 使用Softmax的信息来教学 —— 知识蒸馏
使用Softmax的信息来教学 —— 知识蒸馏
导读
从各个层次给大家讲解模型的知识蒸馏的相关内容,并通过实际的代码给大家进行演示。
公众号后台回复“模型蒸馏”,下载已打包好的代码。
本报告讨论了非常厉害模型优化技术 —— 知识蒸馏,并给大家过了一遍相关的TensorFlow的代码。
“模型集成是一个相当有保证的方法,可以获得2%的准确性。“ —— Andrej Karpathy
我绝对同意!然而,部署重量级模型的集成在许多情况下并不总是可行的。有时,你的单个模型可能太大(例如GPT-3),以至于通常不可能将其部署到资源受限的环境中。这就是为什么我们一直在研究一些模型优化方法 ——量化和剪枝。在这个报告中,我们将讨论一个非常厉害的模型优化技术 —— 知识蒸馏。
Softmax告诉了我们什么?
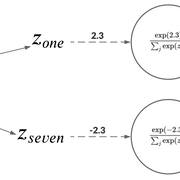
当处理一个分类问题时,使用softmax作为神经网络的最后一个激活单元是非常典型的用法。这是为什么呢?因为softmax函数接受一组logit为输入并输出离散类别上的概率分布。比如,手写数字识别中,神经网络可能有较高的置信度认为图像为1。不过,也有轻微的可能性认为图像为7。如果我们只处理像[1,0]这样的独热编码标签(其中1和0分别是图像为1和7的概率),那么这些信息就无法获得。
人类已经很好地利用了这种相对关系。更多的例子包括,长得很像猫的狗,棕红色的,猫一样的老虎等等。正如Hinton等人所认为的
一辆宝马被误认为是一辆垃圾车的可能性很小,但被误认为是一个胡萝卜的可能性仍然要高很多倍。
这些知识可以帮助我们在各种情况下进行极好的概括。这个思考过程帮助我们更深入地了解我们的模型对输入数据的想法。它应该与我们考虑输入数据的方式一致。
所以,现在该做什么?一个迫在眉睫的问题可能会突然出现在我们的脑海中 —— 我们在神经网络中使用这些知识的最佳方式是什么?让我们在下一节中找出答案。
使用Softmax的信息来教学 —— 知识蒸馏
softmax信息比独热编码标签更有用。在这个阶段,我们可以得到:
训练数据
训练好的神经网络在测试数据上表现良好
我们现在感兴趣的是使用我们训练过的网络产生的输出概率。
考虑教人去认识MNIST数据集的英文数字。你的学生可能会问 —— 那个看起来像7吗?如果是这样的话,这绝对是个好消息,因为你的学生,肯定知道1和7是什么样子。作为一名教师,你能够把你的数字知识传授给你的学生。这种想法也有可能扩展到神经网络。
知识蒸馏的高层机制
所以,这是一个高层次的方法:
训练一个在数据集上表现良好神经网络。这个网络就是“教师”模型。
使用教师模型在相同的数据集上训练一个学生模型。这里的问题是,学生模型的大小应该比老师的小得多。
本工作流程简要阐述了知识蒸馏的思想。
为什么要小?这不是我们想要的吗?将一个轻量级模型部署到生产环境中,从而达到足够的性能。
用图像分类的例子来学习
对于一个图像分类的例子,我们可以扩展前面的高层思想:
训练一个在图像数据集上表现良好的教师模型。在这里,交叉熵损失将根据数据集中的真实标签计算。
在相同的数据集上训练一个较小的学生模型,但是使用来自教师模型(softmax输出)的预测作为ground-truth标签。这些softmax输出称为软标签。稍后会有更详细的介绍。
我们为什么要用软标签来训练学生模型?
请记住,在容量方面,我们的学生模型比教师模型要小。因此,如果你的数据集足够复杂,那么较小的student模型可能不太适合捕捉训练目标所需的隐藏表示。我们在软标签上训练学生模型来弥补这一点,它提供了比独热编码标签更有意义的信息。在某种意义上,我们通过暴露一些训练数据集来训练学生模型来模仿教师模型的输出。
希望这能让你们对知识蒸馏有一个直观的理解。在下一节中,我们将更详细地了解学生模型的训练机制。
知识蒸馏中的损失函数
为了训练学生模型,我们仍然可以使用教师模型的软标签以及学生模型的预测来计算常规交叉熵损失。学生模型很有可能对许多输入数据点都有信心,并且它会预测出像下面这样的概率分布:
高置信度的预测
扩展Softmax
这些弱概率的问题是,它们没有捕捉到学生模型有效学习所需的信息。例如,如果概率分布像[0.99, 0.01],几乎不可能传递图像具有数字7的特征的知识。
Hinton等人解决这个问题的方法是,在将原始logits传递给softmax之前,将教师模型的原始logits按一定的温度进行缩放。这样,就会在可用的类标签中得到更广泛的分布。然后用同样的温度用于训练学生模型。
我们可以把学生模型的修正损失函数写成这个方程的形式:
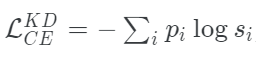
其中,pi是教师模型得到软概率分布,si的表达式为: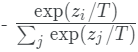
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) returnkd_loss
使用扩展Softmax来合并硬标签
Hinton等人还探索了在真实标签(通常是独热编码)和学生模型的预测之间使用传统交叉熵损失的想法。当训练数据集很小,并且软标签没有足够的信号供学生模型采集时,这一点尤其有用。
当它与扩展的softmax相结合时,这种方法的工作效果明显更好,而整体损失函数成为两者之间的加权平均。
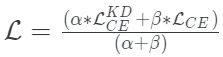
defget_kd_loss(student_logits,teacher_logits, true_labels,temperature, alpha,beta): teacher_probs=tf.nn.softmax(teacher_logits/temperature) kd_loss=tf.keras.losses.categorical_crossentropy( teacher_probs,student_logits/temperature, from_logits=True) ce_loss=tf.keras.losses.sparse_categorical_crossentropy( true_labels,student_logits,from_logits=True) total_loss=(alpha*kd_loss)+(beta*ce_loss) returntotal_loss/(alpha+beta)
建议β的权重小于α。
在原始Logits上进行操作
Caruana等人操作原始logits,而不是softmax值。这个工作流程如下:
这部分保持相同 —— 训练一个教师模型。这里交叉熵损失将根据数据集中的真实标签计算。
现在,为了训练学生模型,训练目标变成分别最小化来自教师和学生模型的原始对数之间的平均平方误差。

mse=tf.keras.losses.MeanSquaredError() defmse_kd_loss(teacher_logits,student_logits): returnmse(teacher_logits,student_logits)
使用这个损失函数的一个潜在缺点是它是无界的。原始logits可以捕获噪声,而一个小模型可能无法很好的拟合。这就是为什么为了使这个损失函数很好地适合蒸馏状态,学生模型需要更大一点。
Tang等人探索了在两个损失之间插值的想法:扩展softmax和MSE损失。数学上,它看起来是这样的:
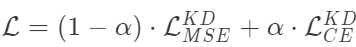
根据经验,他们发现当α = 0时,(在NLP任务上)可以获得最佳的性能。
如果你在这一点上感到有点不知怎么办,不要担心。希望通过代码,事情会变得清楚。
一些训练方法
在本节中,我将向你提供一些在使用知识蒸馏时可以考虑的训练方法。
使用数据增强
他们在NLP数据集上展示了这个想法,但这也适用于其他领域。为了更好地指导学生模型训练,使用数据增强会有帮助,特别是当你处理的数据较少的时候。因为我们通常保持学生模型比教师模型小得多,所以我们希望学生模型能够获得更多不同的数据,从而更好地捕捉领域知识。
使用标记的和未标记的数据训练学生模型
在像Noisy Student Training和SimCLRV2这样的文章中,作者在训练学生模型时使用了额外的未标记数据。因此,你将使用你的teacher模型来生成未标记数据集上的ground-truth分布。这在很大程度上有助于提高模型的可泛化性。这种方法只有在你所处理的数据集中有未标记数据可用时才可行。有时,情况可能并非如此(例如,医疗保健)。Xie等人探索了数据平衡和数据过滤等技术,以缓解在训练学生模型时合并未标记数据可能出现的问题。
在训练教师模型时不要使用标签平滑
标签平滑是一种技术,用来放松由模型产生的高可信度预测。它有助于减少过拟合,但不建议在训练教师模型时使用标签平滑,因为无论如何,它的logits是按一定的温度缩放的。因此,一般不推荐在知识蒸馏的情况下使用标签平滑。
使用更高的温度值
Hinton等人建议使用更高的温度值来soften教师模型预测的分布,这样软标签可以为学生模型提供更多的信息。这在处理小型数据集时特别有用。对于更大的数据集,信息可以通过训练样本的数量来获得。
实验结果
让我们先回顾一下实验设置。我在实验中使用了Flowers数据集。除非另外指定,我使用以下配置:
我使用MobileNetV2作为基本模型进行微调,学习速度设置为1e-5,Adam作为优化器。
我们将τ设置为5。
α = 0.9,β = 0.1。
对于学生模型,使用下面这个简单的结构:
Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 222, 222, 64) 1792 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 55, 55, 64) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 53, 53, 128) 73856 _________________________________________________________________ global_average_pooling2d_3 ( (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 512) 66048 _________________________________________________________________ dense_4 (Dense) (None, 5) 2565 =================================================================
在训练学生模型时,我使用Adam作为优化器,学习速度为1e-2。
在使用数据增强训练student模型的过程中,我使用了与上面提到的相同的默认超参数的加权平均损失。
学生模型基线
为了使性能比较公平,我们还从头开始训练浅的CNN并观察它的性能。注意,在本例中,我使用Adam作为优化器,学习速率为1e-3。
训练循环
在看到结果之前,我想说明一下训练循环,以及如何在经典的model.fit()调用中包装它。这就是训练循环的样子:
deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"loss":t_loss,"accuracy":t_acc}
如果你已经熟悉了如何在TensorFlow 2中定制一个训练循环,那么train_step()函数应该是一个容易阅读的函数。注意get_kd_loss() 函数。这可以是我们之前讨论过的任何损失函数。我们在这里使用的是一个训练过的教师模型,这个模型我们在前面进行了微调。通过这个训练循环,我们可以创建一个可以通过.fit()调用进行训练完整模型。
首先,创建一个扩展tf.keras.Model的类。
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student
当你扩展tf.keras.Model 类的时候,可以将自定义的训练逻辑放到train_step()函数中(由类提供)。所以,从整体上看,Student类应该是这样的:
classStudent(tf.keras.Model): def__init__(self,trained_teacher,student): super(Student,self).__init__() self.trained_teacher=trained_teacher self.student=student deftrain_step(self,data): images,labels=data teacher_logits=self.trained_teacher(images) withtf.GradientTape()astape: student_logits=self.student(images) loss=get_kd_loss(teacher_logits,student_logits) gradients=tape.gradient(loss,self.student.trainable_variables) self.optimizer.apply_gradients(zip(gradients,self.student.trainable_variables)) train_loss.update_state(loss) train_acc.update_state(labels,tf.nn.softmax(student_logits)) t_loss,t_acc=train_loss.result(),train_acc.result() train_loss.reset_states(),train_acc.reset_states() return{"train_loss":t_loss,"train_accuracy":t_acc}
你甚至可以编写一个test_step来自定义模型的评估行为。我们的模型现在可以用以下方式训练:
student=Student(teacher_model,get_student_model()) optimizer=tf.keras.optimizers.Adam(learning_rate=0.01) student.compile(optimizer) student.fit(train_ds, validation_data=validation_ds, epochs=10)
这种方法的一个潜在优势是可以很容易地合并其他功能,比如分布式训练、自定义回调、混合精度等等。
使用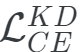 训练学生模型
训练学生模型
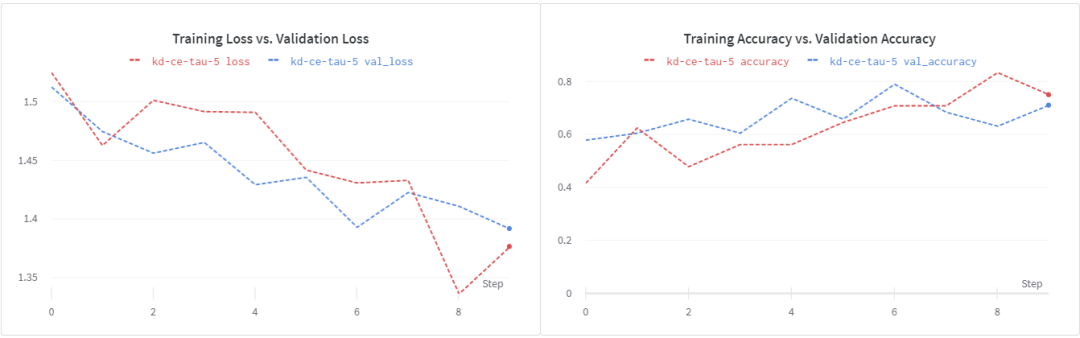
用这个损失函数训练我们的浅层学生模型,我们得到~74%的验证精度。我们看到,在epochs 8之后,损失开始增加。这表明,加强正则化可能会有所帮助。另外,请注意,超参数调优过程在这里有重大影响。在我的实验中,我没有做严格的超参数调优。为了更快地进行实验,我缩短了训练时间。
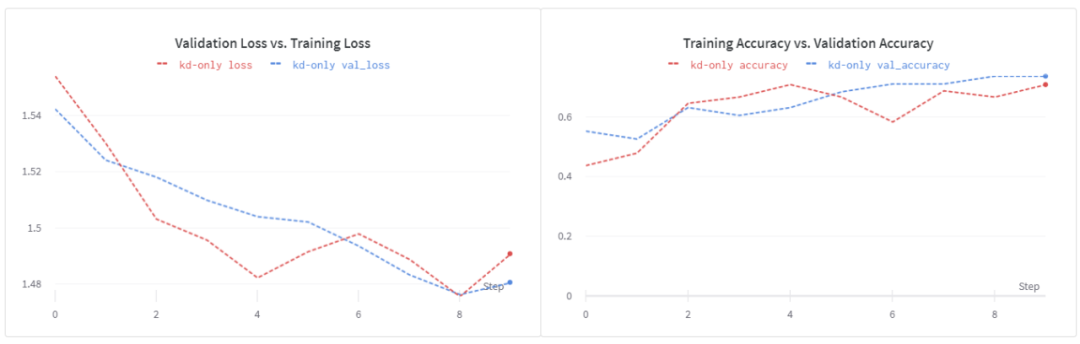
使用
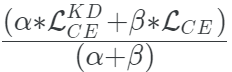
训练学生模型
现在让我们看看在蒸馏训练目标中加入ground truth标签是否有帮助。在β = 0.1和α = 0.1的情况下,我们得到了大约71%的验证准确性。再次表明,更强的正则化和更长的训练时间会有所帮助。
使用 训练学生模型
训练学生模型
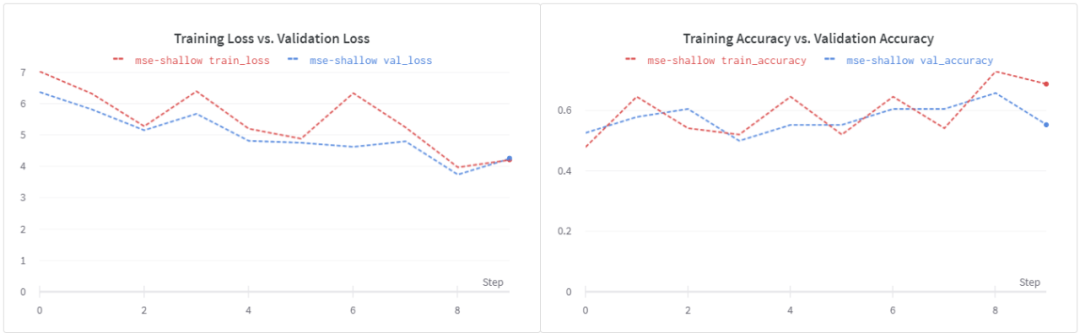
使用了MSE的损失,我们可以看到验证精度大幅下降到~56%。同样的损失也出现了类似的情况,这表明需要进行正则化。
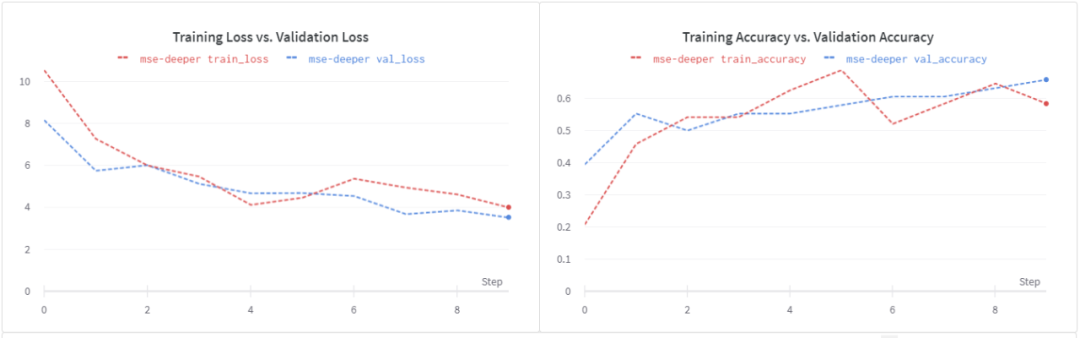
请注意,这个损失函数是无界的,我们的浅学生模型可能无法处理随之而来的噪音。让我们尝试一个更深入的学生模型。
在训练学生模型的时候使用数据增强
如前所述,学生模式比教师模式的容量更小。在处理较少的数据时,数据增强可以帮助训练学生模型。我们验证一下。
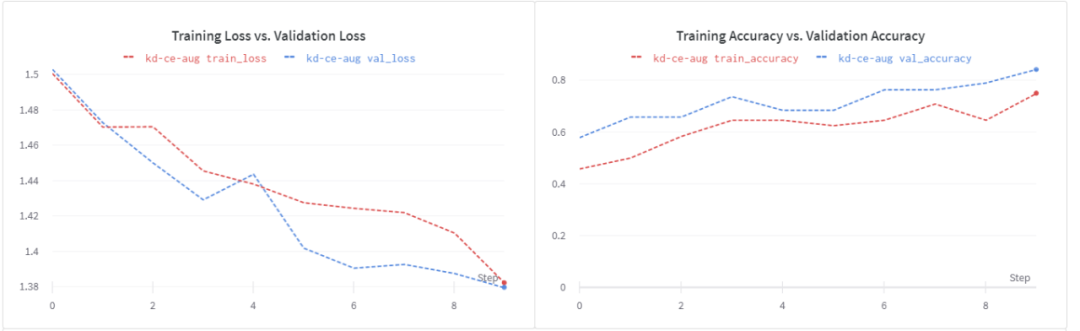
数据增加的好处是非常明显的:
我们有一个更好的损失曲线。
验证精度提高到84%。
温度(τ)的影响
在这个实验中,我们研究温度对学生模型的影响。在这个设置中,我使用了相同的浅层CNN。
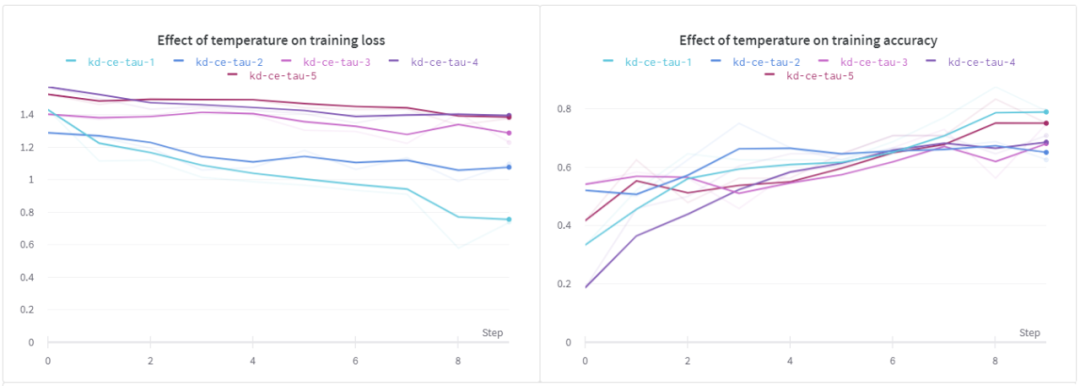
从上面的结果可以看出,当τ为1时,训练损失和训练精度均优于其它方法。对于验证损失,我们可以看到类似的行为,但是在所有不同的温度下,验证的准确性似乎几乎是相同的。
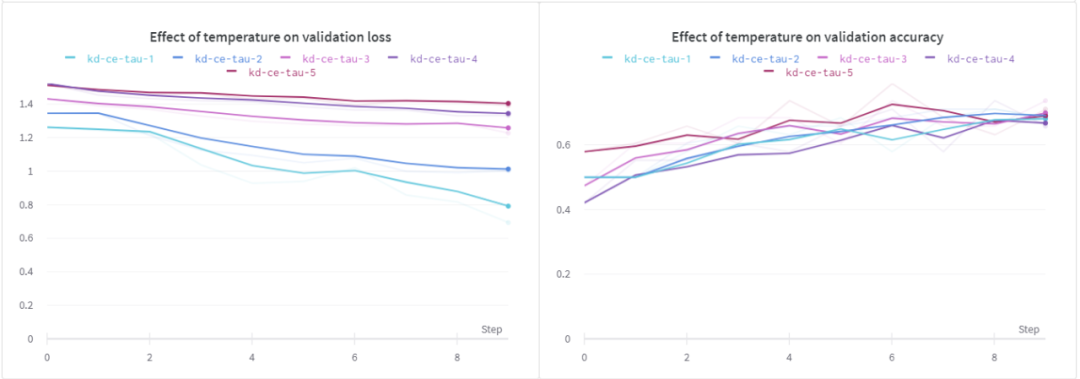
最后,我想研究下微调基线模是否对学生模型有显著影响。
基线模型调优的效果
在这次实验中,我选择了 EfficientNet B0作为基础模型。让我们先来看看我用它得到的微调结果。注意,如前所述,所有其他超参数都保持其默认值。
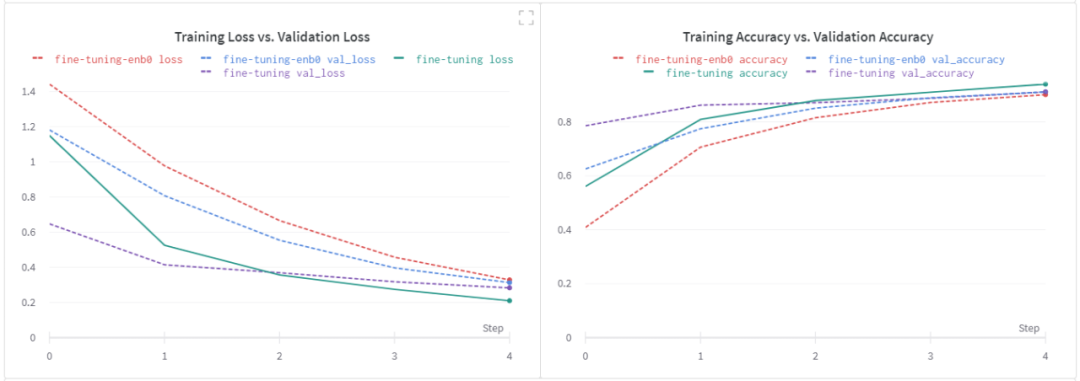
我们在微调步骤中没有看到任何显著的改进。我想再次强调,我没有进行严格的超参数调优实验。基于我从EfficientNet B0得到的边际改进,我决定在以后的某个时间点进行进一步的实验。
第一行对应的是用加权平均损失训练的默认student model,其他行分别对应EfficientNet B0和MobileNetV2。注意,我没有包括在训练student模型时通过使用数据增强而得到的结果。
知识蒸馏的一个好处是,它与其他模型优化技术(如量化和修剪)无缝集成。所以,作为一个有趣的实验,我鼓励你们自己尝试一下。
总结
知识蒸馏是一种非常有前途的技术,特别适合于用于部署的目的。它的一个优点是,它可以与量化和剪枝非常无缝地结合在一起,从而在不影响精度的前提下进一步减小生产模型的尺寸。
责任编辑:lq
-
神经网络
+关注
关注
42文章
4771浏览量
100708 -
数据集
+关注
关注
4文章
1208浏览量
24688 -
Softmax
+关注
关注
0文章
9浏览量
2506
原文标题:神经网络中的蒸馏技术,从Softmax开始说起
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2024全国高校电子信息类专业课程实验教学案例设计竞赛圆满结束
武汉传媒学院联合创龙教仪建设DSP教学实验箱,基于DSP C6000平台搭建
荆州学院联合创龙教仪建设DSP教学实验箱案例分享
讯维AI教学分析系统的应用提升整体教学质量
SolidWorks教育版:丰富的教学资源
逆变器电池用蒸馏水理由,金属触点完全浸没

搭配100教学实验案例,轻松解决老师备课难题!

MR混合现实情景实训教学系统开发
普源精电支持的RIGOL杯全国高校电子信息类专业课程实验教学案例设计竞赛上榜!
学校教学选择SOLIDWORKS教育版的原因
MR混合现实情景实训教学系统在军事专业课堂上的应用
帕克西AR实训教学解决方案:AR技术在工业领域的广阔应用前景
OneFlow Softmax算子源码解读之BlockSoftmax
OneFlow Softmax算子源码解读之WarpSoftmax





 工商网监
工商网监
评论