 腾讯优图实验室在人体2D姿态估计中获得了创新技术突破
腾讯优图实验室在人体2D姿态估计中获得了创新技术突破
近日,腾讯优图实验室在人体2D姿态估计任务中获得创新性技术突破,其提出的基于语义对抗的数据增强算法Adversarial Semantic Data Augmentation (ASDA),刷新了人体姿态估计国际权威榜单。相关论文(Adversarial Semantic Data Augmentation for Human Pose Estimation)已被计算机视觉顶级会议EUROPEAN CONFERENCE ON COMPUTER VISION (ECCV2020)收录。
作为计算机视觉领域的基础技术之一,人体姿态可以理解为对“人体”的姿态(关键点,比如头、左手、右脚等)的位置估计,其中2D人体姿态估计在多种视觉应用中发挥着重要作用。不过尽管该技术研究的时间历程较长,相关创新方法也层出不穷,但在很多场景下,其效果依然不尽人意。
如图1所示,对于对称性较强的人体、遮挡比较严重的场合以及多人场景,2D姿态估计的表现普遍比较差。解决上述问题的一种有效的方法是对数据集进行数据增强,然而现有的数据增强算法比如图片的翻转、旋转或者图片色度的改变,都是全局尺度上的数据增强,无法解决图中所示的挑战性案例。

图1. 二维人体姿态估计的挑战性案例
为解决上述提及的难点,优图提出了基于语义对抗的数据增强算法Adversarial Semantic Data Augmentation (ASDA)。该算法的整体pipeline如图2所示,输入图片经过生成网络,进行语义粒度上的数据增强;增强后的图片作为姿态估计网络的输入,进行姿态估计,得到二维人体姿态。生成网络生成增强样本,提升姿态估计网络的预测难度,姿态估计网络则试图预测增强后图片。
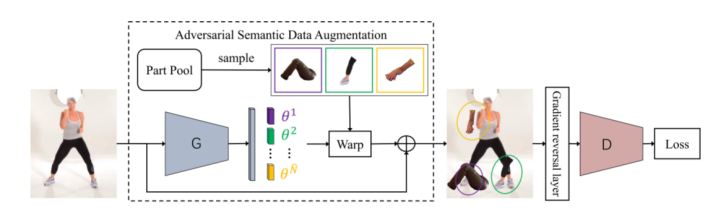
图2. ASDA算法流程图
与其他算法相比,腾讯优图的算法有三点创新。创新之一,提出了一种基于局部变换的数据增强方式,有效填补了全局数据增强的缺陷。创新之二设计了一种基于人体语义部件的数据增强算法(SDA, Semantic Data Augmentation),通过语义粒度上的图像替换以及变换来有效vwin 之前网络无法处理的挑战案例。
第三点创新便是提出了ASDA算法,该算法在MPII、COCO、LSP等主流二维人体姿态估计Benchmark上均超过了state-of-the-art方法,达到第一名水平,将人体2D姿态估计的准确度推进到全新高度。ASDA作为一种通用的数据增强方法,可以便捷地用在二维人体姿态估计的不同数据集以及不同网络结构上。
实践结果表明,优图的算法在COCO、MPII、LSP三个姿态估计的benchmark达到了最高的水平,图4-7展示了在以上三个权威数据集上优图的方法与其他SOTA算法在准确度上的差距。为了方便展示ASDA算法的效果,在COCO测试集进行可视化得到图3,可以看到优图的算法能够有效的解决图1中的挑战性案例。
作为腾讯旗下顶级的人工智能实验室之一,优图聚焦计算机视觉,专注人脸识别、图像识别、OCR、机器学习、数据挖掘等领域开展技术研发和行业落地,在推动产业数字化升级过程中,始终坚持基础研究、产业落地两条腿走路的发展战略,与腾讯云与智慧产业深度融合,挖掘客户痛点,切实为行业降本增效。
在未来,腾讯优图也将继续深耕于人体2D姿态估计技术,并将持续探索更多的应用场景和应用空间,让更多的用户享受到科技带来的红利。
fqj
-
腾讯
+关注
关注
7文章
1652浏览量
49422 -
智能算法
+关注
关注
0文章
77浏览量
11930
发布评论请先 登录
相关推荐
DEKRA德凯温州低压实验室获得沙特电力公司SEC认可
LIMS系统在芯片实验室中的应用
TÜV莱茵授予联想合作实验室资质
优刻得与联想AI实验室携手共建高效AI资源池
广和通获得UL Solutions WTDP目击实验室资质

广和通获得UL Solutions WTDP目击实验室资质
华南检测中心:实验室能力验证平台

DEKRA德凯广州新能源实验室获得CBTL新认可资质
盛景微获得CNAS实验室认可证书
TCL华星与联想共建创新显示联合实验室
三星在硅谷建立3D DRAM研发实验室
北汇信息获得一汽研发总院颁发的外部实验室认可证书

【爱芯派 Pro 开发板试用体验】人体姿态估计模型部署前期准备
半导体制冷技术在实验室仪器中的应用简介






 工商网监
工商网监
评论