 寒武纪首颗AI训练芯片:7纳米制程且算力提升四倍
寒武纪首颗AI训练芯片:7纳米制程且算力提升四倍
1月21日,寒武纪思元290智能芯片及加速卡、玄思1000智能加速器在官网低调亮相,寒武纪表示该系列产品已实现规模化出货。去年,寒武纪招股书曾简单披露了一款训练芯片的“彩蛋”,此后,寒武纪思元290芯片就一直被业界广泛关注并引发行业诸多猜想。如今,随着新一代训练产品线集中亮相,寒武纪略显“神秘”的训练芯片及相应的业务布局逐渐清晰。
思元290智能芯片是寒武纪的首颗训练芯片,采用台积电7nm先进制程工艺,集成460亿个晶体管,支持MLUv02扩展架构,全面支持AI训练、推理或混合型人工智能计算加速任务。寒武纪MLU290-M5智能加速卡搭载思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s内存带宽以及全新MLU-Link™多芯互联技术,在350W的最大散热功耗下提供AI算力高达1024 TOPS(INT4)。
寒武纪玄思1000智能加速器,在2U机箱内集成4颗思元290智能芯片,高速本地闪存、Mellanox InfiniBand网络,对外提供高速MLU-Link™接口,打破智能芯片、服务器、POD与集群的传统数据中心横向扩展架构,实现AI算力在计算中心级纵向扩展,是AI算力的高集成度平台。寒武纪训练产品线采用自适应精度训练方案,面向互联网、金融、交通、能源、电力和制造等领域的复杂AI应用场景提供充裕算力,推动人工智能赋能产业升级。
思元290采用MLUv02扩展架构
MLUv02架构为寒武纪MLU200全产品线共享,满足云、边、端三个场景的算力需求。云端训练对AI算力的要求更为苛刻,因此寒武纪对思元290的MLUv02架构进行了多项扩展,包括业内领先的MLU-Link™多芯互联技术、高带宽HBM2内存、高速片上总线NOC以及新一代PCIe 4.0接口。相比寒武纪思元270芯片,思元290芯片实现峰值算力提升4倍、内存带宽提高12倍、芯片间通讯带宽提高19倍。新架构结合7nm制程,思元290可提供更优性能功耗比,以及多MLU系统的扩展能力。
MLU290的MLUv02架构进行了多项扩展
寒武纪MLU-Link™多芯互联技术
近年来,AI算法模型的复杂程度高速增长,对算力和训练速度提出了更高的要求。为了构建更强大的计算平台,多芯片间的互联技术已成为市场刚需。
寒武纪推出MLU-Link™多芯互联技术,并首次搭载于寒武纪思元290芯片,每颗思元290的多芯互联总带宽高达600GB/s。MLU-Link™具备丰富的互联特性,突破PCIe带宽和互联的瓶颈,相比思元270芯片通过PCIe并行的通讯方式,带宽提高19倍。MLU-Link™多芯互联技术支持多颗思元芯片无缝互联,支持跨系统互联,将纵向扩展能力整合到整个人工智能计算中心(AIDC),可以端到端加速大型AI模型训练。
寒武纪vMLU解决方案
不同场景下的AI训练对计算和存储的要求千差万别,如何提供更灵活也更稳定的服务,但同时让算力得到充分地利用,是AIDC面临的持续挑战。寒武纪虚拟化技术vMLU,支持在思元290上实现4个相互隔离的AI计算实例,每个实例独占计算、内存和编解码资源。实例之间的硬件资源互不干扰,即使在虚拟化环境下仍可保持90%以上的极高效率,帮助客户充分利用硬件资源。
vMLU还可以帮助思元290芯片提供最佳的灵活性。通过热迁移技术,云管理员可将正在运行的AI负载及其应用程序移动到另外一台主机上,从而平衡整个AIDC的负载,并实现更好的容灾功能。
寒武纪首款训练智能加速卡MLU290-M5
寒武纪MLU290-M5智能加速卡搭载了思元290智能芯片,采用开放加速模块OAM设计,具备64个MLU Core,1.23TB/s 内存带宽以及全新MLU-Link™多芯互联技术,在350w的最大散热功耗下提供AI算力高达1024 TOPS(INT4)。
寒武纪首款智能加速器玄思1000
寒武纪首款智能加速器玄思1000包含4片思元290智能加速卡,最大AI算力超过4100万亿次每秒(4.1 PetaOPS INT4),一台玄思1000计算单元就足以替代一个小型传统超级计算中心。
玄思1000内置高带宽低延时的MLU-Link™多芯互联技术,实现内部4颗思元290进行高速互联,同时打破服务器、紧耦合微集群(POD)与集群的传统数据中心横向扩展架构,将AIDC构建为节点、POD乃至超大规模混合扩展架构(Hybrid Scale-out),实现AI算力计算中心级纵向扩展,满足高性能、高扩展性、灵活性、高鲁棒性的要求。
重塑AIDC基础架构
算力、算法、数据是人工智能发展的三大要素,随着这几年AI的逐步发展,算力的核心地位更为凸显。人工智能技术落地于实际应用中需要芯片和硬件层面强大的算力支撑。算力已成为驱动AI产业化和产业AI化发展的关键要素。
下一代AIDC要求更多智能芯片无缝协同、并行运行的同时,还能保持高计算效率,从而提供超级巨大的算力,以应对超大规模训练的需要。寒武纪玄思1000智能加速器重新思考了未来AIDC的基础架构,在内部和外部采用统一的MLU-Link™多芯互联技术进行通讯,使得思元290智能芯片的互联范围可以从单机扩展到POD乃至整个计算中心,重塑了基础架构。
玄思1000配置8个对外互联的MLU-Link™接口,支持跨系统互联构建MLU POD。标准配置支持MLU POD 16、24、32。在POD内部,所有290芯片均可通过MLU-Link™多芯互联技术进行通讯,在带宽和延时方面实现了突破;POD外部通过玄思1000内置的网卡与其他系统进行通讯,实现了AI训练集群性能、扩展性和鲁棒性的协同提升。
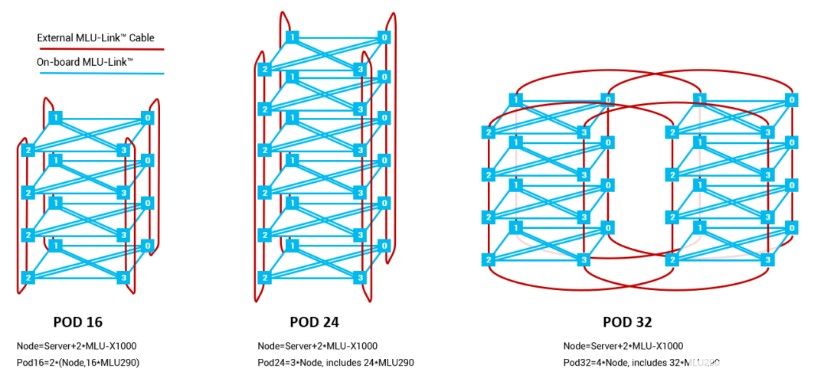
POD内所有思元芯片通过MLU-Link™全互联
除了标准配置的POD之外,在计算中心条件允许的前提下,通过MLU-Link™多芯互联技术,可实现1024颗或更多思元290互联,不需要额外的网卡即可实现无缝加速。
寒武纪Neuware™训练软件栈
寒武纪Neuware™软件栈为思元 290 芯片提供完善的软件及应用生态,支持业界主流的TensorFlow和PyTorch等深度学习框架,用户不需要改变使用习惯,即可在思元290芯片上实现图形图像、语音、NLP、搜索推荐等多种应用的训练和推理。其中,基于Horovod分布式训练框架与MLU-Link™多芯互联技术相互配合,让思元290在单机多卡、多机多卡的场景下达到业界领先的训练加速比。寒武纪Neuware™提供完善的开发工具包和社区支持,帮助用户在思元290芯片进行方便、灵活的定制开发及部署工作。配合强大的BANG智能编程语言及配套调试工具,用户可以为自定义的算法提供最佳性能调优。
2021年1月,IDC发布了《2020-2021 中国人工智能计算力发展评估报告》,该报告预计,中国人工智能市场规模在2020年达到62.7亿美元,2019-2024年的复合增长率为30.4%。IDC的调研还发现,超过九成的企业正在使用或者计划在三年内使用人工智能,其中74.5%的企业期望在未来可以采取具备公用设施意义的人工智能基础设施。
随着AI算法突飞猛进的发展,越来越多的模型训练需要巨量的算力支撑才能快速有效地实施,算力是未来人工智能应用取得突破的决定性因素。值得强调的是,在巨量的人工智能市场中,云服务市场表现更为突出。早前,2020年7月,IDC发布的另一份报告显示,2018至2024年,中国AI云服务市场年复合增长率将达到93.6%。而目前人工智能芯片仍处于成长期,未来三年,人工智能芯片市场将呈现多元化发展趋势。
寒武纪290产品线,有望在持续高速增长的人工智能市场尤其是云服务市场,抢占更多的市场份额,推动自身和AI行业的发展。据悉,寒武纪思元290芯片及加速卡已与部分硬件合作伙伴完成适配,并已实现规模化出货。
寒武纪最初布局终端IP场景,连续迭代推出让其声名鹊起的寒武纪1A、寒武纪1H、寒武纪1M系列处理器,而后迅速布局云端智能芯片及加速卡系列产品思元100和思元270,又于2019年推出基于思元220芯片的边缘智能加速卡。由此建立起覆盖云边端、训练、推理的完整产品矩阵,同时利用平台级基础系统软件Cambricon Neuware,连接全线产品,由点及面,实现了“训推一体、端云融合”。寒武纪也成为目前国际上少数几家全面系统掌握了通用型智能芯片及其基础系统软件研发和产品化核心技术的企业之一。
以寒武纪一年迭代推出一到两款新品的研发速度,我们有理由开始期待,寒武纪的下一个新品 “彩蛋” 了。
fqj
-
芯片
+关注
关注
455文章
50714浏览量
423138 -
寒武纪
+关注
关注
11文章
186浏览量
73882
发布评论请先 登录
相关推荐
台积电2纳米制程技术细节公布:性能功耗双提升
AI网络物理层底座: 大算力芯片先进封装技术
安谋科技异构算力赋能AI计算,此芯科技首款AI PC芯片发布

寒武纪2023年报出炉:营收稳健亏损收窄 毛利率达69.16%
Meta自主研发芯片增强AI服务,减轻对英伟达等外部供应商依赖
AMD推出锐龙8000嵌入式处理器,AI算力高达39 T
“AI芯片第一股”,7年亏损近50亿!
“AI芯片第一股”寒武纪发布2023年度业绩快报 亏8.36亿元!
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型开发效率提升10倍
英特尔宣布推进1.4纳米制程
台积电领跑半导体市场:2纳米制程领先行业,3纳米产能飙升
寒武纪与智象未来联手,推动视觉大模型的技术创新与应用
寒武纪与智象未来达成战略合作并完成大模型适配






 工商网监
工商网监
评论