 FPGA, CPU, GPU, ASIC区别,为什么使用FPGA?
FPGA, CPU, GPU, ASIC区别,为什么使用FPGA?
一、为什么使用 FPGA?
众所周知,通用处理器(CPU)的摩尔定律已入暮年,而机器学习和 Web 服务的规模却在指数级增长。
人们使用定制硬件来加速常见的计算任务,然而日新月异的行业又要求这些定制的硬件可被重新编程来执行新类型的计算任务。
FPGA 正是一种硬件可重构的体系结构。它的英文全称是Field Programmable Gate Array,中文名是现场可编程门阵列。
FPGA常年来被用作专用芯片(ASIC)的小批量替代品,然而近年来在微软、百度等公司的数据中心大规模部署,以同时提供强大的计算能力和足够的灵活性。
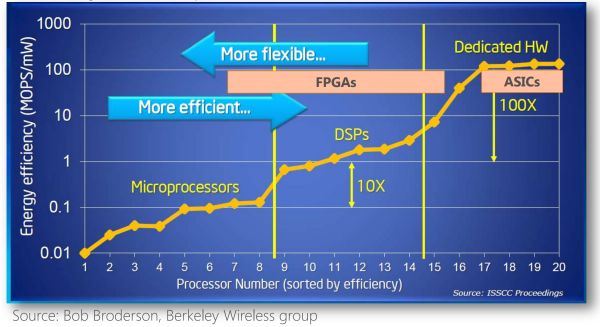
不同体系结构性能和灵活性的比较
FPGA 为什么快?「都是同行衬托得好」。
CPU、GPU 都属于冯·诺依曼结构,指令译码执行、共享内存。FPGA 之所以比 CPU 甚至 GPU 能效高,本质上是无指令、无需共享内存的体系结构带来的福利。
冯氏结构中,由于执行单元(如 CPU 核)可能执行任意指令,就需要有指令存储器、译码器、各种指令的运算器、分支跳转处理逻辑。由于指令流的控制逻辑复杂,不可能有太多条独立的指令流,因此 GPU 使用 SIMD(单指令流多数据流)来让多个执行单元以同样的步调处理不同的数据,CPU 也支持 SIMD 指令。
而 FPGA 每个逻辑单元的功能在重编程(烧写)时就已经确定,不需要指令
冯氏结构中使用内存有两种作用。一是保存状态,二是在执行单元间通信。
由于内存是共享的,就需要做访问仲裁;为了利用访问局部性,每个执行单元有一个私有的缓存,这就要维持执行部件间缓存的一致性。
对于保存状态的需求,FPGA 中的寄存器和片上内存(BRAM)是属于各自的控制逻辑的,无需不必要的仲裁和缓存。
对于通信的需求,FPGA 每个逻辑单元与周围逻辑单元的连接在重编程(烧写)时就已经确定,并不需要通过共享内存来通信。
说了这么多三千英尺高度的话,FPGA 实际的表现如何呢?我们分别来看计算密集型任务和通信密集型任务。
计算密集型任务的例子包括矩阵运算、图像处理、机器学习、压缩、非对称加密、Bing 搜索的排序等。这类任务一般是 CPU 把任务卸载(offload)给 FPGA 去执行。对这类任务,目前我们正在用的 Altera(似乎应该叫 Intel 了,我还是习惯叫 Altera……)Stratix V FPGA 的整数乘法运算性能与 20 核的 CPU 基本相当,浮点乘法运算性能与 8 核的 CPU 基本相当,而比 GPU 低一个数量级。我们即将用上的下一代 FPGA,Stratix 10,将配备更多的乘法器和硬件浮点运算部件,从而理论上可达到与现在的顶级 GPU 计算卡旗鼓相当的计算能力。
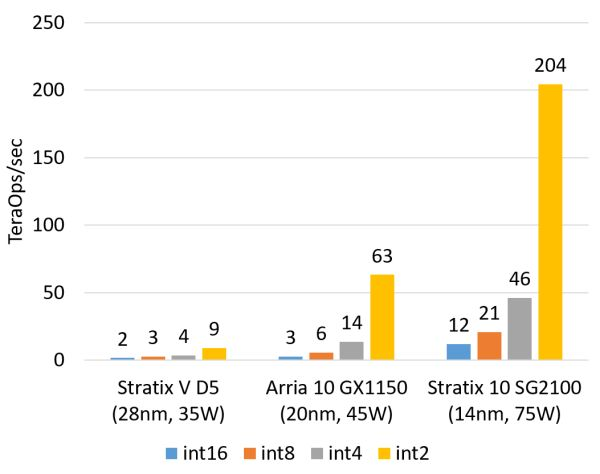
FPGA 的整数乘法运算能力(估计值,不使用 DSP,根据逻辑资源占用量估计)
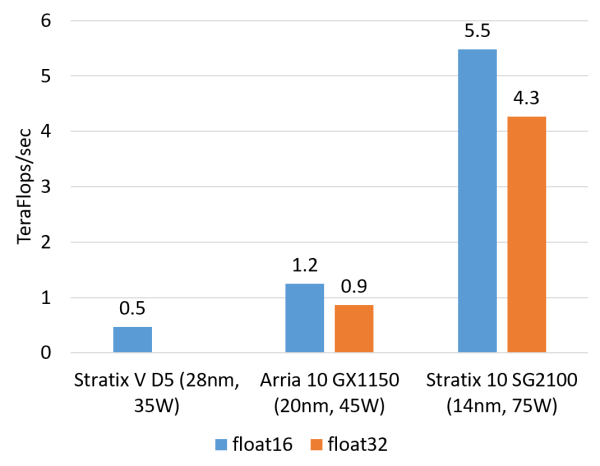
FPGA 的浮点乘法运算能力(估计值,float16 用软核,float 32 用硬核)
在数据中心,FPGA 相比 GPU 的核心优势在于延迟。
像 Bing 搜索排序这样的任务,要尽可能快地返回搜索结果,就需要尽可能降低每一步的延迟
如果使用 GPU 来加速,要想充分利用 GPU 的计算能力,batch size 就不能太小,延迟将高达毫秒量级。
使用 FPGA 来加速的话,只需要微秒级的 PCIe 延迟(我们现在的 FPGA 是作为一块 PCIe 加速卡)。
未来 Intel 推出通过 QPI 连接的 Xeon + FPGA 之后,CPU 和 FPGA 之间的延迟更可以降到 100 纳秒以下,跟访问主存没什么区别了。
FPGA 为什么比 GPU 的延迟低这么多?
这本质上是体系结构的区别。
FPGA 同时拥有流水线并行和数据并行,而 GPU 几乎只有数据并行(流水线深度受限)。
例如处理一个数据包有 10 个步骤,FPGA 可以搭建一个 10 级流水线,流水线的不同级在处理不同的数据包,每个数据包流经 10 级之后处理完成。每处理完成一个数据包,就能马上输出。
而 GPU 的数据并行方法是做 10 个计算单元,每个计算单元也在处理不同的数据包,然而所有的计算单元必须按照统一的步调,做相同的事情(SIMD,Single Instruction Multiple Data)。这就要求 10 个数据包必须一起输入、一起输出,输入输出的延迟增加了。
当任务是逐个而非成批到达的时候,流水线并行比数据并行可实现更低的延迟。因此对流式计算的任务,FPGA 比 GPU 天生有延迟方面的优势。
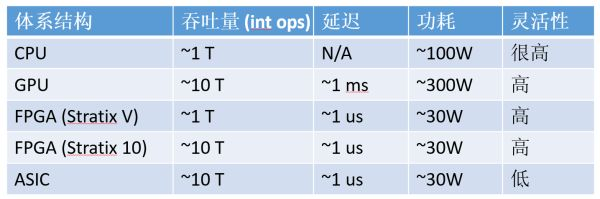
计算密集型任务,CPU、GPU、FPGA、ASIC 的数量级比较(以 16 位整数乘法为例,数字仅为数量级的估计
ASIC 专用芯片在吞吐量、延迟和功耗三方面都无可指摘,但微软并没有采用,出于两个原因:
数据中心的计算任务是灵活多变的,而 ASIC 研发成本高、周期长。好不容易大规模部署了一批某种神经网络的加速卡,结果另一种神经网络更火了,钱就白费了。FPGA 只需要几百毫秒就可以更新逻辑功能。FPGA 的灵活性可以保护投资,事实上,微软现在的 FPGA 玩法与最初的设想大不相同。
数据中心是租给不同的租户使用的,如果有的机器上有神经网络加速卡,有的机器上有 Bing 搜索加速卡,有的机器上有网络虚拟化加速卡,任务的调度和服务器的运维会很麻烦。使用 FPGA 可以保持数据中心的同构性。
接下来看通信密集型任务。
相比计算密集型任务,通信密集型任务对每个输入数据的处理不甚复杂,基本上简单算算就输出了,这时通信往往会成为瓶颈。对称加密、防火墙、网络虚拟化都是通信密集型的例子。
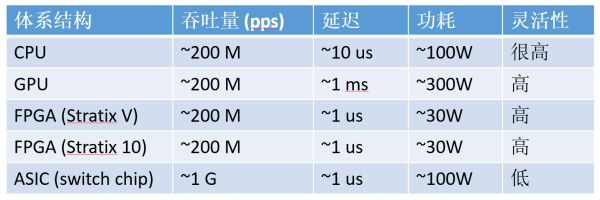
通信密集型任务,CPU、GPU、FPGA、ASIC 的数量级比较(以 64 字节网络数据包处理为例,数字仅为数量级的估计)
对通信密集型任务,FPGA 相比 CPU、GPU 的优势就更大了。
从吞吐量上讲,FPGA 上的收发器可以直接接上 40 Gbps 甚至 100 Gbps 的网线,以线速处理任意大小的数据包;而 CPU 需要从网卡把数据包收上来才能处理,很多网卡是不能线速处理 64 字节的小数据包的。尽管可以通过插多块网卡来达到高性能,但 CPU 和主板支持的 PCIe 插槽数量往往有限,而且网卡、交换机本身也价格不菲。
从延迟上讲,网卡把数据包收到 CPU,CPU 再发给网卡,即使使用 DPDK 这样高性能的数据包处理框架,延迟也有 4~5 微秒。更严重的问题是,通用 CPU 的延迟不够稳定。例如当负载较高时,转发延迟可能升到几十微秒甚至更高(如下图所示);现代操作系统中的时钟中断和任务调度也增加了延迟的不确定性。
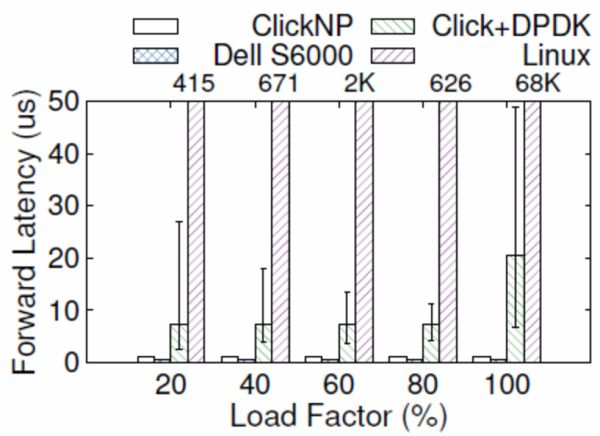
ClickNP(FPGA)与 Dell S6000 交换机(商用交换机芯片)、Click+DPDK(CPU)和 Linux(CPU)的转发延迟比较,error bar 表示 5% 和 95%。来源:[5
虽然 GPU 也可以高性能处理数据包,但 GPU 是没有网口的,意味着需要首先把数据包由网卡收上来,再让 GPU 去做处理。这样吞吐量受到 CPU 和/或网卡的限制。GPU 本身的延迟就更不必说了。
那么为什么不把这些网络功能做进网卡,或者使用可编程交换机呢?ASIC 的灵活性仍然是硬伤。
尽管目前有越来越强大的可编程交换机芯片,比如支持 P4 语言的 Tofino,ASIC 仍然不能做复杂的有状态处理,比如某种自定义的加密算法。
综上,在数据中心里 FPGA 的主要优势是稳定又极低的延迟,适用于流式的计算密集型任务和通信密集型任务。
二、微软部署 FPGA 的实践
2016 年 9 月,《连线》(Wired)杂志发表了一篇《微软把未来押注在 FPGA 上》的报道 [3],讲述了 Catapult 项目的前世今生。
紧接着,Catapult 项目的老大 Doug Burger 在 Ignite 2016 大会上与微软 CEO Satya Nadella 一起做了 FPGA 加速机器翻译的演
演示的总计算能力是 103 万 T ops,也就是 1.03 Exa-op,相当于 10 万块顶级 GPU 计算卡。一块 FPGA(加上板上内存和网络接口等)的功耗大约是 30 W,仅增加了整个服务器功耗的十分之一。
Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的机器翻译运算能力
微软部署 FPGA 并不是一帆风顺的。对于把 FPGA 部署在哪里这个问题,大致经历了三个阶段:
专用的 FPGA 集群,里面插满了 FPGA
每台机器一块 FPGA,采用专用网络连接
每台机器一块 FPGA,放在网卡和交换机之间,共享服务器网络
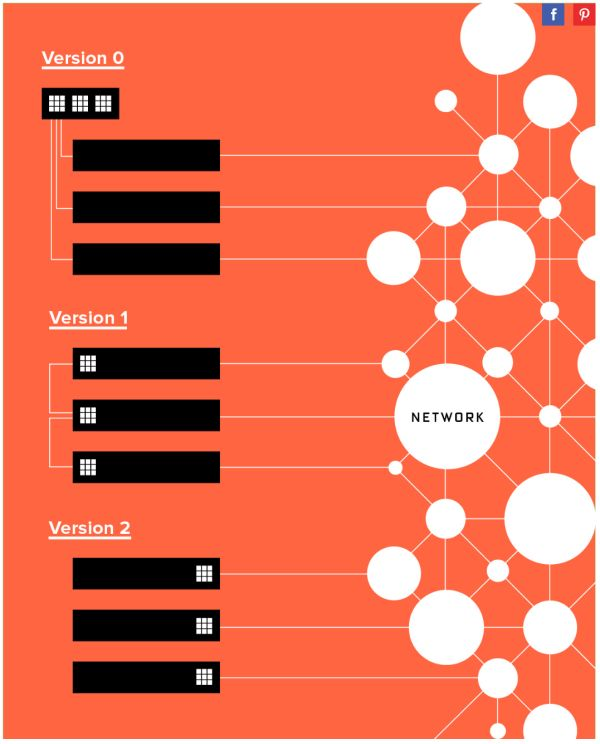
微软 FPGA 部署方式的三个阶段,来源:[3]
第一个阶段是专用集群,里面插满了 FPGA 加速卡,就像是一个 FPGA 组成的超级计算机。
下图是最早的 BFB 实验板,一块 PCIe 卡上放了 6 块 FPGA,每台 1U 服务器上又插了 4 块 PCIe 卡。

最早的 BFB 实验板,上面放了 6 块 FPGA。
可以注意到该公司的名字。在半导体行业,只要批量足够大,芯片的价格都将趋向于沙子的价格。据传闻,正是由于该公司不肯给「沙子的价格」 ,才选择了另一家公
当然现在数据中心领域用两家公司 FPGA 的都有。只要规模足够大,对 FPGA 价格过高的担心将是不必要的。
最早的 BFB 实验板,1U 服务器上插了 4 块 FPGA 卡。
像超级计算机一样的部署方式,意味着有专门的一个机柜全是上图这种装了 24 块 FPGA 的服务器(下图左)。
这种方式有几个问题:
不同机器的 FPGA 之间无法通信,FPGA 所能处理问题的规模受限于单台服务器上 FPGA 的数量;
数据中心里的其他机器要把任务集中发到这个机柜,构成了 in-cast,网络延迟很难做到稳定。
FPGA 专用机柜构成了单点故障,只要它一坏,谁都别想加速了;
装 FPGA 的服务器是定制的,冷却、运维都增加了麻烦。

部署 FPGA 的三种方式,从中心化到分布式。来源:[1]
一种不那么激进的方式是,在每个机柜一面部署一台装满 FPGA 的服务器(上图中)。这避免了上述问题 (2)(3),但 (1)(4) 仍然没有解决。
第二个阶段,为了保证数据中心中服务器的同构性(这也是不用 ASIC 的一个重要原因),在每台服务器上插一块 FPGA(上图右),FPGA 之间通过专用网络连接。这也是微软在 ISCA'14 上所发表论文采用的部署方式。

Open Compute Server 在机架中。

Open Compute Server 内景。红框是放 FPGA 的位置。

插入 FPGA 后的 Open Compute Server。

FPGA 与 Open Compute Server 之间的连接与固定。来源:[1]
FPGA 采用 Stratix V D5,有 172K 个 ALM,2014 个 M20K 片上内存,1590 个 DSP。板上有一个 8GB DDR3-1333 内存,一个 PCIe Gen3 x8 接口,两个 10 Gbps 网络接口。一个机柜之间的 FPGA 采用专用网络连接,一组 10G 网口 8 个一组连成环,另一组 10G 网口 6 个一组连成环,不使用交换机。
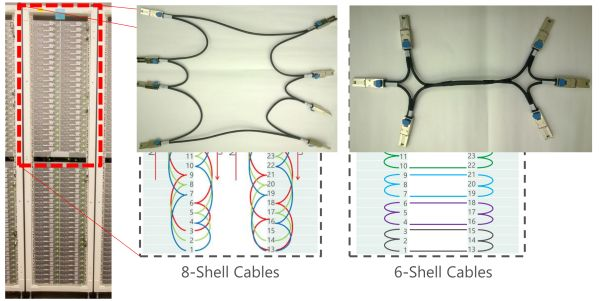
机柜中 FPGA 之间的网络连接方式。来源:[1]
这样一个 1632 台服务器、1632 块 FPGA 的集群,把 Bing 的搜索结果排序整体性能提高到了 2 倍(换言之,节省了一半的服务器)。
如下图所示,每 8 块 FPGA 穿成一条链,中间用前面提到的 10 Gbps 专用网线来通信。这 8 块 FPGA 各司其职,有的负责从文档中提取特征(黄色),有的负责计算特征表达式(绿色),有的负责计算文档的得分(红色)。
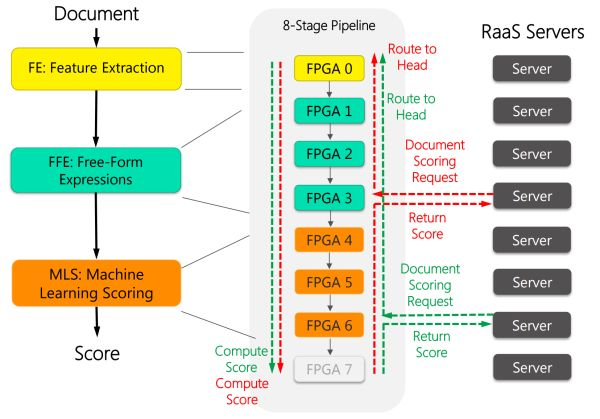
FPGA 加速 Bing 的搜索排序过程。来源:[1]
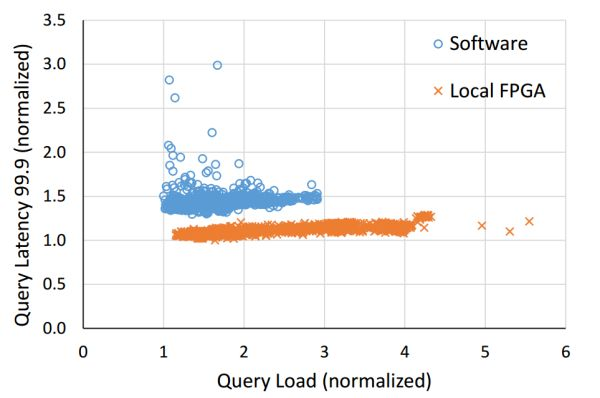
FPGA 不仅降低了 Bing 搜索的延迟,还显著提高了延迟的稳定性。来源:[4]
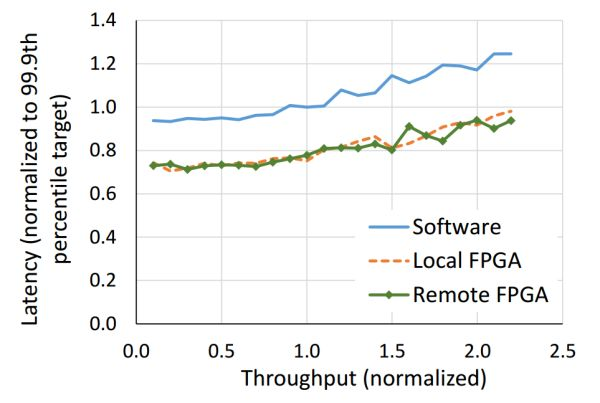
本地和远程的 FPGA 均可以降低搜索延迟,远程 FPGA 的通信延迟相比搜索延迟可忽略。来源:[4]
FPGA 在 Bing 的部署取得了成功,Catapult 项目继续在公司内扩张。
微软内部拥有最多服务器的,就是云计算 Azure 部门了。
Azure 部门急需解决的问题是网络和存储虚拟化带来的开销。Azure 把虚拟机卖给客户,需要给虚拟机的网络提供防火墙、负载均衡、隧道、NAT 等网络功能。由于云存储的物理存储跟计算节点是分离的,需要把数据从存储节点通过网络搬运过来,还要进行压缩和加密。
在 1 Gbps 网络和机械硬盘的时代,网络和存储虚拟化的 CPU 开销不值一提。随着网络和存储速度越来越快,网络上了 40 Gbps,一块 SSD 的吞吐量也能到 1 GB/s,CPU 渐渐变得力不从心了。
例如 Hyper-V 虚拟交换机只能处理 25 Gbps 左右的流量,不能达到 40 Gbps 线速,当数据包较小时性能更差;AES-256 加密和 SHA-1 签名,每个 CPU 核只能处理 100 MB/s,只是一块 SSD 吞吐量的十分之一。
网络隧道协议、防火墙处理 40 Gbps 需要的 CPU 核数。来源:[5]
为了加速网络功能和存储虚拟化,微软把 FPGA 部署在网卡和交换机之间。
如下图所示,每个 FPGA 有一个 4 GB DDR3-1333 DRAM,通过两个 PCIe Gen3 x8 接口连接到一个 CPU socket(物理上是 PCIe Gen3 x16 接口,因为 FPGA 没有 x16 的硬核,逻辑上当成两个 x8 的用)。物理网卡(NIC)就是普通的 40 Gbps 网卡,仅用于宿主机与网络之间的通信。
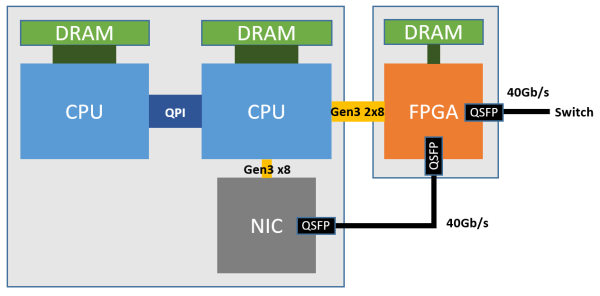
Azure 服务器部署 FPGA 的架构。来源:[6]
FPGA(SmartNIC)对每个虚拟机虚拟出一块网卡,虚拟机通过 SR-IOV 直接访问这块虚拟网卡。原本在虚拟交换机里面的数据平面功能被移到了 FPGA 里面,虚拟机收发网络数据包均不需要 CPU 参与,也不需要经过物理网卡(NIC)。这样不仅节约了可用于出售的 CPU 资源,还提高了虚拟机的网络性能(25 Gbps),把同数据中心虚拟机之间的网络延迟降低了 10 倍。
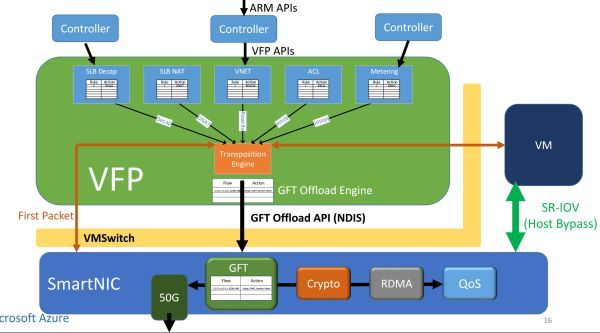
网络虚拟化的加速架构。来源:[6]
这就是微软部署 FPGA 的第三代架构,也是目前「每台服务器一块 FPGA」大规模部署所采用的架构。
FPGA 复用主机网络的初心是加速网络和存储,更深远的影响则是把 FPGA 之间的网络连接扩展到了整个数据中心的规模,做成真正 cloud-scale 的「超级计算机」。
第二代架构里面,FPGA 之间的网络连接局限于同一个机架以内,FPGA 之间专网互联的方式很难扩大规模,通过 CPU 来转发则开销太高。
第三代架构中,FPGA 之间通过 LTL (Lightweight Transport Layer) 通信。同一机架内延迟在 3 微秒以内;8 微秒以内可达 1000 块 FPGA;20 微秒可达同一数据中心的所有 FPGA。第二代架构尽管 8 台机器以内的延迟更低,但只能通过网络访问 48 块 FPGA。为了支持大范围的 FPGA 间通信,第三代架构中的 LTL 还支持 PFC 流控协议和 DCQCN 拥塞控制协议。
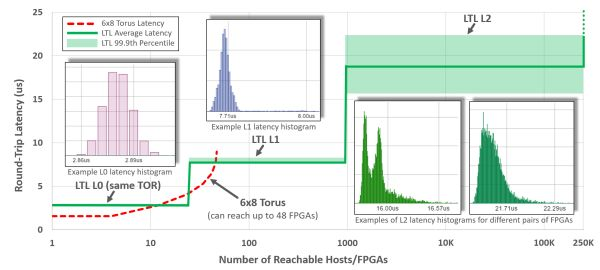
纵轴:LTL 的延迟,横轴:可达的 FPGA 数量。来源:[4]
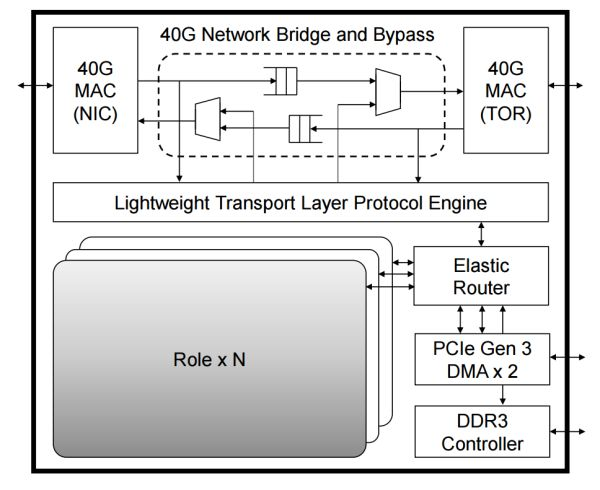
FPGA 内的逻辑模块关系,其中每个 Role 是用户逻辑(如 DNN 加速、网络功能加速、加密),外面的部分负责各个 Role 之间的通信及 Role 与外设之间的通信。来源:[4]
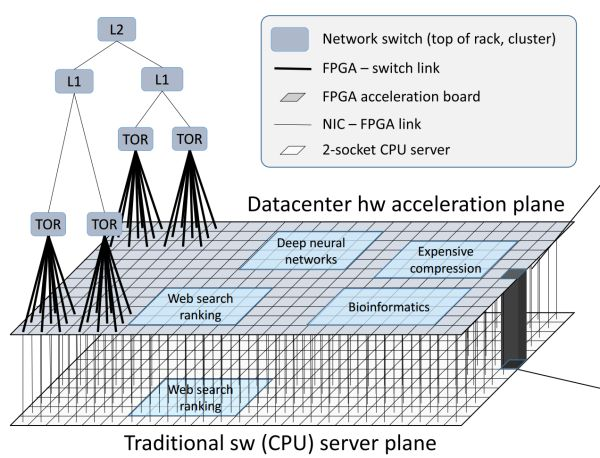
FPGA 构成的数据中心加速平面,介于网络交换层(TOR、L1、L2)和传统服务器软件(CPU 上运行的软件)之间。来源:[4]
通过高带宽、低延迟的网络互联的 FPGA 构成了介于网络交换层和传统服务器软件之间的数据中心加速平面。
除了每台提供云服务的服务器都需要的网络和存储虚拟化加速,FPGA 上的剩余资源还可以用来加速 Bing 搜索、深度神经网络(DNN)等计算任务。
对很多类型的应用,随着分布式 FPGA 加速器的规模扩大,其性能提升是超线性的。
例如 CNN inference,当只用一块 FPGA 的时候,由于片上内存不足以放下整个模型,需要不断访问 DRAM 中的模型权重,性能瓶颈在 DRAM;如果 FPGA 的数量足够多,每块 FPGA 负责模型中的一层或者一层中的若干个特征,使得模型权重完全载入片上内存,就消除了 DRAM 的性能瓶颈,完全发挥出 FPGA 计算单元的性能。
当然,拆得过细也会导致通信开销的增加。把任务拆分到分布式 FPGA 集群的关键在于平衡计算和通信。
从神经网络模型到 HaaS 上的 FPGA。利用模型内的并行性,模型的不同层、不同特征映射到不同 FPGA。来源:[4]
在 MICRO'16 会议上,微软提出了 Hardware as a Service (HaaS) 的概念,即把硬件作为一种可调度的云服务,使得 FPGA 服务的集中调度、管理和大规模部署成为可能。
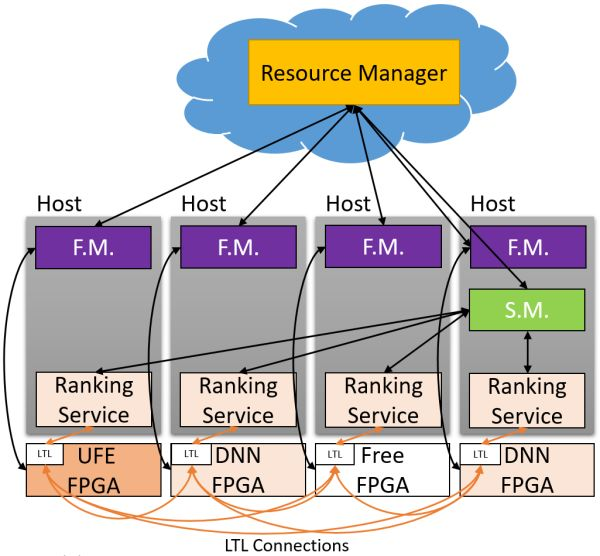
Hardware as a Service (HaaS)。来源:[4]
从第一代装满 FPGA 的专用服务器集群,到第二代通过专网连接的 FPGA 加速卡集群,到目前复用数据中心网络的大规模 FPGA 云,三个思想指导我们的路线:
硬件和软件不是相互取代的关系,而是合作的关系;
必须具备灵活性,即用软件定义的能力;
必须具备可扩放性(scalability)。
三、FPGA 在云计算中的角色
FPGA 在云规模的网络互连系统中应当充当怎样的角色?
如何高效、可扩放地对 FPGA + CPU 的异构系统进行编程?
我对 FPGA 业界主要的遗憾是,FPGA 在数据中心的主流用法,从除微软外的互联网巨头,到两大 FPGA 厂商,再到学术界,大多是把 FPGA 当作跟 GPU 一样的计算密集型任务的加速卡。然而 FPGA 真的很适合做 GPU 的事情吗?
前面讲过,FPGA 和 GPU 最大的区别在于体系结构,FPGA 更适合做需要低延迟的流式处理,GPU 更适合做大批量同构数据的处理。
由于很多人打算把 FPGA 当作计算加速卡来用,两大 FPGA 厂商推出的高层次编程模型也是基于 OpenCL,模仿 GPU 基于共享内存的批处理模式。CPU 要交给 FPGA 做一件事,需要先放进 FPGA 板上的 DRAM,然后告诉 FPGA 开始执行,FPGA 把执行结果放回 DRAM,再通知 CPU 去取回。
CPU 和 FPGA 之间本来可以通过 PCIe 高效通信,为什么要到板上的 DRAM 绕一圈?也许是工程实现的问题,我们发现通过 OpenCL 写 DRAM、启动 kernel、读 DRAM 一个来回,需要 1.8 毫秒。而通过 PCIe DMA 来通信,却只要 1~2 微秒。
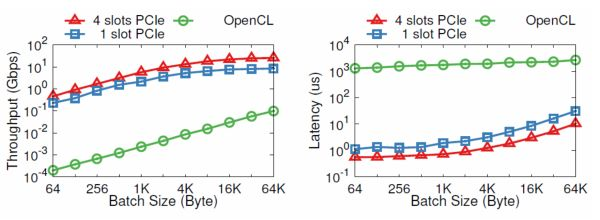
PCIe I/O channel 与 OpenCL 的性能比较。纵坐标为对数坐标。来源:[5
OpenCL 里面多个 kernel 之间的通信就更夸张了,默认的方式也是通过共享内存。
本文开篇就讲,FPGA 比 CPU 和 GPU 能效高,体系结构上的根本优势是无指令、无需共享内存。使用共享内存在多个 kernel 之间通信,在顺序通信(FIFO)的情况下是毫无必要的。况且 FPGA 上的 DRAM 一般比 GPU 上的 DRAM 慢很多。
因此我们提出了 ClickNP 网络编程框架 [5],使用管道(channel)而非共享内存来在执行单元(element/kernel)间、执行单元和主机软件间进行通信。
需要共享内存的应用,也可以在管道的基础上实现,毕竟 CSP(Communicating Sequential Process)和共享内存理论上是等价的嘛。ClickNP 目前还是在 OpenCL 基础上的一个框架,受到 C 语言描述硬件的局限性(当然 HLS 比 Verilog 的开发效率确实高多了)。理想的硬件描述语言,大概不会是 C 语言吧。
ClickNP 使用 channel 在 elements 间通信,来源:[5]
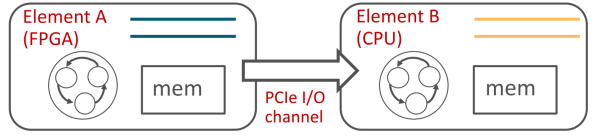
ClickNP 使用 channel 在 FPGA 和 CPU 间通信,来源:[5]
低延迟的流式处理,需要最多的地方就是通信。
然而CPU 由于并行性的限制和操作系统的调度,做通信效率不高,延迟也不稳定。
此外,通信就必然涉及到调度和仲裁,CPU 由于单核性能的局限和核间通信的低效,调度、仲裁性能受限,硬件则很适合做这种重复工作。因此我的博士研究把 FPGA 定义为通信的「大管家」,不管是服务器跟服务器之间的通信,虚拟机跟虚拟机之间的通信,进程跟进程之间的通信,CPU 跟存储设备之间的通信,都可以用 FPGA 来加速。
成也萧何,败也萧何。缺少指令同时是 FPGA 的优势和软肋。
每做一点不同的事情,就要占用一定的 FPGA 逻辑资源。如果要做的事情复杂、重复性不强,就会占用大量的逻辑资源,其中的大部分处于闲置状态。这时就不如用冯·诺依曼结构的处理器。
数据中心里的很多任务有很强的局部性和重复性:一部分是虚拟化平台需要做的网络和存储,这些都属于通信;另一部分是客户计算任务里的,比如机器学习、加密解密。
首先把 FPGA 用于它最擅长的通信,日后也许也会像 AWS 那样把 FPGA 作为计算加速卡租给客户。
不管通信还是机器学习、加密解密,算法都是很复杂的,如果试图用 FPGA 完全取代 CPU,势必会带来 FPGA 逻辑资源极大的浪费,也会提高 FPGA 程序的开发成本。更实用的做法是FPGA 和 CPU 协同工作,局部性和重复性强的归 FPGA,复杂的归 CPU。
当我们用 FPGA 加速了 Bing 搜索、深度学习等越来越多的服务;当网络虚拟化、存储虚拟化等基础组件的数据平面被 FPGA 把持;当 FPGA 组成的「数据中心加速平面」成为网络和服务器之间的天堑……似乎有种感觉,FPGA 将掌控全局,CPU 上的计算任务反而变得碎片化,受 FPGA 的驱使。以往我们是 CPU 为主,把重复的计算任务卸载(offload)到 FPGA 上;以后会不会变成 FPGA 为主,把复杂的计算任务卸载到 CPU 上呢?随着 Xeon + FPGA 的问世,古老的 SoC 会不会在数据中心焕发新生?
审核编辑 :李倩
-
FPGA
+关注
关注
1629文章
21729浏览量
602960 -
机器学习
+关注
关注
66文章
8406浏览量
132557
原文标题:FPGA, CPU, GPU, ASIC区别,FPGA为何这么牛
文章出处:【微信号:gh_9d70b445f494,微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

FPGA真的能取代CPU和GPU吗?
自动驾驶主流架构方案对比:GPU、FPGA、ASIC
相比CPU、GPU、ASIC,FPGA有什么优势
ASIC和FPGA有什么区别
ASIC、ASSP、SoC和FPGA之间到底有何区别?
FPGA为什么比CPU和GPU快
什么是ASIC芯片?与CPU、GPU、FPGA相比如何?





 工商网监
工商网监
评论