 ClickHouse列式存储数据库的性能特性及底层存储原理
ClickHouse列式存储数据库的性能特性及底层存储原理
ClickHouse是一款MPP架构的列式存储数据库,但MPP和列式存储并不是什么"稀罕"的设计。拥有类似架构的其他数据库产品也有很多,但是为什么偏偏只有ClickHouse的性能如此出众呢?ClickHouse发展至今的演进过程一共经历了四个阶段,每一次阶段演进,相比之前都进一步取其精华去其糟粕。可以说ClickHouse汲取了各家技术的精髓,将每一个细节都做到了极致。接下来将介绍ClickHouse的一些核心特性,正是这些特性形成的合力使得ClickHouse如此优秀。
01完备的DBMS功能
ClickHouse拥有完备的管理功能,所以它称得上是一个DBMS ( Database Management System,数据库管理系统),而不仅是一个数据库。作为一个DBMS,它具备了一些基本功能,如下所示。
•DDL (数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
•DML (数据操作语言):可以动态查询、插入、修改或删除数据。
•权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
•数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
•分布式管理:提供集群模式,能够自动管理多个数据库节点。
这里只列举了一些最具代表性的功能,但已然足以表明为什么Click House称得上是DBMS了。
02列式存储与数据压缩
列式存储和数据压缩,对于一款高性能数据库来说是必不可少的特性。一个非常流行的观点认为,如果你想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助我们实现上述两点。列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提。
按列存储与按行存储相比,前者可以有效减少查询时所需扫描的数据量,这一点可以用一个示例简单说明。假设一张数据表A拥有50个字段A1~A50,以及100行数据。

按列存储相比按行存储的另一个优势是对数据压缩的友好性。同样可以用一个示例简单说明压缩的本质是什么。假设有两个字符串abcdefghi和bcdefghi,现在对它们进行压缩,如下所示:

压缩前:abcdefghi_bcdefghi
压缩后:abcdefghi_(9,8)
可以看到,压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。例如上述示例中的(9,8),表示如果从下划线开始向前移动9个字节,会匹配到8个字节长度的重复项,即这里的bcdefghi。
真实的压缩算法自然比这个示例更为复杂,但压缩的实质就是如此。数据中的重复项越多,则压缩率越高;压缩率越高,则数据体量越小;而数据体量越小,则数据在网络中的传输越快,对网络带宽和磁盘IO的压力也就越小。既然如此,那怎样的数据最可能具备重复的特性呢?答案是属于同一个列字段的数据,因为它们拥有相同的数据类型和现实语义,重复项的可能性自然就更高。
ClickHouse就是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存(这里主要指MergeTree表引擎)。数据默认使用LZ4算法压缩,在Yandex.Metrica的生产环境中,数据总体的压缩比可以达到8:1 (未压缩前17PB,压缩后2PB )。列式存储除了降低IO和存储的压力之外,还为向量化执行做好了铺垫。
03向量化执行引擎
坊间有句玩笑,即"能用钱解决的问题,千万别花时间"。而业界也有种调侃如出一辙,即"能升级硬件解决的问题,千万别优化程序"。有时候,你千辛万苦优化程序逻辑带来的性能提升,还不如直接升级硬件来得简单直接。这虽然只是一句玩笑不能当真,但硬件层面的优化确实是最直接、最高效的提升途径之一。向量化执行就是这种方式的典型代表,这项寄存器硬件层面的特性,为上层应用程序的性能带来了指数级的提升。
向量化执行,可以简单地看作一项消除程序中循环的优化。这里用一个形象的例子比喻。小胡经营了一家果汁店,虽然店里的鲜榨苹果汁深受大家喜爱,但客户总是抱怨制作果汁的速度太慢。小胡的店里只有一台榨汁机,每次他都会从篮子里拿出一个苹果,放到榨汁机内等待出汁。如果有8个客户,每个客户都点了一杯苹果汁,那么小胡需要重复循环8次上述的榨汁流程,才能榨出8杯苹果汁。如果制作一杯果汁需要5分钟,那么全部制作完毕则需要40分钟。为了提升果汁的制作速度,小胡想出了一个办法。他将榨汁机的数量从1台增加到了8台,这么一来,他就可以从篮子里一次性拿出8个苹果,分别放入8台榨汁机同时榨汁。此时,小胡只需要5分钟就能够制作出8杯苹果汁。为了制作n杯果汁,非向量化执行的方式是用1台榨汁机重复循环制作n次,而向量化执行的方式是用n台榨汁机只执行1次。
为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在CPU寄存器层面实现数据的并行操作。
在计算机系统的体系结构中,存储系统是一种层次结构。典型服务器计算机的存储层次结构如图1所示。一个实用的经验告诉我们,存储媒介距离CPU越近,则访问数据的速度越快。
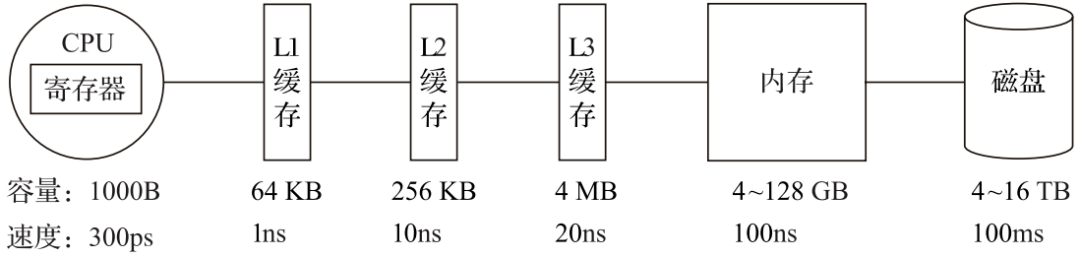
从上图中可以看到,从左向右,距离CPU越远,则数据的访问速度越慢。从寄存器中访问数据的速度,是从内存访问数据速度的300倍,是从磁盘中访问数据速度的3000万倍。所以利用CPU向量化执行的特性,对于程序的性能提升意义非凡。
ClickHouse目前利用SSE4.2指令集实现向量化执行。
04关系模型与SQL查询
相比HBase和Redis这类NoSQL数据库,ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。与此同时,ClickHouse完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL ),这使得它平易近人,容易理解和学习。因为关系型数据库和SQL语言,可以说是软件领域发展至今应用最为广泛的技术之一,拥有极高的"群众基础"。也正因为ClickHouse提供了标准协议的SQL查询接口,使得现有的第三方分析可视化系统可以轻松与它集成对接。在SQL解析方面,ClickHouse是大小写敏感的,这意味着SELECT a和SELECT A所代表的语义是不同的。
关系模型相比文档和键值对等其他模型,拥有更好的描述能力,也能够更加清晰地表述实体间的关系。更重要的是,在OLAP领域,已有的大量数据建模工作都是基于关系模型展开的(星型模型、雪花模型乃至宽表模型)。ClickHouse使用了关系模型,所以将构建在传统关系型数据库或数据仓库之上的系统迁移到ClickHouse的成本会变得更低,可以直接沿用之前的经验成果。
05多样化的表引擎
也许因为Yandex.Metrica的最初架构是基于MySQL实现的,所以在ClickHouse的设计中,能够察觉到一些MySQL的影子,表引擎的设计就是其中之一。与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。截至本书完稿时,ClickHouse共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。其中每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。
通常而言,一个通用系统意味着更广泛的适用性,能够适应更多的场景。但通用的另一种解释是平庸,因为它无法在所有场景内都做到极致。
在软件的世界中,并不会存在一个能够适用任何场景的通用系统,为了突出某项特性,势必会在别处有所取舍。其实世间万物都遵循着这样的道理,就像信天翁和蜂鸟,虽然都属于鸟类,但它们各自的特点却铸就了完全不同的体貌特征。信天翁擅长远距离飞行,环绕地球一周只需要1至2个月的时间。因为它能够长时间处于滑行状态,5天才需要扇动一次翅膀,心率能够保持在每分钟100至200次之间。而蜂鸟能够垂直悬停飞行,每秒可以挥动翅膀70~100次,飞行时的心率能够达到每分钟1000次。如果用数据库的场景类比信天翁和蜂鸟的特点,那么信天翁代表的可能是使用普通硬件就能实现高性能的设计思路,数据按粗粒度处理,通过批处理的方式执行;而蜂鸟代表的可能是按细粒度处理数据的设计思路,需要高性能硬件的支持。
将表引擎独立设计的好处是显而易见的,通过特定的表引擎支撑特定的场景,十分灵活。对于简单的场景,可直接使用简单的引擎降低成本,而复杂的场景也有合适的选择。
06多线程与分布式
ClickHouse几乎具备现代化高性能数据库的所有典型特征,对于可以提升性能的手段可谓是一一用尽,对于多线程和分布式这类被广泛使用的技术,自然更是不在话下。
如果说向量化执行是通过数据级并行的方式提升了性能,那么多线程处理就是通过线程级并行的方式实现了性能的提升。相比基于底层硬件实现的向量化执行SIMD,线程级并行通常由更高层次的软件层面控制。现代计算机系统早已普及了多处理器架构,所以现今市面上的服务器都具备良好的多核心多线程处理能力。由于SIMD不适合用于带有较多分支判断的场景,ClickHouse也大量使用了多线程技术以实现提速,以此和向量化执行形成互补。
如果一个篮子装不下所有的鸡蛋,那么就多用几个篮子来装,这就是分布式设计中分而治之的基本思想。同理,如果一台服务器性能吃紧,那么就利用多台服务的资源协同处理。为了实现这一目标,首先需要在数据层面实现数据的分布式。因为在分布式领域,存在一条金科玉律—计算移动比数据移动更加划算。在各服务器之间,通过网络传输数据的成本是高昂的,所以相比移动数据,更为聪明的做法是预先将数据分布到各台服务器,将数据的计算查询直接下推到数据所在的服务器。ClickHouse在数据存取方面,既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说是将多线程和分布式的技术应用到了极致。
07多主架构
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
08在线查询
ClickHouse经常会被拿来与其他的分析型数据库作对比,比如Vertica、SparkSQL、Hive和Elasticsearch等,它与这些数据库确实存在许多相似之处。例如,它们都可以支撑海量数据的查询场景,都拥有分布式架构,都支持列存、数据分片、计算下推等特性。这其实也侧面说明了ClickHouse在设计上确实吸取了各路奇技淫巧。与其他数据库相比,ClickHouse也拥有明显的优势。例如,Vertica这类商用软件价格高昂;SparkSQL与Hive这类系统无法保障90%的查询在1秒内返回,在大数据量下的复杂查询可能会需要分钟级的响应时间;而Elasticsearch这类搜索引擎在处理亿级数据聚合查询时则显得捉襟见肘。
正如ClickHouse的"广告词"所言,其他的开源系统太慢,商用的系统太贵,只有Clickouse在成本与性能之间做到了良好平衡,即又快又开源。ClickHouse当之无愧地阐释了"在线"二字的含义,即便是在复杂查询的场景下,它也能够做到极快响应,且无须对数据进行任何预处理加工。
09Leetcode超级会员数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量( 1个分片只能对应1个服务节点)。
ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表( Local Table )与分布式表( Distributed Table )的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。这就好比一辆手动挡赛车,它将所有的选择权都交到了使用者的手中。
云原生概念的诞生ClickHouse存储层
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
列式存储
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储。示例图如下:
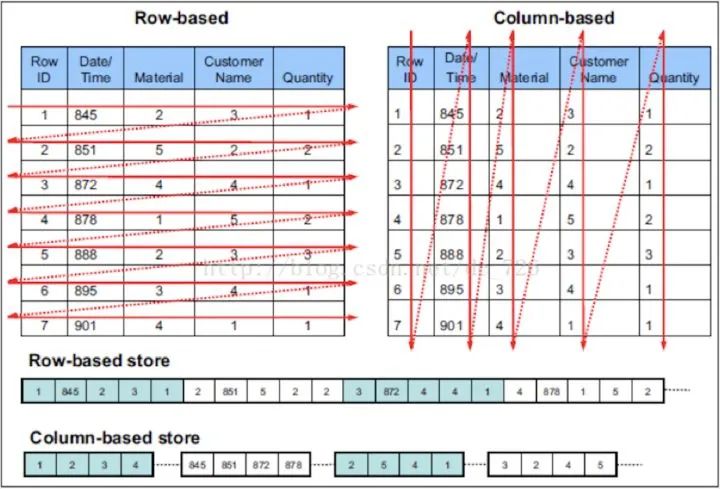
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
数据插入、更新、删除
Clickhouse是个分析型数据库。这种场景下,数据一般是不变的,因此Clickhouse对update、delete的支持是比较弱的,实际上并不支持标准的update、delete操作。
Clickhouse通过alter方式实现更新、删除,它把update、delete操作叫做mutation(突变)。
标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果(通常是int值);而Clickhouse的update、delete是通过异步方式实现的,当执行update语句时,服务端立即反回,但是实际上此时数据还没变,而是排队等着。
Mutation具体过程
首先,使用where条件找到需要修改的分区;然后,重建每个分区,用新的分区替换旧的,分区一旦被替换,就不可回退;对于每个分区,可以认为是原子性的;但对于整个mutation,如果涉及多个分区,则不是原子性的。
• 更新功能不支持更新有关主键或分区键的列。
• 更新操作没有原子性,即在更新过程中select结果很可能是一部分变了,一部分没变,从上边的具体过程就可以知道。
• 更新是按提交的顺序执行的。
• 更新一旦提交,不能撤销,即使重启Clickhouse服务,也会继续按照system.mutations的顺序继续执行。
• 已完成更新的条目不会立即删除,保留条目的数量由finished_mutations_to_keep存储引擎参数确定。超过数据量时旧的条目会被删除。
• 更新可能会卡住,比如update intvalue='abc’这种类型错误的更新语句执行不过去,那么会一直卡在这里,此时,可以使用KILL MUTATION来取消。
使用建议
按照官方的说明,update/delete的使用场景是一次更新大量数据,也就是where条件筛选的结果应该是一大片数据。
举例:alter table test update status=1 where status=0 and day='2020-04-01',一次更新一天的数据。
那么,能否一次只更新一条数据呢?例如:alter table test update pv=110 where id=100当然也可以,但频繁的这种操作,可能会对服务造成压力。这很容易理解,如上文提到,更新的单位是分区,如果只更新一条数据,那么需要重建一个分区;如果更新100条数据,而这100条可能落在3个分区上,则需重建3个分区;相对来说一次更新一批数据的整体效率远高于一次更新一行。对于频繁单条更新的这种场景,建议使用ReplacingMergeTree引擎来变相解决。具体如何使用,以后有时间再整理。
Hbase随机读写,但是Hbase的update操作不是真的update,它的实际操作是insert一条新的数据,打上不同的timestamp,而老的数据会在有效期之后自动删除。而Clickhouse干脆就不支持update和delete。
ClickHouse核心涉及模块
1. Column与Field
Column和Field是ClickHouse数据最基础的映射单元。作为一款百分之百的列式存储数据库,ClickHouse按列存储数据,内存中的一列数据由一个Column对象表示。Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等。在大多数场合,ClickHouse都会以整列的方式操作数据,但凡事也有例外。如果需要操作单个具体的数值(也就是单列中的一行数据),则需要使用Field对象,Field对象代表一个单值。与Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
2. DataType
数据的序列化和反序列化工作由DataType负责。IDataType接口定义了许多正反序列化的方法,它们成对出现,例如serializeBinary和deserializeBinary、serializeTextJSON和deserializeTextJSON等,涵盖了常用的二进制、文本、JSON、XML、CSV和Protobuf等多种格式类型。IDataType也使用了泛化的设计模式,具体方法的实现逻辑由对应数据类型的实例承载,例如DataTypeString、DataTypeArray及DataTypeTuple等。
DataType虽然负责序列化相关工作,但它并不直接负责数据的读取,而是转由从Column或Field对象获取。在DataType的实现类中,聚合了相应数据类型的Column对象和Field对象。例如,DataTypeString会引用字符串类型的ColumnString,而DataTypeArray则会引用数组类型的ColumnArray,以此类推。
3. Block与Block流
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。虽然Column和Filed组成了数据的基本映射单元,但对应到实际操作,它们还缺少了一些必要的信息,比如数据的类型及列的名称。于是ClickHouse设计了Block对象,Block对象可以看作数据表的子集。Block对象的本质是由数据对象、数据类型和列名称组成的三元组,即Column、DataType及列名称字符串。Column提供了数据的读取能力,而DataType知道如何正反序列化,所以Block在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过Block对象就能完成一系列的数据操作。在具体的实现过程中,Block并没有直接聚合Column和DataType对象,而是通过ColumnWithTypeAndName对象进行间接引用。
有了Block对象这一层封装之后,对Block流的设计就是水到渠成的事情了。流操作有两组顶层接口:IBlockInputStream负责数据的读取和关系运算,IBlockOutputStream负责将数据输出到下一环节。Block流也使用了泛化的设计模式,对数据的各种操作最终都会转换成其中一种流的实现。IBlockInputStream接口定义了读取数据的若干个read虚方法,而具体的实现逻辑则交由它的实现类来填充。
IBlockInputStream接口总共有60多个实现类,它们涵盖了ClickHouse数据摄取的方方面面。这些实现类大致可以分为三类:第一类用于处理数据定义的DDL操作,例如DDLQueryStatusInputStream等;第二类用于处理关系运算的相关操作,例如LimitBlockInput-Stream、JoinBlockInputStream及AggregatingBlockInputStream等;第三类则是与表引擎呼应,每一种表引擎都拥有与之对应的BlockInputStream实现,例如MergeTreeBaseSelect-BlockInputStream ( MergeTree表引擎)、TinyLogBlockInputStream ( TinyLog表引擎)及KafkaBlockInputStream ( Kafka表引擎)等。
IBlockOutputStream的设计与IBlockInputStream如出一辙。IBlockOutputStream接口同样也定义了若干写入数据的write虚方法。它的实现类比IBlockInputStream要少许多,一共只有20多种。这些实现类基本用于表引擎的相关处理,负责将数据写入下一环节或者最终目的地,例如MergeTreeBlockOutputStream、TinyLogBlockOutputStream及StorageFileBlock-OutputStream等。
4. Table
在数据表的底层设计中并没有所谓的Table对象,它直接使用IStorage接口指代数据表。表引擎是ClickHouse的一个显著特性,不同的表引擎由不同的子类实现,例如IStorageSystemOneBlock (系统表)、StorageMergeTree (合并树表引擎)和StorageTinyLog (日志表引擎)等。IStorage接口定义了DDL (如ALTER、RENAME、OPTIMIZE和DROP等)、read和write方法,它们分别负责数据的定义、查询与写入。在数据查询时,IStorage负责根据AST查询语句的指示要求,返回指定列的原始数据。后续对数据的进一步加工、计算和过滤,则会统一交由Interpreter解释器对象处理。对Table发起的一次操作通常都会经历这样的过程,接收AST查询语句,根据AST返回指定列的数据,之后再将数据交由Interpreter做进一步处理。
文章出处:【微信公众号:数据分析与开发】
责任编辑:gt
-
计算机
+关注
关注
19文章
7488浏览量
87849 -
服务器
+关注
关注
12文章
9123浏览量
85322 -
数据库
+关注
关注
7文章
3794浏览量
64360
原文标题:ClickHouse 特性及底层存储原理
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ClickHouse:强大的数据分析引擎

Sybase数据恢复—Sybase数据库无法启动怎么恢复数据?
oracle数据恢复—存储掉盘导致Oracle数据库文件大小变为0kb的数据恢复案例
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库

云数据库可以租用吗?完整租用流程来了
软件系统数据库的分库分表设计
数据库数据恢复—SqlServer数据库底层File Record被截断为0的数据恢复案例

数据库数据恢复—raid5阵列上层Sql Server数据库数据恢复案例






 工商网监
工商网监
评论