 一文解析鸿蒙LiteOS和LINUX比较
一文解析鸿蒙LiteOS和LINUX比较
鸿蒙是一个面向场景的智能操作系统。很多人刚开始把它与Linux相比,这是不对的,首先Linux只是一个内核,在Linux之上我们开发者还需要做很多的操作,比如驱动开发和应用开发才能让用户能够正常的操作。鸿蒙的LiteOS才是用来对标Linux的,值得注意的是LiteOS和Linux是一样的,都是宏内核而不是之前宣传的微内核,鸿蒙的微内核可能要到过段时间才会发布。那么鸿蒙对标的产品是什么呢?是安卓和Windows。这也让安卓特别的难受,因为与它正在开发的Funchsia系统在地位上有较大的吻合,都是面向IOT设备的操作系统。我们可以看看这张图,在鸿蒙的整个框架中内核只是占比较小的一部分,而内核这部分里还分了两个内核子系统:Linux和LiteOS。所以内核位于鸿蒙就像心脏位于人体,非常重要但占比很小。如果把内核类比成系统就好像把心脏类比成人一样,不合适。
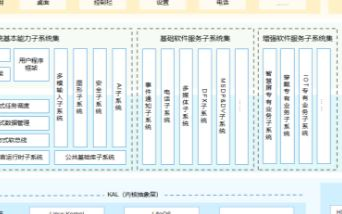
系统基本能力子系统集:为分布式应用在 HarmonyOS 多设备上的运行、调度、迁移等操作提供了基础能力,由分布式软总线、分布式数据管理、分布式任务调度、方舟多语言运行时、公共基础库、多模输入、图形、安全、AI 等子系统组成。其中,方舟运行时提供了 C / C++ / JS 多语言运行时和基础的系统类库,也为使用方舟编译器静态化的 Java 程序(即应用程序或框架层中使用 Java 语言开发的部分)提供运行时。
基础软件服务子系统集:为 HarmonyOS 提供公共的、通用的软件服务,由事件通知、电话、多媒体、DFX、MSDP & DV 等子系统组成。
增强软件服务子系统集:为 HarmonyOS 提供针对不同设备的、差异化的能力增强型软件服务,由智慧屏专有业务、穿戴专有业务、IoT 专有业务等子系统组成。
硬件服务子系统集:为 HarmonyOS 提供硬件服务,由位置服务、生物特征识别、穿戴专有硬件服务、IoT 专有硬件服务等子系统组成。
刚刚讲了一个宏内核和微内核的概念,那什么是宏内核什么是微内核呢?

这一张图就是用来区分宏内核和微内核的,中间有一条横线,横线上面是运行在应用的,叫应用(用户)态,应用态是受操作系统限制的,只能在指定的内存空间中运行。横线下面是运行在内核里面的,也叫内核态。最左边的是宏内核,中间是微内核,最右边的是混合内核。那么宏内核和微内核有什么区别,其实就是划分的问题,简单的说,宏内核把大大小小的事情都划分到内核里面去处理,比如VFS虚拟文件系统,系统调用,文件系统等等统统塞进内核,只有应用程序才运行在用户态。而微内核则是相反,除了核心的内核,统统扔到用户态里面去执行,这两个是完全的极端,这也带来明显不一样的效果。首先比较明显的不同就是微内核比较容易扩展,且内核驱动之间互不干扰,不会出现像宏内核那样,一个崩都得死的现象。微内核里面比较有名的就是我们的国货之光RT-Thread。那么比如说Mac OS X使用的就是比较中庸的混合内核,让驱动程序员来决定这些东西到底放在用户态还是内核态。这样在保护内核同时给开发带来比较大的灵活性。有些功能它需要用极致的处理速度,并且程序上稳定不会太大改变,那么就可以把这块的驱动程序沉到内核态,有些东西它不需要很快的执行速度,且因为业务问题需要经常的变动,那么可以扔到用户态。

那既然Linux是宏内核,LiteOS搞了半天还是宏内核,为啥鸿蒙还要搞一个LiteOS呢?
Linux的强大在于它支持的硬件非常多,但是它过于庞大,启动慢、耗电,这些缺点导致它不适合用在资源比较受限的物联网硬件设备领域。
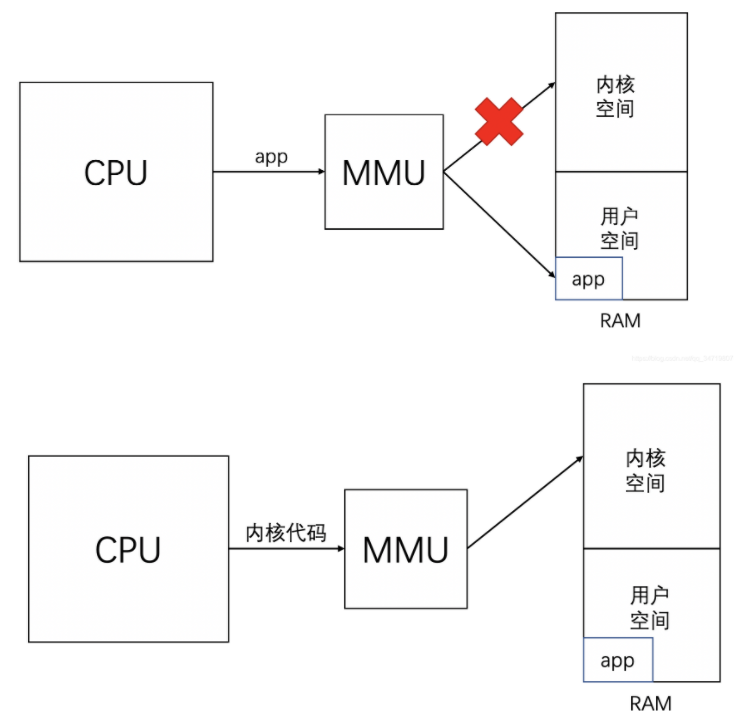
Liteos-a为物联网而生,与其他RTOS(实时操作系统)不同,LiteOS支持MMU,支持内核/APP空间隔离、支持各个APP空间隔离,系统更健壮;启动快,省电。等下我们可以稍微体验一下他开机能有多快,快到我都觉得他是关机其实只是待机。
除了Liteos-a,还有一个Liteos-m,后者运行在没有MMU的芯片上,也就是运行在MCU上,就是传统的单片机。
讲回鸿蒙系统,鸿蒙有啥不一样的呢?官方的回答是:作为面向未来的全场景分布式OS:它具有多端统一OS、硬件虚拟化互助(也就是分布式)以及一次开发多端部署的优点。
什么叫多端统一OS ?鸿蒙在开发者大会上提出1+8+N的一个硬件生态理念,就是围绕着以手机为中心,开展8个领域的华为自研产品,包括 PC、平板、车机、运动健康、穿戴、AR/VR、智慧大屏、智能音响。同时打造大量的IoT设备,也就是里面的N,比如:耳机,打印机,电子秤等等。而这些设备都将使用鸿蒙OS来开发。全部使用鸿蒙OS就能为第二步:硬件虚拟化互助带来可能性。
什么叫硬件虚拟化互助,即分布式任务调度?我们先想象这么一个场景:假设我们开车使用车上的车载导航到达目的地附近,接着要使用手机导航到目的地需要几个步骤:首先打开手机里的导航软件-》输入目的地-》选择步行导航-》开始导航。现在我们觉得这些操作合情合理,但是如果手机和车载都搭载了鸿蒙系统,这个步骤将会缩短成一步:拿出手机就可以继续导航,真正实现无缝衔接,而这一过程里车载上的导航将会移到手机上,并显示。这就是为应用提供多设备协同的能力。
那这个分布式架构有什么优势?以及它是如何实现硬件虚拟化互助的这个功能呢?
分布式架构在设计之初就考虑了多设备移植和部署的这个需求,这也就刚刚说的第三点好处(一次开发多端部署),它是分布式架构设计带来的一个结果之一,只要一次开发就可以在上面所说的1+8+N上跑自己的应用程序。那么在鸿蒙底层也为这种协同工作带来一些组件上的支持。像我们现在的分立式设备,两个不同的设备是如何建立连接的?需要用到蓝牙或者wifi,以及一些相关的协议。那么这是建立在双方有蓝牙或者wifi的前提下,以及协议必须相同的前提下,如果其中一方不支持,那么它们就不可能建立起连接,所以在开发过程中,你既要跟APP厂家近进行协同,又要跟另外一个硬件厂家进行协同,这样的成本其实是非常的高昂的。所以鸿蒙的出现首先要降低这种协同上的成本。我觉得也是大家以后会使用鸿蒙比较重要的原因之一。
那么鸿蒙是如何做到分布式智能互联的呢?这里有一张图,这张图vwin 了两个设备之间的互联情况,我们假设设备1是一个手机,设备2是一个手表。那么这两个设备是如何连接的呢?鸿蒙提供两种解决方案,一种就是传统的物理层连接,也就是通过蓝牙-蓝牙、wifi-wifi等方式进行连接。一种就是软总线连接,
什么叫软总线?传统的连接方式要求双方必须要有相同的传输设备,比如都有蓝牙设备。但是软总线可以做到使用设备1由蓝牙设备发送数据,设备2使用wifi接收,在开发过程中不再需要关心网络协议差异。鸿蒙
所以我们可以使用软总线在两个设备之间快速的通信。在软总线之上是鸿蒙提供的一个分布式执行框架,这一套框架可以允许我们通过软总线与多个设备进行连接。同时分布式执行框架也是用来区分数据要发给哪个设备,假如说,我一台手机连接好几个智能手表,那么怎么知道我手机上的一张照片是发给哪个智能手表的?就可以在分布式执行框架进行判断。在往上走是用户程序框架,这个框架是鸿蒙给APP开发着提供的统一的调用接口,这样APP开发者就不需要去考虑这个分布式互联是如何实现的。在开发中,你要运行到设备1和设备2的应用是一起开发的,也就是说你一次就可以开发完两个设备上的应用。

设备1里还有一个FA和设备2里面还有一个AA,它们分别是什么呢?AA(Atomic Ability)是不带界面的功能单元,AA是鸿蒙中不可缺少的且不能分割的能力,所以也叫元能力。而FA(Feature Ability)就是带界面的AA。AA和FA都是由鸿蒙框架去实现的,然后通过统一的接口供开发者使用。那么这些AA和FA是什么呢?这些都是一些简单的小功能,当我们要去实现一个功能的时候,需要去调用不同的AA或者FA。比如说我要实现一个拍照功能,或者音乐播放的功能就需要调用这两个AA或者FA。同时不同的设备之前也可以相互调用AA或者FA,也就是跨设备调用。我们可以想象一下,现在的我们开发应用要调用某个设备,比如说摄像头,那必须是这个设备拥有摄像头这个功能,所以在开发过程中程序员必须充分了解这点。但是在鸿蒙里它是面向场景的操作系统,开发者无需考虑自己运行的这个设备是否有摄像头,只需要考虑当前环境下会出现哪些带有摄像头的设备然后调用它的AA。
那么实现这些功能的原理还是刚刚说的软总线和分布式调度。
那么至此北向的应用开发就是这些内容的介绍。现在就讲一下
鸿蒙LiteOS和LINUX比较
基础知识
LiteOS与Linux的启动区别
LiteOS以上电后会跳转到reset_vector复位向量表这里,在reset_vector中会执行关中断、设置ICache、重定位、
然后会看到PAGE_TABLE_SET,这是一个宏,用来设置页表的 ,设置完页表之后就会启动MMU,一旦启动MMU,CPU就没办法通过物理地址访问设备。只能用虚拟地址
启动MMU之后初始化栈、然后调用main函数
那Linux在启动内核的时候做了哪些操作呢?如下图,可以看出还是非常的相似的

MMU
先举个例子,编写两个测试demo:main_world.c和main_leleen.c
1、main_world.c
#include 《stdio.h》
int main(void)
{
printf(“Hello World!!!!!\r\n”);
}
2、main_leleen.c
#include 《stdio.h》
int main(void)
{
printf(“Hello Leleen!!!!!\r\n”);
}
将其进行编译得到可执行文件:
arm-linux-gnueabihf-gcc -g -o main_world main_world.c
arm-linux-gnueabihf-gcc -g -o main_leleen main_leleen.c
再将其进行反编译
arm-linux-gnueabihf-objdump -S -d main_world 》 main_world.txt
arm-linux-gnueabihf-objdump -S -d main_leleen 》 main_leleen.txt
会发现他们的起始地址都是一样的:0x0102c8

很显然,这个地址不应该是物理地址,理由有一点是可以确认的:当前我们的应用程序并没有在开发板子上跑起来。所以这个地址应该是一个虚拟的地址。
上面是通过代码来查看地址,那如果在硬件上,假设当前RAM运行了多个APP,它们的运行状态保存在RAM中,此时它们的地址应该各不相同,比如app1的地址是addr4,app2所处的地址是addr1。这些地址是app所处的物理地址。所以在编译某个app时,需要单独指定它的链接地址,也就是指定它去哪里运行。如下面这张图,但这是一个不可能完成的任务。因为app众多且运行时保存在哪个地址是完全不可以预料的。所以这里必须引入虚拟地址。CPU只需要通过虚拟地址就能控制某个应用程序。

除此之外,引入虚拟地址还有一个作用,在资源少的硬件上运行容量大的应用,比如说一个10G的应用在只有512M的RAM上运行。应用程序不可能一次性跑完,它会分段加载,假如说先运行片段1,那么就会先把片段1的程序先加载到RAM上运行,依次这样操作,当运行到片段5的时候,此时RAM已经满了, 这个时候,系统会将RAM中先运行的片段1擦除,然后将片段5拷贝到运来片段1的RAM空间上运行。

CPU是如何处理和管理这些虚拟地址,这就是MMU的工作,MMU是硬件,不是软件。对内存的管理属于硬件管理,从应用程序的角度看,MMU是完全透明且不被感知的,所以在日常开发中都不会引起注意。
当CPU发出0x0102c8这个虚拟地址的时候,会通过MMU进行分析。MMU通过分析CPU发来的虚拟地址去调用不同的APP。既然MMU会去分析虚拟地址并转换成物理地址,那么在MMU内部一定存在一个虚拟地址和物理地址的对应关系,这个对应关系就是页表。

鸿蒙使用的二级页表,页表的分析有点麻烦,时间问题我也没有很仔细的去理解,为了方便后面的理解,我自己暂且把它理解一本新华字典,当CPU发过来虚拟地址的时候,MMU就去翻这本新华字典,先从偏旁部首的目录开始找,找到了就跳到那一页查看是哪个地址,以及这个地址有哪些权限。
那如何使用MMU?大致需要以下步骤:在内存中创建页表-》把页表基地址告诉MMU-》启动MMU
所以等下在LiteOS移植前需要先去设置它的MMU的页表,让它指向开发板内存的首地址,并且设置大小。这样就能建立虚拟地址和物理地址的映射,LiteOS就能正确的去访问物理地址。
最后MMU除了管理虚拟地址和物理地址之外,还有一种功能就是保护内存,防止数据被篡改。比如说我们写的一个APP,当CPU发出APP的虚拟地址给MMU时,MMU会判断这个APP是否有权限访问内核空间,当发现只是一个普通的APP的时候,只可以让它访问自己的空间,而不能访问其他内核空间和其他APP的空间。
在reset_vector_up.S中设置MMU的地方:SYS_MEM_BASE是物理地址,KERNEL_VMM_BASE是虚拟地址,SYS_MEM_BASE点进去SYS_MEM_BASE指向-》DDR_MEM_ADDR,我们需要更改DDR_MEM_ADDR,让它指向6ull的内存基地址(物理地址)0x80000000
那0x80000000这个值是从哪里来的呢?需要去6ull的芯片手册查找,同时我们要找到等会要实现的串口物理地址

找到了这两个值就可以设置页表了
将PERIPH_PMM_BASE设置为0x02020000,SYS_MEM_BASE设置为0x80000000
但这么设置会有问题,因为LiteOS的映射是段映射,也就是说必须是整M的映射,所以我们将PERIPH_PMM_BASE设置为0x02000000

那么PERIPH_PMM_BASE的物理地址会映射到PERIPH_DEVICE_BASE,打开PERIPH_DEVICE_BASE,以后就可以通过
UART_Type* uart0 = IO_DEVICE_ADDR(0x02020000);来获取设备的虚拟地址
设置完这些我们就可以来实现串口输出了
串口输出的实现
PRINT_RELEASE -》 LOS_LkPrint(los_printf.c)-》OsVprintf(los_printf.c)-》UartPuts(amba_pl011.c)-》UartPutsReg(amba_pl011.c)-》UartPutStr(amba_pl011.c)
amba_pl011.c这是华为用于他们开发板的代码,要使用它得去修改这个代码
修改UartPutsReg
STATIC VOID UartPutcReg(UINTPTR base, CHAR c) { UART_Type *uartRegs = (UART_Type *)base; while (!((uartRegs-》USR2) & (1《《3))); /*等待上个字节发送完毕*/ uartRegs-》UTXD = (unsigned char)c; }
设置完这些我们要进行编译一下,首先先进入liteos_a所在的文件夹下,拷贝一下3518的配置文件到我们的目录下配置一下
cp tools/build/config/debug/hi3518ev300_clang.config .config
make clean
make -j 8
中断子系统
当我们点击触摸屏等外设的时候,会产生一个中断,这个中断是如何到达CPU的呢?在ARM芯片上由一个通用的中断控制器,叫GIC。这个中断控制器主要是来决定发过来的中断哪个优先级更高,发送给CPU,如下图
这张图是GIC的详细流程,里面有很多细节,简单来看就是下面这张

那么CPU如何去访问GIC?CPU发送虚拟地址到MMU从而访问到外设,比如DDR、UART,同样的,CPU要访问GIC也必须通过MMU去访问,通过芯片手册可以知道GIC的物理地址是0xa00000,这个地址比我们刚刚设置的URAT的物理地址还要低,所以我们等会要去设置PERIPH_PMM_BASE,将它设置成0x00a00000。那么映射多大空间呢?因为我们现在只使用到了URAT和中断,那么PERIPH_PMM_SIZE可以设置为0x00a00000 - 0x02000000 = 0x1600000
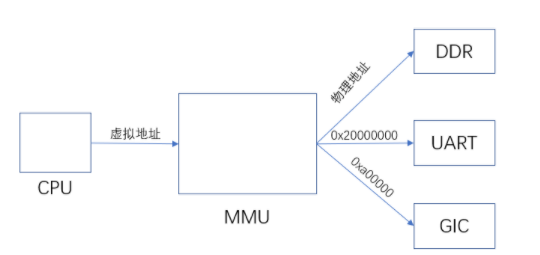
那么有哪些使用虚拟地址去调用GIC呢?
LITE_OS_SEC_TEXT_INIT INT32 main(VOID);
LITE_OS_SEC_TEXT_INIT VOID OsSystemInfo(VOID);
CHAR *HalIrqVersion(VOID);
UINT32 pidr = GIC_REG_32(GICD_PIDR2V2);
#define GIC_REG_32(reg) (*(volatile UINT32 *)((UINTPTR)(GIC_BASE_ADDR + (reg))))
我们要去设置这个GIC_BASE_ADDR
将#define GIC_BASE_ADDR IO_DEVICE_ADDR(0x10300000)
改为#define GIC_BASE_ADDR IO_DEVICE_ADDR(0xa00000)
那中断产生的时候是从哪里进来的呢?总要有一个入口吧?其实不管什么处理器,都有中断(异常)向量表,在中断总入口中,所有的中断都会调用到这里,也就是说,作为一个管家,它需要分辨出调用它的是哪个中断,然后调用对应的中断函数。而这对应的中断函数由我们提供。如何提供这样的函数呢?可能是LiteOS在这一块还不够完善或者为了减少我们开发者的使用成本,内部机制中还兼容着老款Linux的体系,使用request_irq,也可以使用鸿蒙LiteOS自己使用的OsalRegisterIrq,接下来我们分别讲讲从Linux和鸿蒙是如何处理中断的。

先来讲讲Linux是如何处理中断的。
在讲中断之前,我们先引入一个生活场景,假如我们现在回家口很渴,想烧水来喝,于是就去厨房烧了水,那么我们有以下几种等待方式,1、盯着这壶水硬等,我就站在热水壶旁边看着它烧开;2、同样在旁边,但是我刷起了抖音,等它烧开发出响声的时候我在过去冲。3、我先去洗个澡,20分钟后这壶水肯定烧开了;4、回到客厅开始刷剧,等到水烧开的时候它就会发出响声,同时热水壶还是智能的,可以通过手机APP通知我烧开了。
这4个操作分别对应着我们程序中的“查询机制”、“休眠-唤醒机制”、“poll方式”、“异步通知”,除了第一种,剩下的都是我们常说的中断机制。
了解了中断机制,我们来看看CPU通常会发生哪些意想不到的异常而产生的中断: ① 指令未定义 ② 指令、数据访问有问题 ③ SWI(软中断) ④ 快中断 ⑤ 中断。那么这些是如何而来的?不管是uboot、Linux还是鸿蒙,都会有像上面那样的异常向量表,每一个跳转都对应着一个异常中断。
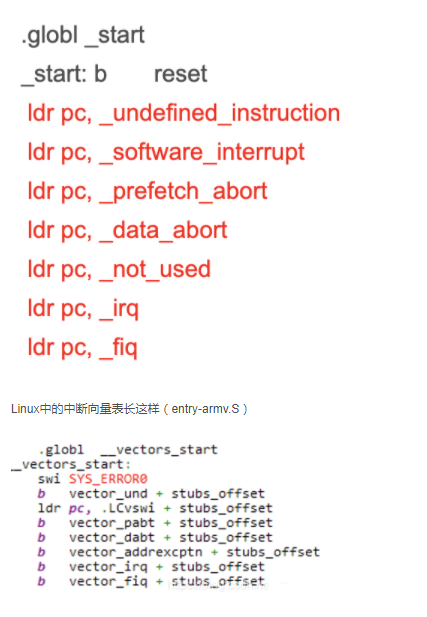
Linux中的中断向量表长这样(entry-armv.S)
我们引入一个场景,当前有一个进程A,在他运行中产生了一个中断

那么进程间的切换时候,中断还会做什么事情呢?1、保存当前A进程的现场,2、执行中断,3、恢复A现场。这切换过程中保存的数据全部放在栈中。那么当A产生中断的时候,这个时候能不能再产生一个中断呢?并不可以。我们假设可以,当A在执行中断程序的时候,发生了另外一个中断2,此时要保存中断程序中的现场,然后跳去2执行中断函数,当2执行中断函数的时候又产生了3中断,……周而复始,保存在栈中的数据会越来越多,最后把整个栈都撑爆了。
除此之外,中断处理函数还必须快速开始快速结束,如果中断函数里面有大量的耗时运算,此时进程A会处于一种假死状态,这种现象是非常难以忍受的。但很显然,在显示开发中很难避免会在中断函数中处理一些耗时的操作,那么应该怎么办?先把这个问题放一边。
我们来看看硬件上是如何产生一个中断的。假设一个GPIO0中接有两个外部物理设备,设备1和设备2,当设备1从高电平变成低电平的时候产生一个中断信号,同理,如果设备2也这样操作,也会产生一个中断信号,中断信号通过GIC通用中断控制器传给CPU来执行不同的中断处理函数。那么CPU如何去知道哪个设备触发了这个中断呢?CPU可以去GIC中读取寄存器的值来确定是哪个模块发生了中断。假设知道了是A号发生了中断,A号中断对应的是GPIO的中断,但GPIO中又有很多GPIO中断,假设除了刚刚说的那个,还有GPIO0、1、2都可以产生中断。那么还要继续读取GPIO中的寄存器进行判断是谁出发了中断,假设读到了刚刚说的那个B号中断。那么对于这个B号中断呢,它有可能是设备1发出的中断,有可能是设备2发出的中断。那么就需要去调用设备1的中断处理函数和设备2的中断处理函数来判断下。

上面可以看到有两个中断,一个是A号中断和B号中断。它们在Linux中是通过一个irq_desc数组进行保存的,在irq_desc数组中有两个比较关键的点,一个是 handle_irq,一个是 irqaction。
A号中断的handle_irq主要会做哪些事情呢?首先会读取GPIO的寄存器确认是GPIO发出来的中断。当确认了GPIO是由GPIO发出的中断的时候回去调用GPIO的中断处理函数handle_irq,那么GPIO是如何知道是设备1还是设备2发出的中断呢?很简单粗暴,直接调用两个设备的处理函数,由它们的处理函数handler来判断自己有没有发出中断信号。
那么还有一个irqaction结构体,这个action结构体是用来做什么的呢? 当调用 request_irq、 request_threaded_irq 注册中断处理函数时,内核就会构造一个 irqaction 结构体。在里面保存 handler函数,如果是共享中断,里面会放有多个设备的处理函数讲他们链起来。当指定到GPIO处理函数的时候,系统会去irqaction下讲设备1和设备2的处理函数都执行一遍。
我们接着往下看会看到handler下还有一个thread_fun。还记得我们刚才留下的一个问题吗?如果我必须在中断处理函数中执行很耗时间的操作该怎么办?我们可以在handler中执行一些最核心的代码,在这一部分执行的代码是不可以被再次中断的,然后讲不那么重要但需要时间去运算的操作放在thread_fun去操作。当handler执行完成之后就会去调用thread,当thread判断有机会执行时候就会去调用thread_fun里面的函数。
上面就是使用request_irq注册一个中断处理函数的一个大致概念,下面鸿蒙的部分我们分析它的调用流程即可,因为会发现鸿蒙LiteOS把这一块处理的十分的简单
假设系统发生中断,那么会跳来执行b OsIrqHandler。 在OsIrqHandler中会保存环境然后禁止中断等等,然后调用HalIrqHandler,在HalIrqHandler中
UINT32 iar = GIC_REG_32(GICC_IAR);//读取GIC里面的寄存器,就可以知道你发生的是哪一号中断。
然后调用OsInterrupt(vector);来处理这一号中断。如何处理呢?
在OsInterrupt里面使用vector取出它的hook函数,这个hook函数是什么呢?在我们注册的调用OsHwiCreateShared的时候会将hook指向我们的我们的处理函数

总结一下

讲了中断这个概念,是为了解决一个疑问,就是鸿蒙LiteOS是如何实现多任务实时操作系统的,所谓的多任务实时操作系统就是在同一个时间内同时存在多个任务在运行。这里的同时是相对我们人感知的时间,实际上在操作系统中是通过不断的任务切换来分配CPU资源的,只是这种切换的速度足够的快,以至于人感受不到。那谁来触发这个中断呢?时钟中断,时钟中断每隔一段时间就会触发一次来判断当前任务执行的时间片是否用完,如果用完就切换到下一个任务。当一个任务的时间全部用完时候就从执行队列里面彻底的删除。

那么鸿蒙是怎么做到这一点的呢?
打开arm_generic_timer.c
在HalClockInit中使用HalClockFreqRead(VOID)读取时钟的频率。
HalClockFreqRead(VOID)中通过一条协处理的汇编指令来读取当前的时钟频率
mrc:协处理器,MCR指令用于将ARM处理器寄存器中的数据传送到协处理器寄存器中
获取到时钟的频率之后LOS_HwiCreate(OS_TICK_INT_NUM, MIN_INTERRUPT_PRIORITY, 0, OsTickEntry, 0);来注册中断处理函数。OsTickEntry是系统时钟的滴答中断,每隔十毫秒产生一次,多任务的调度就依赖于这个系统中断。
在OsTickEntry中会调用到OsTickHandler();里面会使用OsTaskScan对多个任务进行系统扫描,如果当前任务执行的时间已经用完就使用LOS_ListDelete移除出去0
字符设备
在这里我们用内存来模拟存储设备,存储设备就是块设备,在Linux中字符设备和块设备,LiteOS也是采用这种模式。
那什么叫字符设备。简单的说一个字节一个字节进行读写操作的设备,不能随机读取设备中的某一数据、读取数据要按照先后数据。字符设备是面向流的设备,常见的字符设备有鼠标、键盘、串口、控制台和LED等
当我们应用想去访问某个硬件的时候:使用open、read、write、ioctrl等,比如我要操作一盏灯,如下代码:
int main(){ int fd1,fd2; int val = 1; fd1 = open(“dev/led”,O_RDWR); write(fd1,&val,4); }
这里的open、write是谁实现的,在应用层下还有一层:C库,由它来实现,它和应用一起都属于应用层,那么C库是怎么进入到内核的呢?当我们调用open、read的时候实际上是执行了一个swi val指令,这条指令会产生一个异常(也就是中断),当产生这个异常时就会触发内核的异常处理函数。
那么谁来处理这个异常指令呢,在内核里面有一个系统调用接口,它用来处理swi val指令,通过value来判断中断发生的原因调用对应的处理函数。比如说应用层调用open的时候传进来的val值为1,read的值为2 ,那么系统调用就会根据1和2分别调用sys_open,sys_read,这个sys_open,sys_read隶属于VFS虚拟文件系统这一层
那么当我应用使用open(“/dev/led0”,XXX)的时候,系统是如何判断“/dev/led0”是字符设备还是后面要说的块设备呢?
在Linux中我们可以通过ls -l来列出当前目录下的所有东西,cd到/dev/目录下,这里存放设备中的驱动程序。
使用ls -l就可以看到这些设备的详细信息,最左侧c、d、b代表的是对应的设备类型:c表示字符设备、d表示目录、b表示块设备。系统通过这个来判断要调用的是那种类型的设备驱动。但是有这个还不够,区分完是字符设备驱动后,我们怎么才能知道是哪个驱动程序呢?这就需要主设备号,内核通过一个散列表(哈希表)来记录设备编号,哈希表由数组和链表组成,里面存放着一堆驱动程序的结构体file_operation。系统通过主设备号通过一个计算公式获得这个数组的下标,取出结构体。然后就执行这个file_operation下的驱动程序。那谁来填充这个数组呢?当编写完驱动程序里file_operation中的所有函数的时候,会使用register_chrdev(主设备号,次设备号,“/dev/led0“,file_operation),向上注册这个结构体。

块设备
那么什么叫做块设备驱动呢?
块设备对应的就是磁盘、FLASH,你要去读写它的时候需要以一个扇区为读写单位。对于这个设备、Linux里面采用了一个叫做电梯原理的算法,如下图,假设先要读取扇区1的数据、然后到扇区3中写数据、再到扇区2读数据。如果使用字符设备驱动,就是这么个流程,此时磁头要跳转两次,效率很低,块设备将其进行优化,同个扇区先操作,其他扇区的操作先放到队列里面,等执行完后再跳转到另一个扇区进行操作,这样整体的操作就会提高。
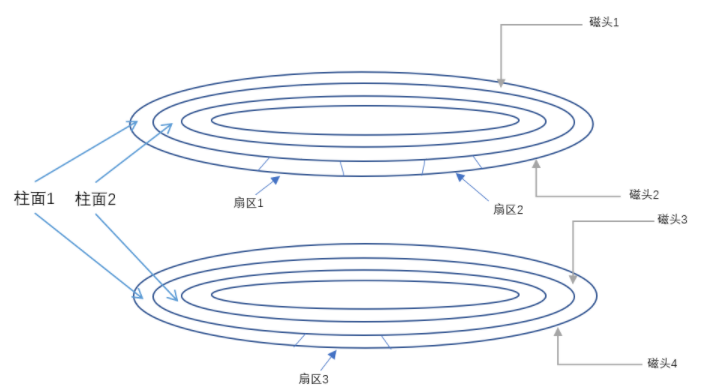
上面是硬盘,那么对于FLASH,块设备是如何进行操作的呢

假设我要去 扇区0中写数据,写完之后再去扇区1写数据,那么使用字符设备会有怎么个操作呢,因为FLASH要先擦除才能够写,但擦除是整块整块擦除的,那么为了保证其他的数据不被意外擦除,就要先把整块数据读到一个buffer里面,修改buffer里的扇区0,然后擦除整块,再把这块buffer烧写进去,写扇区1也是如此
整个流程即:读整块数据到buffer ---》 修改扇区0的数据 ---》 擦除块里面的数据 ---》 烧写数据到块里面 ---》 读整块数据到buffer ---》 修改扇区1的数据 ---》 擦除块里面的数据 ---》 烧写数据到块里面
这样非常的麻烦,那么块设备是如何去操作的呢?
首先,先把所有操作放入队列,然后进行优化:读整块数据到buffer ---》 修改扇区0和1的数据 ---》 擦除块里面的数据 ---》 烧写数据到块里面
上面的操作和生活中的坐电梯很像,这次先把要上去的通通一层一层的送到,等上电梯的这批人都上楼了,再到各层把要下楼的乘客运下去,这就是电梯算法(Noop)。所以可以先总结一下块设备的操作是:先把所有的“读写”操作放入队列里面,再其优化后再执行。
然而Linux对IO的操作不止使用了这一种算法,还有电梯算法里还包含了另外两种常见的算法CFQ 和DeadLine。
那么块设备驱动的框架是什么呢?如下图:
假设我现在要通过open、read、write一个普通的文本文件“1.txt”,操作这个文本文件其实最终是操作某个硬件,那对这个文本文件的读写怎么转换成对块设备也就是硬盘或FLASH等里面扇区的读写?这里面肯定需要一个转换,这里就需要一个文件系统:vfat、ext2、ext3、yaffs等等各种文件系统。
那么ll_rw_block主要是干什么的呢?就是我们上面说的:把“读写”放入队列 -- 》 调用队列的处理函数,优化执行

Linux源码分析:
那么Linux是如何写块设备驱动程序
1、分配gendisk:alloc_disk
2、分配/设置队列:request_queue_t
blk_init_queue
3、设置gendisk其他信息
4、注册:add_disk
HDF分析

再来回顾一下鸿蒙的整个框架,我们刚刚讲了应用层框架是如何实现跨平台调度的,也就是系统基本能力子系统集中的分布式任务调度和软总线。也讲了Linux和LiteOS内核的一些知识点和差异,那么在右下角还有一个HDF(鸿蒙驱动框架),这个HDF是什么呢?它的全称是Harmony Driver Framework。HDF的提出也是为刚刚所说的一次开发多端部署做准备的,举个例子,我开发了一套点灯的应用程序,那么我在不同板子上可能使用的是不同的内核,那么肯定就会有不同的库。HDF就是抽象出这些不同中的共性。
我们可以回忆一下单片机开发的一个场景,当你要去操作某个引脚,那么需要做到的步骤就是:查阅手册(这是必须操作)-》在程序中指定这个引脚然后初始化它-》赋值。当我们变更了芯片或者板子的时候,引脚的作用可能会发生改变,这时候,你又需要去修改程序中的引脚。这样是非常麻烦的。在Linux3.x之前的内核源码中,也是这样存在大量对板级细节信息描述的代码。这些代码充斥在/arch/arm/plat-xxx和/arch/arm/mach-xxx目录,这种编写方式被Linux之父托瓦兹怒斥为辣鸡代码。自此之后,Linux内核引入了设备树机制以描述计算机板机底层硬件信息。
编辑:hfy
-
Linux
+关注
关注
87文章
11292浏览量
209323 -
操作系统
+关注
关注
37文章
6801浏览量
123283 -
鸿蒙系统
+关注
关注
183文章
2634浏览量
66302
发布评论请先 登录
相关推荐
【精品连载】韦东山老师带你上手鸿蒙内核Liteos-a开发
鸿蒙介绍--韦东山老师带你上手鸿蒙内核Liteos-a开发
鸿蒙是一套庞大的体系,底层支持很多内核吧?liteos-m, liteos-a,linux 都支持?
【HarmonyOS】鸿蒙Liteos-a内核移植手册(PDF下载)
【HarmonyOS】鸿蒙HarmonyOS系统开源地址,鸿蒙OS、LiteOS和智慧屏三者关系
如何修改uboot引导鸿蒙内核liteos.bin
鸿蒙liteos-m移植
鸿蒙liteos-m移植2
制作一个在qemu上运行鸿蒙的liteos-m内核
鸿蒙跟Linux的关系以及什么是Liteos-a
鸿蒙系统 IO栈和Linux IO栈对比分析
如何区分鸿蒙跟 Linux ?Liteos-a 是什么?

鸿蒙liteos-a系统入门实战直播亮点






 工商网监
工商网监
评论