 基于人工智能技术的OCR应用
基于人工智能技术的OCR应用
光学字符识别(Optical Character Recognition,OCR)是将图像中的文字信息转化为可供计算机处理的字符信息的技术,发挥着计算机“眼睛”的功能,是机器与现实世界进行视觉交互的重要技术基础。
早期的OCR技术可追溯到1870年,电报技术和为盲人设计的阅读设备的出现标志着OCR的诞生。近年来,随着人工智能技术在OCR中的实际应用,OCR的性能和效率都得到了很大的提升。
如今,基于人工智能的OCR已经广泛应用于金融、交通、政务、司法、医疗等多个领域,进入到人们生产生活的方方面面。
档案OCR是利用OCR技术对纸质档案数字化副本等图像文件中的字符形状进行识别、文字转换和文本输出、呈现的过程。
利用人工智能技术开展档案OCR工作,对于提高工作效率和准确性,加快自动著录、全文检索、数据分析等系统功能更好实现,推动档案信息资源建设从数字化向数据化转型具有重要意义。
档案OCR工作现状
2013年以来,在国家档案局大力实施“存量数字化、增量电子化”的战略背景下,纸质档案数字化副本大量产生。全国各级档案馆(室)存量档案数字化工作成效显著,数字化比例大幅提高,很多档案部门已完成全部馆藏档案的数字化工作。
截至2019年年底,全国各级综合档案馆馆藏档案数字化副本容量已达1407.8万GB(吉字节)。当前,档案OCR工作已全面启动,相关标准规范已适时出台。部分地区档案部门在完成纸质档案数字化工作的基础上,纷纷开展了档案OCR工作。
也有一些档案部门在开展档案数字化工作的同时,同步开展了档案OCR工作。为规范相关工作的开展,国家档案局因势利导,于2019年12月发布《纸质档案数字复制件光学字符识别(OCR)工作规范》,规定了纸质档案数字复制件OCR工作的组织、实施和管理要求,确定了开展档案OCR工作的总体原则、工作流程、质量规定等。基于此,档案部门相关工作取得了大量成果,未来档案OCR将融入更广泛、更深层次的档案工作中。
传统OCR的不足
在人工智能技术广泛应用之前,文字的自动化识别是一项十分艰巨、亟需解决的问题。传统OCR识别是以文字基本外形为基础,对文字字符之间的差别进行统计分析,再找到一组最优的、可以代表文字之间差异的统计学参数,从而实现对文字的筛选和识别。
传统OCR工作流程包括图像导入、图像预处理、版面分析、文字切割、文字识别等过程。多年来,人们对传统OCR工作流程进行过大量优化研究,但是受限于流程的复杂性和人工设计特征的表达能力等,传统的文字检测与识别方法对于较为复杂的图像,例如带有畸变以及模糊的图像,最终的文字识别结果往往不尽如人意。
传统OCR对中文字符识别的不足,主要表现在以下4个方面。
一是传统OCR处理流程的工序太多,且多串行,导致错误不断被传递放大。如,在OCR处理流程中,假如每一步都是90%的正确率,看似很高,但是经过5步的错误叠加之后,结果就已经不合格了。
二是传统OCR处理流程涉及较多人工设计,并不一定能够抓住问题的本质。例如,在文字的二值化这一预处理过程中,二值化的阈值在一些情况下很难调整好。由于这个模型的复杂度较低且无法充分拟合全部数据,在实际处理过程中不得不过滤掉很多有用的信息。
三是在一些背景稍微复杂或者存在变体文字的情况下,传统OCR基本会失效,处理模型的适应性较弱。版面分析以及行切分的方式只能处理相对简单的场景,一旦面临复杂排版等情况,就很难实现准确处理。
四是对单字的识别,传统OCR无法考虑到上下文的语义关联。为了解决这个问题,传统OCR进行了很多组合,如,对识别的结果进行动态路径搜索。在路径寻优过程中,经常需要结合文字的外观特征以及语言模型进行处理,存在较多的耦合,导致在识别系统中堆砌了较多的算法。
即便如此,传统OCR也存在很多无法处理的问题,如,手写字体等存在较多的笔画粘连,传统OCR很难进行切分。以上这些不足,造成传统OCR的识别率相对较低,识别时间相对较长。
基于人工智能技术的OCR
近年来,随着计算机视觉、自然语言理解、知识图谱等人工智能技术在OCR中的实际使用,OCR的性能和效率都得到了很大提升。通过深度学习的自适应学习驱动方式,能够更好地应对传统OCR产生的一些问题,简化参数预处理的流程,实现端到端的处理,提高OCR识别率。
目前,基于人工智能技术的OCR在简体印刷文字方面的识别率已达98%以上。人工智能OCR技术还能应用于具有多样性和复杂性的识别场景。如,不同大小、字体、颜色、亮度、对比度的文字,排列和对齐方式不相同的文字,图像的非文字区域与文字区域存在相似的纹理,低对比度、模糊断裂、残缺文字等。因此,人工智能OCR不仅能应用于文档的识别,还可应用于自然场景文字图像的识别。
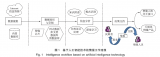
此外,人工智能OCR还能提高工作效率、节省大量成本。基于此,将人工智能OCR应用在档案工作中,具有重要的作用和意义,必将成为支撑档案行业数字转型、智能升级、融合创新的重要基础。人工智能OCR工作流程主要包括图像输入、文本检测、文本识别、人工确认、人工干预等。首先,将需要识别的纸质档案数字化副本图像单个或批量导入OCR系统中。
其次,进行文本检测。文本检测主要是定位文字在数字图像中的位置,并进行位置标注。文本检测的方法主要有基于候选框的文本检测、基于语义分割的文本检测,以及基于两种方法的混合方法等。基于候选框的文本检测是先预生成若干候选框,之后再回归坐标和分类,最后经过NMS(非极大抑制)算法得到最终的检测结果;基于语义分割的文本检测是通过FPN(特征金字塔网络)直接进行像素级别的语义分割,并处理得到相关的坐标。再次,进行文本识别。
文本识别主要是针对定位好的文字区域,识别文本的具体内容,并将图像中的一串文字转换为对应的字符。文本识别的算法可分为基于CTC(连接时序分类)技术的方法和基于注意力机制的网络模型两大类。其中,基于CTC技术的方法可以有效地捕获输入序列的下文依赖关系,同时能够很好地解决图像和文本字符对不齐的问题,但在自由度较大的手写场景下会出现识别错误。
基于注意力机制的网络模型主要应用于卷积神经网络特征权重的分配上,并提高强特征的权重、降低弱特征的权重,在由图像到文字的解码过程中有天然的语义捕获能力。然后,进行人工确认。对OCR识别后的结果进行确认,判断是否出错。
在人工确认过程中,可以采用后期批量处理等灵活性较强的方式。最后,进行人工干预,修正OCR识别结果中可能存在的错误。人工智能OCR可采用独立式或嵌入式等方式应用在档案数字化系统中。独立式是作为独立软件使用,或者通过应用程序接口(API)进行数据交互,不依赖于档案数字化系统。
嵌入式是将OCR模块嵌入档案数字化系统,作为其功能的一部分,需要在设计开发档案管理系统时进行统一规划,或对已有的系统进行改造。目前,人工智能OCR已被引入多个行业领域,但在档案行业应用中仍存在难点和不足,主要体现在两个方面。
一是档案文字存在多样性。档案类型多种多样,文字内容包罗万象,存在不同语言、字体、大小、颜色、亮度、排列和对齐方式,以及图像内容对比度低、模糊断裂、残缺等问题,甚至存在出现识别难度更大的不同时期手写体、繁简体等各种情况。这些问题或情况给档案OCR工作带来了各种挑战,人工智能OCR也无法解决所有的问题,这就需要工作人员结合实际情况,寻找基于特定技术条件的最优工作解决方案。
二是技术瓶颈。近年来,虽然人工智能OCR使机器识别文字的性能和效率得到了显著提升,但是,机器识别文字的能力和水平与工作人员理解图像中文字的能力和水平相比,依然存在较大差距。总体来看,仍需继续不断提升OCR的鲁棒性、效率性和智能化水平,才能更好地将其应用在难度更大、情况更复杂的档案工作中。
编辑:lyn
-
人工智能
+关注
关注
1791文章
47183浏览量
238203 -
计算机视觉
+关注
关注
8文章
1698浏览量
45968 -
OCR
+关注
关注
0文章
144浏览量
16348
原文标题:图像识别技术在档案OCR工作中的应用
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
对话华为大咖,探讨油气行业数字化转型和人工智能技术的应用与实践

未来智慧建筑:人工智能技术的无限可能
《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
risc-v在人工智能图像处理应用前景分析
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
FPGA在人工智能中的应用有哪些?
人工智能技术在集成电路中的应用
Google开发专为视频生成配乐的人工智能技术
嵌入式人工智能的就业方向有哪些?
aigc是什么意思和人工智能有什么区别
人工智能技术在军事情报领域的应用背景





 工商网监
工商网监
评论