 AI 软件TLDR:可用一句话概括文章
AI 软件TLDR:可用一句话概括文章
摘要在一篇文章中有着至关重要的作用,它浓缩了整篇文章的精华,可以让你快速了解该篇文章的研究背景、研究意义和研究亮点,进而决定了你是否会点开这篇文章仔细阅读。
如果摘要太长或者逻辑混乱,就会失去它让人快速浏览的意义,很有可能让人忽略掉一篇正文内容还不错的文章。那么,是否可以在摘要的基础上进一步提炼,用一句话概括文章?
答案是:AI 可以做到。
近日,一款科学搜索引擎在其官网上就推出了这样一款 AI 软件——TLDR,即“太长了,没有读”(too long,didn’t read)的意思,该软件可以自动生成研究论文的一句话总结。这款软件的开发者认为,这样可以帮助研究人员更快地浏览论文,减少阅读摘要的时间。
TLDR 经常被用于网上关于科学论文的非正式讨论(比如,Twitter 或 Reddit)。
本周,这款软件在华盛顿州西雅图的非营利性艾伦人工智能研究所(AI2)创建的搜索引擎 Semantic Scholar 的搜索结果中开始上线使用。目前,该软件只为 Semantic Scholar 所覆盖的 1000 万篇计算机科学论文生成一句话摘要。
AI2 管理 Semantic Scholar 小组的 Dan Weld 表示,他们目前正在优化 TLDR,预计一个月左右的时间后,TLDR 将陆续涵盖其他学科领域的论文。
图 | TLDR 与普通总结的对比 (来源:Semantic Scholar)
初步测试表明,该工具可以帮助读者比查看标题和摘要的方式更快地整理搜索结果,特别是在手机上。
图 | TLDR 在手机上的效果(来源:Nature)
介绍该软件的预印本于 4 月 1 日首次发表在 arXiv 预印本服务器上,并在 11 月举行的自然语言处理会议上经过同行评审后被接收发表。研究人员免费提供了他们的代码,以及一个测试 demo,任何人都可以尝试使用。
图 | 生成 TLDR 的测试 (来源:SCITDLR)
如何训练 TLDR?
TLDR 本质上就是对科学论文的一种新的总结。Weld 创建 TLDR 软件的灵感一部分来自于他的同事,其在 Twitter 上分享标记文章的活泼句子。与其他语言生成软件一样,该软件是利用深度神经网络,通过进行大量的训练而生成。
图 | TLDR 的介绍 (来源:arxiv)
为了训练 TLDR,研究人员准备了 SCITLDR,这是一个多目标数据集,包含5411篇TLDR,覆盖计算机科学领域的 3229 篇科学论文。
其中,训练集包含 1992 篇论文,每篇论文都有一个“黄金”TLDR,也就是最佳 TLDR。开发集和测试集分别包含 619 篇和 618 篇论文,分别有 1452 个和 1967 个 TLDR。
通常情况下,总结数据集会假设一个给定文档只有一个黄金总结,而 SCITLDR 与大多数现有的总结数据集不同。正如早期的摘要评估工作所证明的那样,人类撰写的摘要具有可变性。
将每篇论文只考虑一个黄金 TLDR 作为自动评估的基础,可能会导致系统质量评估不准确,因为可能出现在 TLDR 中的内容可能具有很大的可变性。此外,为每份文件提供多个黄金摘要,可以进行更深入的分析和彻底的评估。
为了解决这个问题,SCITLDR 包含了从作者角度撰写的 TLDR("TLDR-Auth")和从同行评审者角度撰写的 TLDR("TLDR-PR")。
TLDR-Auth 可在各种在线平台上获得。在公开的科学评审平台 OpenReview.org 上,作者提交其论文的 TLDR,为审稿人和其他感兴趣的学者总结主要内容。学者们也会在Twitter 和 Reddit 等社交媒体平台上分享 TLDR。
TLDR-PR 是将同行评审员已经仔细检查了源论文后写的评论中的总结重写成 TLDR。为了完成这项任务,研究人员从华盛顿大学招募了 28 名计算机科学专业的本科生,他们有自我报告的阅读科学论文的经验。在接受一个小时的一对一写作训练并筛选后完成 TLDR 的写作工作。
图 | TLDR-Auth 和 TLDR-PR的对比(来源:arxiv)
图 | TLDR-Auth 和 TLDR-PR的对比(来源:arxiv)
TLDR-Auth 和 TLDR-PR 即使包含相同的信息内容,也会有很大的差异。总的来说,TLDR-PR 总结的更为抽象。
引入 CATTS 对 TLDR 进行优化
CATTS(Controlled Abstraction for TLDRs with Title Scaffolding),这是一种简单而有效的学习生成 TLDR 的方法,它可以在以上介绍的数据集训练的基础上进行补充训练。该方法解决了两个主要挑战:(1) 训练数据的大小是有限的;(2) 为了编写高质量的黄金 TLDR,需要领域知识。
为了解决这些挑战,研究人员提出使用科学论文的标题作为额外的生成目标。由于标题通常包含有关论文的关键信息,假设训练模型生成标题将允许它学习如何定位论文中的突出信息,这些信息对生成 TLDR 也很有用。
通过多任务学习纳入辅助脚手架任务之前已经研究过,用于改进跨度标注和文本分类 。与多任务学习类似,在带有控制代码注释的异质数据上进行训练已经被证明可以改善自回归语言模型中的控制生成。
为了让标题生成完成辅助 TLDR 生成的任务,研究人员提出用标题生成数据集洗牌 SCITLDR,然后分别用控制代码 <|TLDR|> 和 <|TITLE|> 附加每个源。这使得模型的参数可以学习生成 TLDR 和标题。在生成时,适当的控制代码被附加到源中。此外,上采样特定任务可以被视为应用特定任务的权重,类似于多任务学习设置中的权重损失。
图 | CATTS引入可视化(来源:arxiv)
对 TLDR 未来的期待
"我预测,在不久的将来,这种工具将成为学术搜索的标准功能。事实上,考虑到科研人员实际的需求,我很惊讶等了这么长时间才看到它的实际应用。" 西雅图华盛顿大学的信息科学家杰文 - 韦斯特(Jevin West)说,他应《自然》杂志的要求测试了该工具。"虽然它并不完美,但它绝对是朝着正确方向迈出的重要一步。" 他说。
Weld 指出,TLDR 软件并不是唯一的科学总结工具:自 2018 年以来,网站 Paper Digest 也一直提供论文摘要,但它似乎是从文本中提取关键句子,而不是生成新句子。
TLDR 可以从论文的摘要、引言和结论中生成一句话。它的摘要往往是根据文章文本中的关键短语建立起来的,所以它的受众人群是已经了解论文行话的专业的科研人员。对于普通人来说,阅读起来依旧存在一些难度。但 Weld 表示,该团队正在努力为非专家受众提供更为简单易懂的升级版产品。
研究人员还计划将该技术授权给出版商,并将其服务扩展到提供个性化的研究简报,总结某个领域的关键论文。"我们只是到了人工智能可以以人们可以接受的水平生成新颖的摘要的阶段,"Weld 说。
责任编辑:xj
-
软件
+关注
关注
69文章
4921浏览量
87396 -
AI
+关注
关注
87文章
30728浏览量
268886
发布评论请先 登录
相关推荐
OpenAI又打出王炸!一句话生成60秒视频,马斯克:人类认输吧


开关电源布线 一句话:要运行最稳定、波形最漂亮、电磁兼容性最好

求助,关于TLE2141的供电问题求解
想把差分信号转为单端信号,不是音频信号,OPA365是否还可以使用呢?
知网状告AI搜索:搜到我家论文题目和摘要,你侵权了!
esp32c3 vdd_spi如何作为gpio11使用?
一句话让你理解线程和进程

AI推理,和训练有什么不同?

NPN型三极管发射结电势和基极电流有关问题
请问AD2428 TX crossbar是个什么功能?
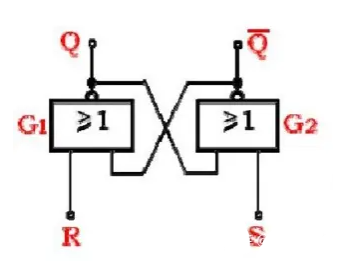
RS触发器逻辑门组成和逻辑功能表





 工商网监
工商网监
评论