠或打开
mem=mmap(NULL,size,prot,MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK,-1,0);
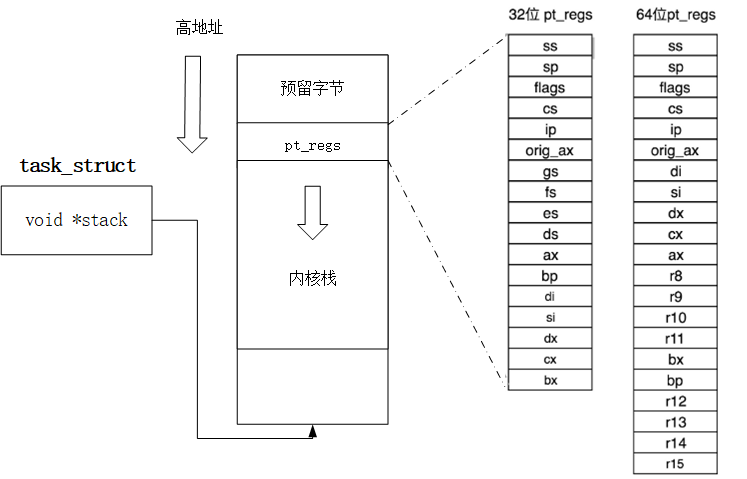
由于线程的mm->start_stack栈地址和所属进程相同,所以线程栈的起始地址并没有存放在task_struct中,应该是使用pthread_attr_t中的stackaddr来初始化task_struct->thread->sp(sp指向struct pt_regs对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的fork不同的地方。由于线程栈是从进程的地址空间中map出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的task_struct的很多字段,其中包括所有的vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
3.进程栈和线程栈大小的调整
进程和线程的栈分别是多大呢?首先从我们熟悉的ulimit -s说起,熟悉linux的人都应该知道通过ulimit -s可以修改栈的大小,除此之外还有getrlimit/setrlimit两个函数:
点击(此处)折叠或打开
intgetrlimit(intresource,struct rlimit*rlim);
intsetrlimit(intresource,conststruct rlimit*rlim);
这两个函数当第一个参数传入RLIMIT_STACK时,可以设置和获取栈的大小,其作用和ulimit -s是一样的,只是单位不同,ulimit -s的单位是kB,而这两个函数的单位是B(字节),详细使用方法请参考man手册。
最后还有线程的pthread_attr_setstacksize/pthread_attr_getstacksize。
使用setrlimit和使用ulimit -s设置栈大小效果相同,这两种方式都是针对进程栈大小设置,只不过前者只真对当前进程,后者针对当前shell;
而线程栈大小的关系就相对比较复杂点,前文说过线程大小是静态的,是在创建时就确定了的,当然如果使用pthread_attr_setstacksize可以在创建线程时指定线程栈大小,但如果不指定线程栈的话其默认大小是什么情况呢?想要了解线程栈的大小就要看glibc的线程创建函数,具体就是pthread_create->__pthread_create_2_1->allocate_stack。具体代码还是比较复杂的,这里简化为一个伪代码:
点击(此处)折叠或打开
limit=getlimit(RLIMIT_STACK)
if(limit==RLIMIT_INFINITY)
thread.rlimit=ARCH_STACK_DEFAULT_SIZE//2M
elseifthread.rlimit< PTHREAD_STACK_MIN //16k
thread.rlimit=PTHREAD_STACK_MIN
可以看出,线程默认栈大小和进程栈大小的关系:
1)如果ulimit(setrlimit)设置大小大于16k,则线程栈默认大小由ulimit(setrlimit)决定;
2)如果ulimit(setrlimit)设置大小小于16k,则线程栈默认大小为16;
3)如果ulimit(setrlimit)设置大小为无限制,则线程栈默认大小为2M;
所以我们如果使用ulimit设置进程栈大小是无限大其实栈大小反而相对比较小,这是为什么呢?前面我们已经讲过线程栈和进程栈的位置不同,线程栈其实是在进程的堆上分配的,并且不会动态增加,所以不可能设置一个无限大小的线程栈。
最后,我们再对进程栈和线程栈做一下总结和说明:
(1)ulimit -s决定进程栈的大小,但不是严格相等(实际测试稍大于ulimit -s设置);
(2)创建线程时如果通过pthread_attr_setstacksize设置了线程栈大小,则使用该属性创建的线程栈大小就为其设置的值,但不影响线程默认属性的栈大小值,也不影响ulimit -s的值。
(3)线程一旦创建就无法在修改其栈大小了,即使使用setrlimit。
(4)pthread_attr_setstacksize/pthread_attr_getstacksize的作用是获取和设置线程属性中的栈大小的,而不获取设置线程栈大小的。可以再创建前设置好线程属性,这样使用该属性创建线程就能影响线程的栈大小了。但通过pthread_attr_init,pthread_attr_getstacksize是无法获取当前线程栈大小的,只能获取默认属性的线程栈大小,其值未必就是当前线程栈大小。
-
Linux
+关注
关注
87文章
11292浏览量
209318 -
线程
+关注
关注
0文章
504浏览量
19675 -
内存映射
+关注
关注
0文章
14浏览量
7415 -
进程
+关注
关注
0文章
203浏览量
13960
发布评论请先 登录
相关推荐
Linux网络栈原理与实现
有关Linux系统的PBC (进程控制块)基础知识介绍
基于STM32的虚拟多线程(TI_BLE协议栈_ZStack协议栈)
一文详解Linux内核的栈回溯与妙用

对Linux的进程内核栈的认识
Linux下线程与进程的区别
Linux中的进程栈、线程栈、内核栈以及中断栈
linux中的进程栈,线程栈,内核栈的区别
ethernetif_input和tcpip协议栈线程的作用
Linux网络协议栈的实现





 工商网监
工商网监
评论