 新一代数据中心加速卡Alveo U55C,最大功耗低至150W
新一代数据中心加速卡Alveo U55C,最大功耗低至150W
(文/程文智)近年来,在数字化浪潮的推动下,传感器及其产生的数据量呈现出了爆炸式的增长,对数据处理基础架构的需求也随之增长。根据国际超级计算大会(ISC)的统计,在HPC领域,超算系统架构正变得越来越多元化,在近几年的TOP500超算榜单中,使用GPU、FPGA等加速卡的异构计算系统占比呈上升趋势。

图:Alveo U55C数据中心加速器卡
近日,赛灵思(Xilinx)在SC21全球超级计算大会上推出了新的Alveo U55C数据中心加速器卡,以及一款基于标准、API-driven 的集群解决方案,用于大规模部署 FPGA。据赛灵思数据中心事业部高性能计算( HPC )产品经理Nathan Chang介绍,Alveo U55C加速器卡结合了非常多当今HPC和大数据工作负载需要的关键功能。该加速器卡能够提供Alveo 加速器产品系列中的最高计算密度和 HBM2容量。结合赛灵思基于 RoCE v2 的全新集群解决方案,可令运行大规模计算工作负载的各类客户大获裨益,支持其利用现有数据中心基础架构和网络,实现强大的基于 FPGA 的 HPC 集群。

图:赛灵思数据中心事业部高性能计算( HPC )产品经理Nathan Chang
Alveo U55C最重要的特性
Alveo U55C卡融合了当前 HPC工作负载所需的众多关键特性。它能提供更高的数据流水线并行度、卓越的存储器管理、优化的整个流水线的数据迁移,以及Alveo产品系列中最高的单位功耗性能。
Alveo U55C与其前一代产品Alveo U280相比,有了很多升级。从外观上来看,Alveo U55C采用了单插槽、全高半长( FHHL )外形尺寸;从算力上来看,虽然Alveo U55C提供的算力没变,但体积更小了,计算密度得到了很大的提升;从功耗上来看,Alveo U55C的最大功耗为150W,而Alveo U280的功耗为225W。而且,Alveo U55C还将HBM2的容量翻倍至16GB。
Nathan Chang解释说,功耗降低的原因是Alveo U55C去掉了DDR,在存储器卡方面让HBM2增加了一倍,这就相当于让高带宽的数量增加了4倍,由于去掉了DDR,所以Alveo U55C整个TDP功耗也下降了。

图:Alveo U55C与其前一代产品Alveo U280的参数对比
在Nathan Chang看来,Alveo U55C有三个非常重要的特性:一是采用了RoCE v2、DCBx,还有MPI,在现有网络和基础架构上,为现在的数据中心提供了最尖端的计算集群。第二,现有的应用开发人员可以利用Vitis平台上的一些已有的API、库以及MPI,来扩展他们的工作负载。第三就是高性能。
据他介绍,通过RoCE v2和 DCBx技术,再结合200 Gbps带宽,Alveo U55C构建的集群解决方案使Alveo网络可在性能和时延方面媲美 InfiniBand 网络,且无需对厂商加锁。MPI (信息传递接口)集成功能使 HPC 开发人员能以赛灵思 Vitis统一软件平台扩展Alveo数据流水线。利用现有开放标准和框架,现在能跨数百张 Alveo 卡上进行性能扩展,无需考虑服务器平台和网络基础架构,同时还能共享工作负载和存储器。

借助面向应用和集群的高层次编程,软件开发者和数据科学家能够运用 Vitis 平台,解锁 Alveo 和自适应计算的优势。赛灵思大力投入于 Vitis 开发平台和工具流程,旨在令不具备硬件专业知识的软件开发者和数据科学家,也能更容易地使用自适应计算。Vitis 平台支持 Pytorch 和 Tensorflow 等主流 AI 框架,还支持 C、C++ 和 Python 等高层次编程语言,使开发者能利用特定 API 和库来构建领域解决方案,或者使用赛灵思软件开发套件,从而在现有数据中心内轻松加速关键 HPC 工作负载。
应用案例
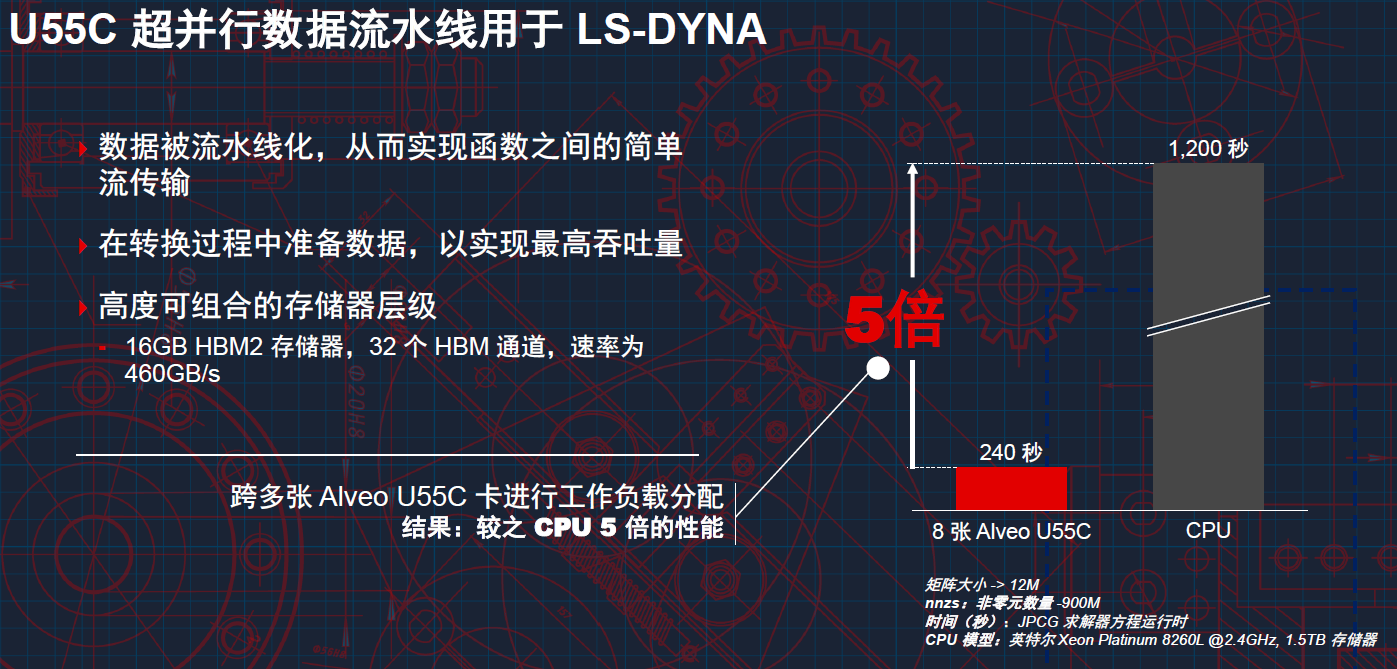
谈到Alveo U55C的应用,Nathan Chang列举了几个常用的应用场景,比如几乎每一家汽车厂商都会用到的碰撞仿真软件LS-DYNA。汽车厂商主要是用它赖进行汽车的撞击测试,以便查看仿真效果,确保汽车在设计方面的安全性和结构方面的完整性。而安全性和结构系统的设计往往取决于模型性能,因其能以计算机辅助设计有限元方法( FEM )仿真来降低物理碰撞测试的成本。FEM求解器是驱动具备数亿个自由度仿真的主要算法,而这些庞大的算法可以细分为更基本的求解器,如 PCG、稀疏矩阵、ICCG。与 x86 CPU 相比,利用超并行数据流水线在大量 Alveo 卡上进行性能扩展,LS-DYNA 能够实现超过 5 倍的性能加速。这能在一个 Alveo 流水线中提高单位时钟周期的工作效率,令 LS-DYNA 客户受益于突破性的仿真时间。
另外,他还介绍了一个图分析的案例,“在加入赛灵思之前,我是一个创业者,当时我处于油气行业,主要做的工作是做地壳震动图解决的AI和机器学习。我们知道,数据工程师、科学家、分析师在处理此类课题的时候,都会寻找数据的一些相关性。在寻找的过程中,我们发现了一个巨大的痛点,那就是数据的孤岛越来越多,如果想要把这些不同孤岛上的数据联系起来,真的非常困难。”他感叹。
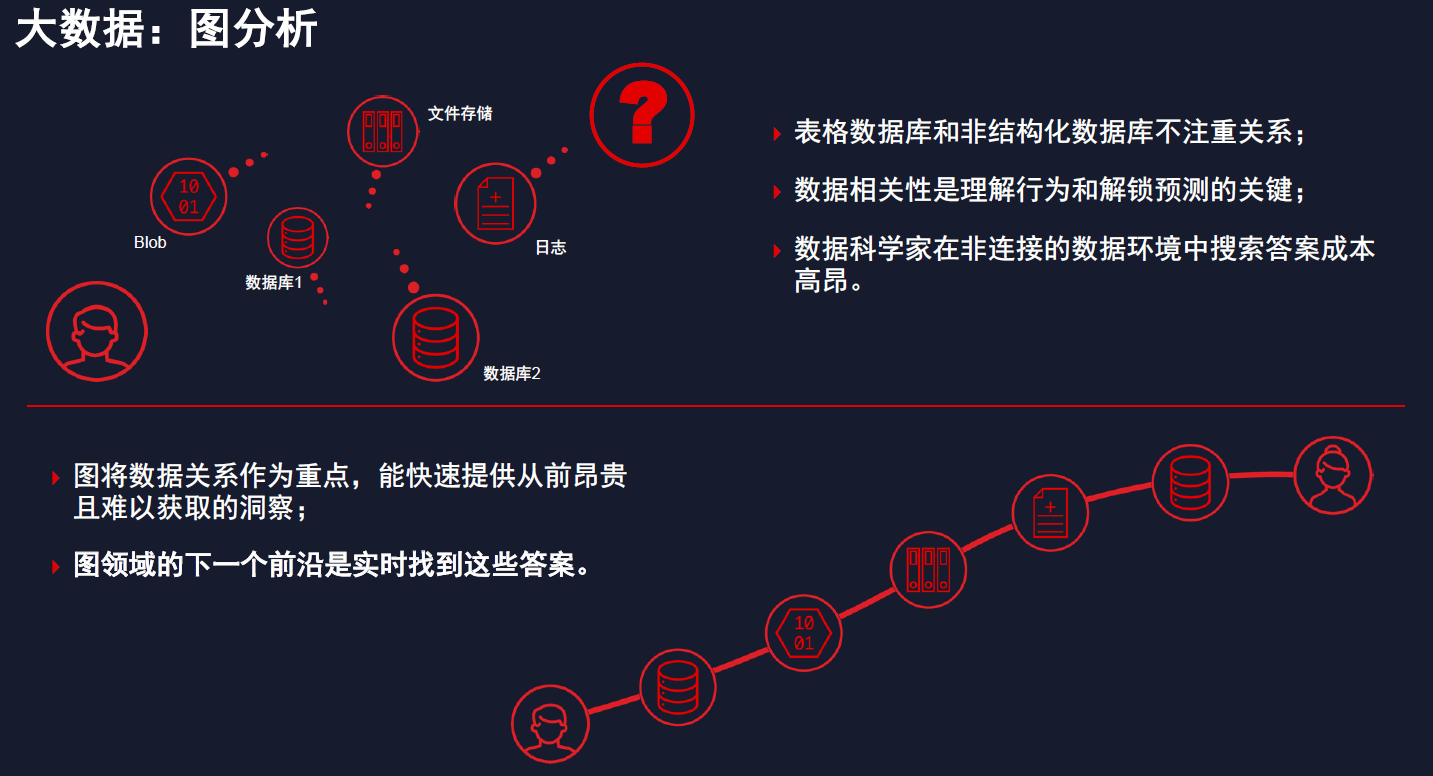
不过,Nathan Chang表示,图库数据是科学家认为非常具有颠覆性的一个平台,它能够将数据从孤岛中提取出来,让偶让数据科学家可以专注于数据之间的关系,而不是看单张图。赛灵思的合作伙伴,TigerGraph 是一家图分析平台提供商,他们正使用多张 Alveo U55C 卡为两种最高效算法进行集群与加速,以驱动基于图的推荐和集群引擎。图从信息孤岛中采集数据并重点关注数据间的关系。图领域的下一个前沿是实时查找答案。Alveo U55C 将推荐引擎的查询和预测时间从数分钟缩短至数毫秒。与基于 CPU 的集群相比,使用多张 U55C 卡扩展分析所提供的出色计算能力和存储器带宽,可将图查询速度提升高达 45 倍。质量评分也提升高达 35%,从而显著提升置信度,将误报几率降至低个位数
另外,他还列举了Alveo U55C在信号处理、医疗和金融方面的应用。
总结
随着高性能计算迈向百亿亿级大关,功耗将成为下一个难关。而典型的高性能计算架构,即CPU和GPU的架构,难以提供可接收的单位功耗性能,因此,现在越来越多的高性能计算集群开始采用一机构计算架构,预计未来将会有更多的算力会部署在专门的加速器上,而不是通用CPU上。对于整个HPC服务器集群的降功耗目标来说,使用加速器卡的效果更好,功耗更低。未来加速器卡的市场前景将会更加广阔。
-
FPGA
+关注
关注
1629文章
21729浏览量
602984 -
图像处理
+关注
关注
27文章
1289浏览量
56722 -
异构计算
+关注
关注
2文章
100浏览量
16294
发布评论请先 登录
相关推荐
AMD Alveo媒体加速产品组合SDK 1.2.1发布
PCIe加速卡在数据中心的应用
AMD 以全球极快的纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力广泛且具性价比的服务器部署

AMD 以全球极快的纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力广泛且具性价比的服务器部署
AMD推出新款纤薄尺寸电子交易加速卡
EPSON差分晶振SG3225VEN频点312.5mhz应用于AI加速卡
东盟能源和华为主编的《东盟下一代数据中心建设白皮书》正式发布

借助全新 AMD Alveo™ V80 计算加速卡释放计算能力

AMD Alveo V80计算加速卡实现量产
储能逆变器最大功率有多大?储能逆变器最大可以逆变多少w
1A、3V至17V、–55°C至+150°C低IQ 降压转换器TPS629210E数据表

英伟达发布最强AI加速卡Blackwell GB200
1A、3V 至 17V、–55°C 至 +150°C 低 IQ 降压转换器TPS629210E数据表





 工商网监
工商网监
评论