 NVIDIA A100张量核心GPU的内部和新特性研究
NVIDIA A100张量核心GPU的内部和新特性研究
在 2020 年 NVIDIA GTC 主题演讲中, NVIDIA 创始人兼 CEO 黄仁勋介绍了基于新 NVIDIA 安培 GPU 架构的新 NVIDIA A100 GPU 。这篇文章介绍了新的 A100 GPU 内部,并描述了 NVIDIA 安培架构 GPUs 的重要新特性。
现代云数据中心运行的计算密集型应用程序的多样性推动了 NVIDIA GPU – 加速云计算的爆炸式发展。这些密集型应用包括 AI 深度学习( DL )培训和推理、数据分析、科学计算、基因组学、边缘视频分析和 5G 服务、图形渲染、云游戏等。从扩大人工智能培训和科学计算,到扩展推理应用程序,再到实现实时对话人工智能, NVIDIA GPUs 提供了必要的马力,以加速当今云数据中心中运行的大量复杂和不可预测的工作负载。
NVIDIA GPUs 是推动人工智能革命的领先计算引擎,为人工智能训练和推理工作提供了巨大的加速。此外, NVIDIA GPUs 加速了许多类型的 HPC 和数据分析应用程序和系统,使您能够有效地分析、可视化并将数据转化为洞察力。 NVIDIA 加速计算平台是世界上许多最重要和发展最快的行业的核心。
介绍了 NVIDIA A100 张量核 GPU
NVIDIA A100 张量核心 GPU 基于新的 NVIDIA 安培 GPU 架构,并建立在以前的 NVIDIA Tesla V100GPU 的能力之上。它添加了许多新功能,为 HPC 、 AI 和数据分析工作负载提供了显著更快的性能。
A100 为在单台和多台 GPU 工作站、服务器、群集、云数据中心、边缘系统和超级计算机上运行的 GPU 计算和 DL 应用程序提供了强大的扩展能力。 A100 GPU 能够构建弹性、多功能和高吞吐量的数据中心。
A100 GPU 包括革命性的新 多实例 ( MIG )虚拟化和 GPU 分区功能,这对云服务提供商( csp )尤其有利。当配置为 MIG 操作时, A100 允许 CSP 提高其 GPU 服务器的利用率,在不增加额外成本的情况下,可提供最多 7 倍的 GPU 实例。强大的故障隔离使他们能够安全可靠地划分单个 A100 GPU 。
A100 增加了一个强大的新的第三代张量核心,在增加了对 DL 和 HPC 数据类型的全面支持的同时,增加了一个新的稀疏特性,使吞吐量进一步翻倍。
A100 中新的 TensorFloat-32 ( TF32 ) Tensor 核心操作为在 DL 框架和 HPC 中加速 FP32 输入/输出数据提供了一条简单的途径,比 V100 FP32 FMA 操作快 10 倍,在稀疏的情况下运行速度快 20 倍。对于 FP16 / FP32 混合精度 DL , A100 张量核心提供了 V100 的 2 。 5 倍性能,随着稀疏性增加到 5 倍。
新的 Bfloat16 ( BF16 )/ FP32 混合精度张量核心操作以与 FP16 / FP32 混合精度相同的速率运行。 INT8 、 INT4 的张量核心加速和二进制舍入支持 DL 推断, A100 稀疏 INT8 运行速度比 V100 INT8 快 20 倍。对于 HPC , A100 张量核心包括新的符合 IEEE 标准的 FP64 处理,其 FP64 性能是 V100 的 2 。 5 倍。
NVIDIA A100 GPU 的设计不仅可以加速大型复杂的工作负载,还可以有效地加速许多较小的工作负载。 A100 支持构建能够满足不可预测的工作负载需求的数据中心,同时提供细粒度的工作负载调配、更高的 GPU 利用率和改进的 TCO 。
NVIDIA A100 GPU 为 AI 训练和推理工作负载提供了超过 V100 的超常加速,如图 2 所示。类似地,图 3 显示了跨不同 HPC 应用程序的显著性能改进。
主要特点
基于 TSMC 7nm N7 制造工艺制造的 NVIDIA 安培架构的 GA100 GPU 为 A100 供电,包括 542 亿个晶体管,芯片尺寸为 826 平方毫米。
A100 GPU 多处理器流媒体
基于 NVIDIA 安培架构的 A100 张量核心 GPU 中的新型流式多处理器( SM )显著提高了性能,建立在 Volta 和 Turing SM 架构中引入的功能的基础上,并添加了许多新功能。
A100 第三代张量核心增强了操作数共享,提高了效率,并添加了强大的新数据类型,包括:
加速 FP32 数据处理的 TF32 张量核心指令
符合 IEEE 标准的 FP64 高性能计算机张量核心指令
BF16 张量核心指令的吞吐量与 FP16 相同
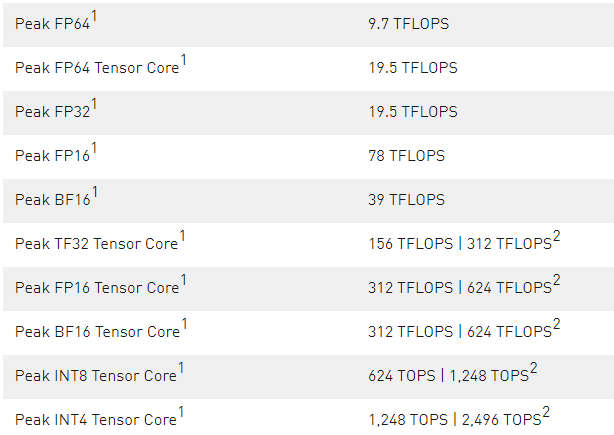
表 1 。 A100 张量芯 GPU 性能规格
1 ) 峰值速率基于 GPU 的升压时钟。
2 ) 使用新稀疏特性的有效 TFLOPS / TOPS 。
在 A100 张量核中新的稀疏性支持可以利用 DL 网络中的细粒度结构稀疏性,将张量核操作的吞吐量提高一倍。稀疏特性将在本文后面的 A100 引入细粒结构稀疏性 部分详细描述。
A100 中更大更快的一级缓存和共享内存单元提供了 1 。 5 倍于 V100 的总容量( 192 KB 对 128 KB / SM ),从而为许多 HPC 和 AI 工作负载提供额外的加速。
其他一些新的 SM 特性提高了效率和可编程性,并降低了软件复杂性。
40 GB HBM2 和 40 MB 二级缓存
为了满足其巨大的计算吞吐量, NVIDIA A100 GPU 拥有 40GB 的高速 HBM2 内存,内存带宽为 1555GB / s ,与 Tesla V100 相比增加了 73% 。此外, A100 GPU 拥有更多的片上内存,包括 40 MB 的二级缓存( L2 ),比 V100 大近 7 倍,以最大限度地提高计算性能。 A100 二级缓存采用新的分区交叉结构,提供了 V100 2 。 3 倍的二级缓存读取带宽。
为了优化容量利用率, NVIDIA 安培体系结构提供二级缓存驻留控制,以管理要保留或从缓存中移出的数据。 A100 还增加了计算数据压缩功能,使 DRAM 带宽和 L2 带宽提高了 4 倍, L2 容量提高了 2 倍。
多实例
新的多实例 GPU ( MIG )特性允许 A100 张量核心 GPU 安全地划分为多达七个独立的 GPU 实例,用于 CUDA 应用程序,为多个用户提供单独的 GPU 资源,以加速其应用程序。
在 MIG 中,每个实例的处理器在整个内存系统中都有独立的独立路径。片上交叉条端口、二级缓存库、内存控制器和 DRAM 地址总线都被唯一地分配给单个实例。这确保了单个用户的工作负载可以在具有相同的二级缓存分配和 DRAM 带宽的情况下以可预测的吞吐量和延迟运行,即使其他任务正在冲击自己的缓存或使其 DRAM 接口饱和。
MIG 提高了 GPU 的硬件利用率,同时在不同的客户机(如 vm 、容器和进程)之间提供了定义的 QoS 和隔离。 MIG 对于具有多租户用例的 csp 尤其有利。它确保了一个客户机不会影响其他客户机的工作或日程安排,此外还为客户机提供了增强的安全性和 GPU 利用率保证。
第三代 NVIDIA NVLink
在 A100 GPUs 中实现的第三代 NVIDIA 高速 NVLink 互连和新的 NVIDIA NVSwitch 显著提高了多 GPU 的可扩展性、性能和可靠性。由于每个 GPU 和交换机有更多的链路,新的 NVLink 提供了更高的 GPU -GPU 通信带宽,并改进了错误检测和恢复功能。
第三代 NVLink 每对信号的数据传输速率为 50Gbit / s ,几乎是 V100 中 25 。 78Gbits / sec 的两倍。单个 A100 NVLink 在每个方向提供 25 GB /秒的带宽,类似于 V100 ,但与 V100 相比,每个链路只使用一半的信号对。 A100 的链路总数增加到 12 个,而 V100 的总带宽为 6 个,总带宽为 600 GB /秒,而 V100 的总带宽为 300 GB /秒。
支持 NVIDIA Magnum IO 和 Mellanox 互连解决方案
A100 Tensor Core GPU 与 NVIDIA Magnum IO 和 Mellanox 最先进的 InfiniBand 和以太网互连解决方案完全兼容,以加快多节点连接。
Magnum IO API 集成了计算、网络、文件系统和存储,以最大限度地提高多节点加速系统的 I / O 性能。它与 CUDA -X 库接口,以加速从人工智能、数据分析到可视化等各种工作负载的 I / O 。
带 SR-IOV 的 PCIe Gen 4
A100 GPU 支持 PCI Express Gen 4 ( PCIe Gen 4 ),通过为 x16 连接提供 31 。 5 GB /秒而不是 15 。 75 GB /秒,将 PCIe 3 。 0 / 3 。 1 的带宽提高了一倍。更快的速度尤其有利于 A100 GPUs 连接到支持 PCIe 4 。 0 的 CPU 并支持快速网络接口,如 200 Gbit / s InfiniBand 。
A100 还支持单根输入/输出虚拟化( SR-IOV ),允许为多个进程或虚拟机共享和虚拟化单个 PCIe 连接。
改进了错误和故障检测、隔离和控制
通过检测、包含并经常纠正错误和错误,而不是强制 GPU 重置来最大限度地提高 GPU 的正常运行时间和可用性是至关重要的。在大型多 GPU 集群和单 GPU 多租户环境(如 MIG 配置)中尤其如此。 A100 张量核心 GPU 包括新技术,用于改进错误/故障属性、隔离和控制,如本文后面深入的架构部分所述。
异步复制
A100 GPU 包含了一个新的异步复制指令,该指令将数据直接从全局内存加载到 SM 共享内存中,从而消除了使用中间寄存器文件( RF )的需要。异步复制减少了寄存器文件带宽,更有效地使用内存带宽,并减少了功耗。顾名思义,异步复制可以在 SM 执行其他计算时在后台完成。
异步屏障
A100 GPU 在共享内存中提供了硬件加速屏障。这些屏障可用 CUDA 11 ,形式如下ISO C ++符合障碍物。异步屏障将屏障到达和等待操作分开可用于将全局内存中的异步副本与 SM 中的计算重叠到共享内存中。它们可用于使用 CUDA 线程实现生产者 – 消费者模型。屏障还提供机制来同步不同粒度的 CUDA 线程,而不仅仅是扭曲或块级别。
任务图加速
CUDA 任务图为向 GPU 提交工作提供了一个更有效的模型。任务图由一系列操作组成,如内存复制和内核启动,这些操作通过依赖关系连接起来。任务图支持定义一次并重复运行的执行流。预定义的任务图允许在单个操作中启动任意数量的内核,极大地提高了应用程序的效率和性能。 A100 添加了新的硬件功能,使任务图中网格之间的路径明显更快。
A100 GPU 硬件架构
NVIDIA GA100 GPU 由多个 GPU 处理簇( GPC )、纹理处理簇( TPC )、流式多处理器( SMs )和 HBM2 内存控制器组成。
GA100 GPU 的全面实施包括以下单元:
8 个 GPC , 8 个 TPC / GPC , 2 个 SMs / TPC , 16 个 SMs / GPC ,每满 128 个 SMsGPU
64 个 FP32 CUDA 核/ SM ,每满 GPU 个 8192 个 FP32 CUDA 个核
4 个第三代张量核心/ SM ,每满 512 个第三代张量核心 GPU
6 个 HBM2 堆栈, 12 个 512 位内存控制器
GA100 GPU 的 A100 张量核 GPU 实现 包括以下单元:
7 个 GPC , 7 或 8 个 TPC / GPC , 2 个 SMs / TPC ,最多 16 个 SMs / GPC , 108 个 SMs
64 个 FP32 CUDA 芯/ SM ,每个 GPU 个 6912 个 FP32 CUDA 个芯
4 个第三代张量核心/ SM ,每个 GPU 432 个第三代张量核心
5 个 HBM2 堆栈, 10 个 512 位内存控制器
A100 SM 建筑
新的 A100 SM 显著提高了性能,建立在 Volta 和 Turing SM 架构中引入的特性之上,并添加了许多新功能和增强功能。
A100 SM 图如图 5 所示。 Volta 和 Turing 每个 SM 有 8 个张量核心,每个张量核心每个时钟执行 64 个 FP16 / FP32 混合精度融合乘法加法( FMA )操作。 A100 SM 包括新的第三代张量核心,每个时钟执行 256 个 FP16 / FP32 FMA 操作。 A100 每平方米有四个张量核心,总共每时钟提供 1024 个密集的 FP16 / FP32 FMA 操作,与 Volta 和 Turing 相比,每平方米的计算马力增加了 2 倍。
这里将简要介绍 SM 的主要功能,并在本文后面详细介绍:
第三代张量核心:
所有数据类型的加速,包括 FP16 、 BF16 、 TF32 、 FP64 、 INT8 、 INT4 和 Binary 。
新的张量核心稀疏特性利用了深度学习网络中的细粒度结构稀疏性,使标准张量核心操作的性能提高了一倍。
A100 中的 TF32 Tensor 核心操作为 DL 框架和 HPC 中的 FP32 输入/输出数据提供了一条简单的途径,比 V100 FP32 FMA 操作快 10 倍,在 sparity 中运行速度快 20 倍。
FP16 / FP32 混合精密张量核心操作为 DL 提供了前所未有的处理能力,比 V100 张量核心操作运行速度快 2 。 5 倍,且稀疏性增加到 5x 。
BF16 / FP32 混合精度张量核心运算的运行速度与 FP16 / FP32 混合精度相同。
FP64 张量核心操作为 HPC 提供了前所未有的双精度处理能力,运行速度比 V100 FP64 DFMA 操作快 2 。 5 倍。
具有稀疏性的 INT8 张量核心操作为 DL 推理提供了前所未有的处理能力,运行速度比 V100 INT8 操作快 20 倍。
192 KB 的共享内存和一级数据缓存,比 V100 SM 大 1 。 5 倍。
新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过一级缓存,并且不需要使用中间寄存器文件( RF )。
基于共享内存的新型屏障单元(异步的barriers )用于新的异步复制指令。
L2 缓存管理和驻留控制的新说明。
CUDA 合作组支持的新的扭曲级缩减指令。
许多可编程性改进以降低软件复杂性。
图 6 比较了 V100 和 A100 FP16 张量核心操作,还比较了 V100 FP32 、 FP64 和 INT8 标准操作与各自的 A100 TF32 、 FP64 和 INT8 张量核心操作。吞吐量是根据 GPU 聚合的,其中 A100 对 FP16 、 TF32 和 INT8 使用稀疏张量核心操作。左上角的图表显示了两个 V100 FP16 张量核心,因为 V100 SM 每个 SM 分区有两个张量核心,而 A100 SM 则有两个张量核心。
图 6 。 A100 张量核心操作与 V100 张量核心操作以及不同数据类型的标准操作进行比较。
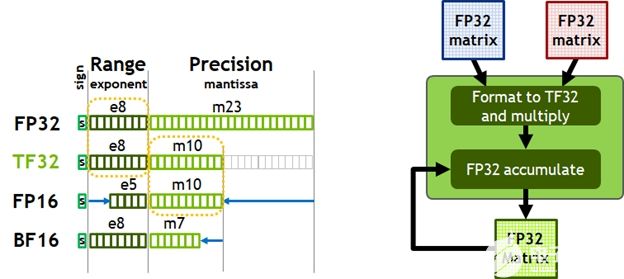
图 7 。 TensorFloat-32 ( TF32 )提供 FP32 的范围,精度为 FP16 (左)。支持 tfa032 格式的自动输入和输出。
今天,人工智能训练的默认数学是 FP32 ,没有张量核心加速度。 NVIDIA Ampere 架构引入了对 TF32 的新支持,使 AI 训练能够在默认情况下使用张量核心,而不需要用户的努力。非张量运算继续使用 FP32 数据路径,而 TF32 张量核心读取 FP32 数据并使用与 FP32 相同的范围,内部精度降低,然后生成标准 IEEE FP32 输出。 TF32 包括一个 8 位指数(与 FP32 相同)、 10 位尾数(精度与 FP16 相同)和 1 个符号位。
与 Volta 一样,自动混合精度( AMP )允许您使用混合精度与 FP16 进行 AI 训练,只需几行代码更改。使用 AMP , A100 的张量核心性能比 TF32 快 2 倍。
综上所述,用于 DL 培训的 NVIDIA 安培架构数学的用户选择如下:
默认情况下,使用 TF32 张量核心,不需要调整用户脚本。与 A100 上的 FP32 相比,吞吐量提高了 8 倍,与 V100 上的 FP32 相比,吞吐量提高了 10 倍。
应采用 FP16 或 BF16 混合精度训练,以获得最大训练速度。与 TF32 相比,吞吐量提高了 2 倍,与 A100 上的 FP32 相比提高了 16 倍,与 V100 上的 FP32 相比提高了 20 倍。
A100 张量核加速高性能混凝土
高性能计算机应用的性能需求正在迅速增长。许多科学和研究学科的应用都依赖于双精度( FP64 )计算。
为了满足 HPC 计算快速增长的计算需求, A100 GPU 支持张量运算,加速符合 IEEE 标准的 FP64 计算,其 FP64 性能是 NVIDIA Tesla V100GPU 的 2 。 5 倍。
A100 上新的双精度矩阵乘法加法指令取代了 V100 上的 8 条 DFMA 指令,减少了指令获取、调度开销、寄存器读取、数据路径功耗和共享内存读取带宽。
A100 中的每个 SM 计算 64 个 FP64 FMA 操作/时钟(或 128 个 FP64 操作/时钟),这是 Tesla V100 吞吐量的两倍。 A100 Tensor Core GPU 具有 108 条短信息,可提供 19 。 5 TFLOPS 的峰值 FP64 吞吐量,是 Tesla V100 的 2 。 5 倍。
随着对这些新格式的支持, A100 张量核心可以用于加速 HPC 工作负载、迭代求解器和各种新的 AI 算法。
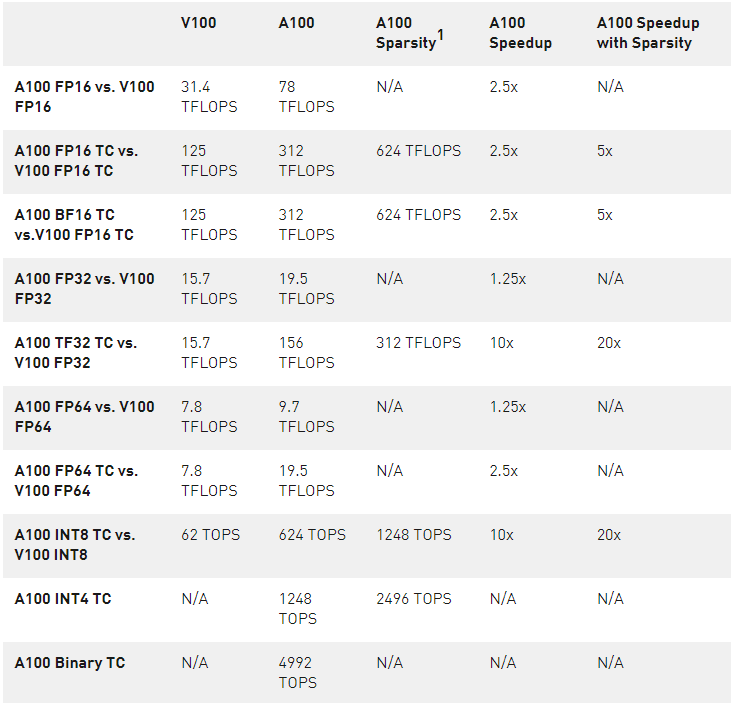
表 2 。 A100 加速超过 V100 ( TC =张量核心, GPUs 在各自的时钟速度)。
1 ) 使用新稀疏性特征的有效 TOPS / TFLOPS
A100 引入细粒结构稀疏性
在 A100 GPU 中, NVIDIA 引入了细粒度结构稀疏性,这是一种新的方法,可以使深层神经网络的计算吞吐量翻倍。
在深度学习中,稀疏性是可能的,因为个体权重的重要性在学习过程中不断演化,到网络训练结束时,只有一部分权值在确定学习输出时有意义。剩下的重量不再需要了。
细粒度的结构化稀疏性对允许的稀疏模式施加了一个约束,使硬件能够更有效地对输入操作数进行必要的对齐。由于深度学习网络能够在基于训练反馈的训练过程中自适应权值, NVIDIA 工程师发现,一般来说,结构约束不会影响训练网络的推理精度。这使得可以推断稀疏加速度。
对于训练加速,需要在训练过程的早期引入稀疏性以提供性能上的好处,而在不损失精度的情况下加速训练是一个活跃的研究领域。
稀疏矩阵定义
结构是通过一个新的 2 : 4 稀疏矩阵定义来实现的,该定义允许每四个输入向量中有两个非零值。 A100 支持行上的 2 : 4 结构化稀疏性,如图 9 所示。
由于矩阵的明确结构,它可以被有效地压缩,并减少近 2 倍的内存存储和带宽。
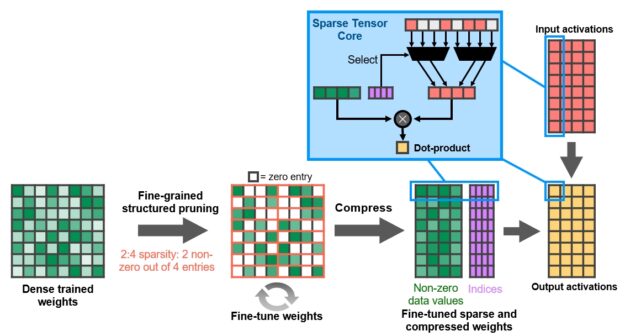
图 9 。 A100 细粒度结构化稀疏度使用 4 取 2 的非零模式对训练的权重进行修剪,然后使用一个简单而通用的方法对非零权重进行微调。权重被压缩,数据占用空间和带宽减少了 2 倍, A100 稀疏张量核心通过跳过零将数学吞吐量翻倍。
NVIDIA 已经开发出一种简单而通用的方法来分离深层神经网络进行推理使用这种 2 : 4 结构稀疏模式。 首先使用密集权值训练网络,然后应用细粒度结构剪枝,最后通过附加的训练步骤对剩余的非零权值进行微调。这种方法在基于视觉、目标检测、分割、自然语言建模和翻译等数十个网络的评估的基础上,几乎没有损失推理精度。
A100 Tensor Core GPU 包含新的稀疏张量核心指令,这些指令跳过对零值的条目的计算,从而使张量核心计算吞吐量翻倍。图 9 显示了张量核心如何使用压缩元数据(非零索引)将压缩后的权重与适当选择的用于输入到张量核心点积计算的激活匹配。
组合一级数据缓存和共享内存
NVIDIA Tesla V100 首次引入, NVIDIA 结合了一级数据缓存和共享内存子系统架构,显著提高了性能,同时还简化了编程,减少了达到或接近峰值应用程序性能所需的调整。将数据缓存和共享内存功能组合到单个内存块中,可以为两种类型的内存访问提供最佳的总体性能。
一级数据缓存和共享内存的组合容量在 A100 中为 192 KB / SM ,而在 V100 中为 128 KB / SM 。
同时执行 FP32 和 INT32 操作
与 V100 和图灵 GPUs 类似, A100 SM 还包括独立的 FP32 和 INT32 核,允许在全吞吐量的情况下同时执行 FP32 和 INT32 操作,同时也增加指令发出吞吐量。
许多应用程序都有内部循环,执行指针算术(整数内存地址计算)与浮点计算相结合,这有利于 FP32 和 INT32 指令的同时执行。下一次迭代( intfp32 )可以同时更新当前循环中的每一个循环的指针。
A100 HBM2 DRAM 子系统
随着 HPC 、 AI 和 analytics 数据集的不断增长,以及寻找解决方案的问题变得越来越复杂,需要更多的 GPU 内存容量和更高的内存带宽。
Tesla P100 是世界上第一个支持高带宽 HBM2 内存技术的 GPU 体系结构,而 Tesla V100 提供了更快、更高效、更高容量的 HBM2 实现。 A100 再次提高了 HBM2 性能和容量的标准。
HBM2 内存由位于与 GPU 相同的物理包上的内存堆栈组成,与传统的 GDDR5 / 6 内存设计相比,提供了大量的功耗和面积节省,允许在系统中安装更多的 GPUs 。有关 HBM2 技术基本细节的更多信息,请参阅 NVIDIA Tesla P100 :有史以来最先进的数据中心加速器 白皮书。
A100 GPU 在其 SXM4 风格的电路板上包括 40 GB 的快速 HBM2 DRAM 内存。内存被组织成五个活动的 HBM2 堆栈,每个堆栈有八个内存片。 A100 HBM2 的数据速率为 1215 MHz ( DDR ),可提供 1555 GB /秒的内存带宽,比 V100 内存带宽高出 1 。 7 倍多。
ECC 内存弹性
A100 HBM2 存储子系统支持单纠错双错误检测( SECDED )纠错码( ECC )来保护数据。 ECC 为对数据损坏敏感的计算应用程序提供了更高的可靠性。在大型集群计算环境中,这一点尤为重要, GPUs 处理大型数据集或长时间运行应用程序。 A100 中的其他密钥存储结构也受 SECDED ECC 的保护,包括二级缓存和一级缓存以及所有 SMs 中的寄存器文件。
A100 二级缓存
A100 GPU 包含 40 MB 二级缓存,比 V100 L2 大 6 。 7 倍缓存。那个二级缓存分为两个分区,以实现更高的带宽和更低的延迟内存访问。每个二级分区在直接连接到分区的 gpc 中为 SMs 访问内存而本地化和缓存数据。这种结构使 A100 比 V100 的 L2 带宽增加了 2 。 3 倍。硬件缓存一致性在整个 GPU 中维护 CUDA 编程模型,应用程序自动利用新的二级缓存的带宽和延迟优势。
二级缓存是 gpc 和 SMs 的共享资源,位于 gpc 之外。 A100 L2 缓存大小的大幅增加显著提高了许多 HPC 和 AI 工作负载的性能,因为现在可以以比读取和写入 HBM2 内存更高的速度缓存和重复访问更多的数据集和模型。一些受 DRAM 带宽限制的工作负载将受益于更大的二级缓存,例如使用小批量的深度神经网络。
为了优化容量利用率, NVIDIA 安培体系结构提供二级缓存驻留控制,以管理要保留或从缓存中移出的数据。您可以留出一部分二级缓存用于持久数据访问。
例如,对于 DL 推断工作负载,可以在 L2 中持久地缓存 ping-pong 缓冲区,以加快数据访问速度,同时避免对 DRAM 的写回。对于生产者 – 消费者链,如在 DL 培训中发现的那些,二级缓存控件可以跨读写数据依赖关系优化缓存。在 LSTM 网络中,递归权值可以优先缓存并在 L2 中重用。
NVIDIA Ampere 架构增加了计算数据压缩,以加速非结构化稀疏性和其他可压缩数据模式。二级压缩使 DRAM 读/写带宽提高了 4 倍,二级读取带宽提高了 4 倍,二级容量提高了 2 倍。
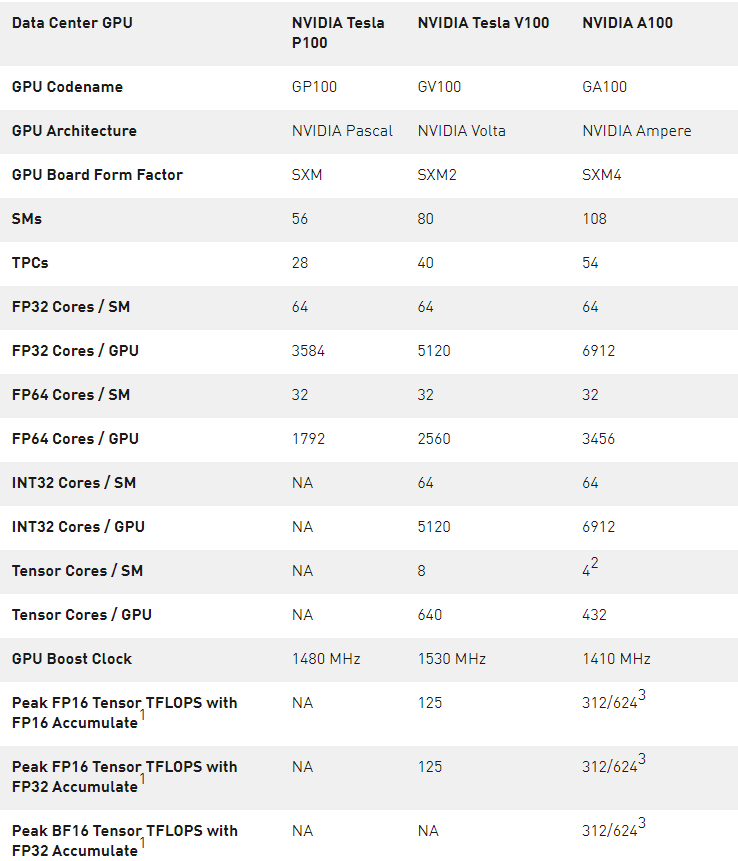
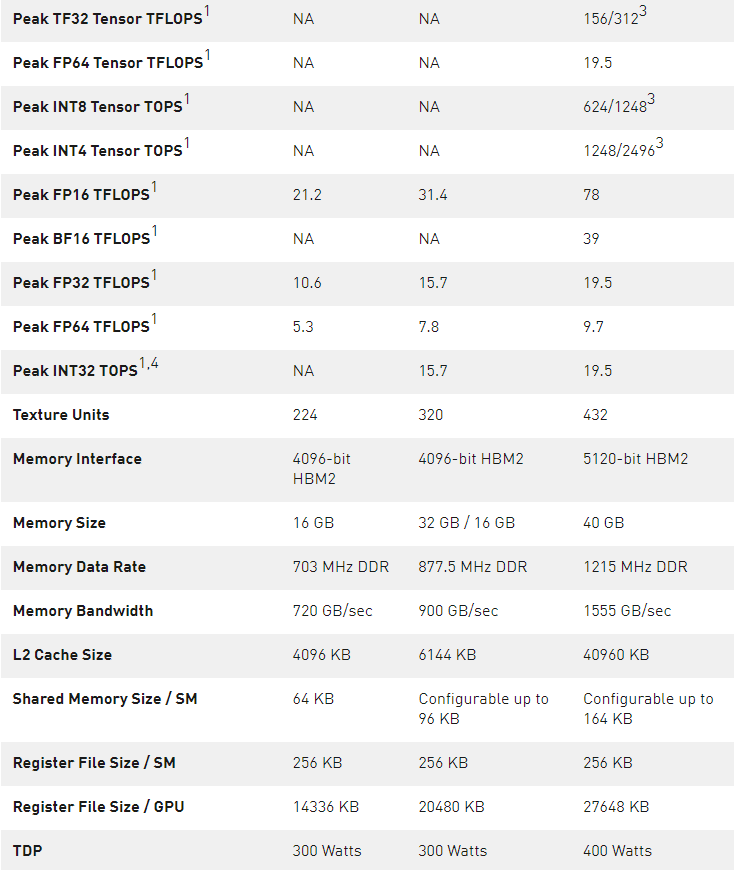
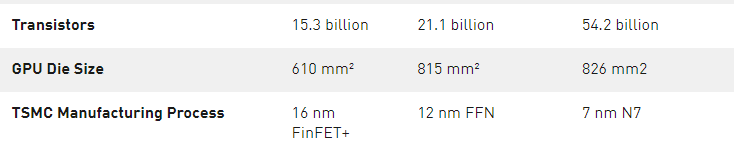
表 3 。 NVIDIA 数据中心 GPUs 比较。
1 ) 峰值速率基于 GPU 的升压时钟。
2 ) A100 SM 中的四个张量核心的原始 FMA 计算能力是 GV100 SM 中八个张量核心的 2 倍。
3 ) 使用新的稀疏特性的有效顶部/ TFLOPS 。
4 ) TOPS =基于 IMAD 的整数数学
注: 因为 A100 张量核心 GPU 设计安装在高性能服务器和数据中心机架上,为 AI 和 HPC 计算工作负载供电,因此它不包括用于光线跟踪加速的显示连接器、 NVIDIA RT 核心或 NVENC 编码器。
计算能力
支持新的计算能力 GPU 。表 4 比较了 NVIDIA GPU 体系结构的不同计算能力的参数。
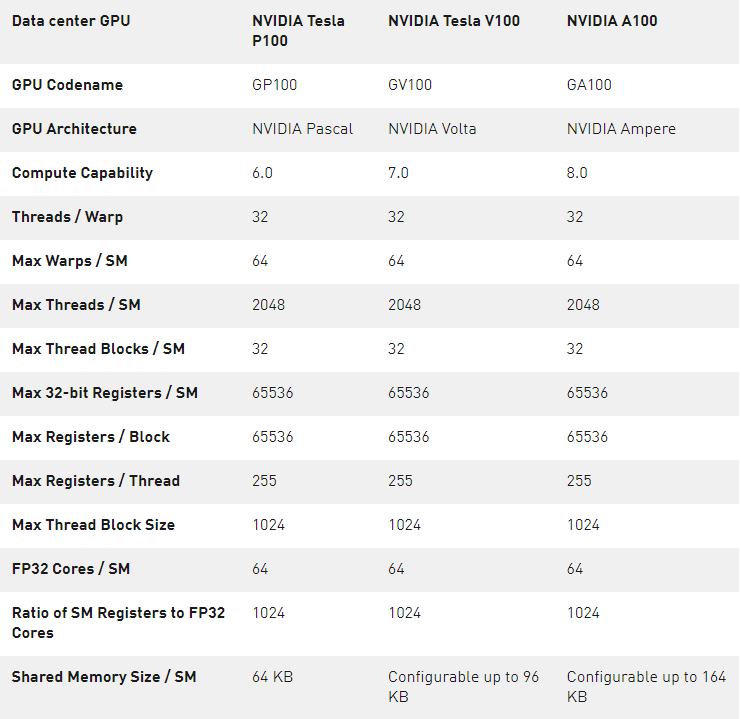
表 4 。计算能力: GP100 vs 。 GV100 vs 。 GA100 。
MIG 体系结构
尽管许多数据中心的工作负载在规模和复杂性上都在不断扩展,但有些加速任务的要求并不高,例如早期开发或在低批量规模下对简单模型进行推理。数据中心管理者的目标是保持高资源利用率,因此理想的数据中心加速器不只是变大,它还可以有效地加速许多较小的工作负载。
新的 MIG 特性可以将每个 A100 划分为多达 7 个 GPU 实例以实现最佳利用率,有效地扩展了对每个用户和应用程序的访问。
图 10 显示了 Volta MPS 如何允许多个应用程序同时在不同的 GPU 执行资源( SMs )上执行。但是,由于内存系统资源是在所有应用程序之间共享的,因此,如果一个应用程序对 DRAM 带宽有很高的要求或其请求在二级缓存中超额订阅,则可能会干扰其他应用程序。
图 11 中显示的 A100 [……]诉讼。 新 MIG 功能可以将单个 GPU 划分为多个名为 GPU 的 GPU 分区每个实例的 SMs 在整个内存系统中都有独立的独立路径——片上交叉条端口、二级缓存库、内存控制器和 DRAM 地址总线都是唯一分配给单个实例的。这确保了单个用户的工作负载可以在具有相同的二级缓存分配和 DRAM 带宽的情况下以可预测的吞吐量和延迟运行,即使其他任务正在冲击自己的缓存或使其 DRAM 接口饱和。
利用这种能力,MIG 可以对可用的 GPU 计算资源进行分区,以提供定义的服务质量(QoS ),为不同的客户机(如 VM 、容器、进程等)提供故障隔离。它允许多个 GPU 实例在单个物理 A100 GPU 上并行运行。 MIG 还保持 CUDA 编程模型不变,以最小化编程工作量。
CSP 可以使用 MIG 来提高其 GPU 服务器的利用率,在不增加成本的情况下提供最多 7 倍的 GPU 实例。 MIG 支持 csp 所需的必要的 QoS 和隔离保证,以确保一个客户端( VM 、容器、进程)不会影响来自另一个客户端的工作或调度。
CSP 通常根据客户使用模式对其硬件进行分区。只有当硬件资源在运行时提供一致的带宽、适当的隔离和良好的性能时,有效的分区才有效。
使用基于 NVIDIA Ampere 架构的 GPU ,您可以看到和调度新的虚拟 GPU 实例上的作业,就像它们是物理的 GPUs 。 MIG 与 Linux 操作系统及其管理程序一起工作。用户可以使用诸如 Docker Engine 之类的运行时来运行带有 MIG 的容器,并且很快就会支持使用 Kubernetes 的容器编排。
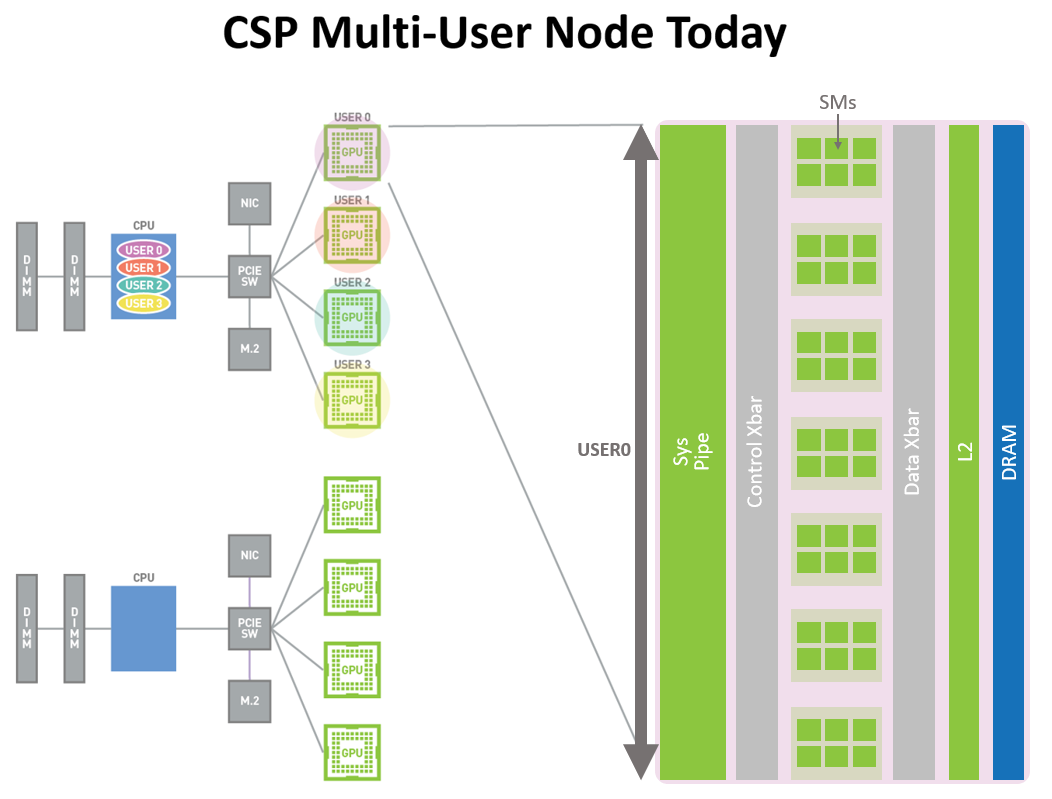
图 10 。今天的 CSP 多用户节点( A100 之前)。加速的 GPU 实例只能在完全物理 GPU 粒度下用于不同组织的用户,即使用户应用程序不需要完整的 GPU 。
错误和故障检测、隔离和控制
通过检测、包含并经常纠正错误和错误,而不是强制 GPU 重置来提高 GPU 的正常运行时间和可用性是至关重要的。这在大型多 GPU 集群和单 GPU 多租户环境(如 MIG 配置)中尤其重要。
NVIDIA 安培架构 A100 GPU 包括改进错误/故障属性的新技术(将导致错误的应用程序归为属性)、隔离(隔离故障应用程序,使其不会影响运行在同一 GPU 或 GPU 集群中的其他应用程序),和控制(确保一个应用程序中的错误不会泄漏并影响其他应用程序)。这些故障处理技术对于 MIG 环境尤其重要,以确保共享单个 GPU 的客户端之间的适当隔离和安全性。
NVLink connected GPUs 现在具有更强大的错误检测和恢复功能。远程 GPU 的页面错误通过 NVLink 发送回源 GPU 。远程访问故障通信对于大型 GPU 计算集群来说是一个关键的弹性特性,可以帮助确保一个进程或虚拟机中的故障不会导致其他进程或虚拟机停机。
A100 GPU 还包括其他几个新的和改进的硬件功能,可以提高应用程序的性能。有关更多信息,请参阅即将发布的 NVIDIA A100 张量核 GPU 体系结构 白皮书。
CUDA 11NVIDIA 安培结构 GPUs 的进步
数以千计的 GPU 加速应用程序构建在 NVIDIA CUDA 并行计算平台上。 CUDA 的灵活性和可编程性使其成为研究和部署新的 DL 和并行计算算法的首选平台。
NVIDIA 安培架构 GPUs 旨在提高 GPU 的可编程性和性能,同时降低软件复杂性。 NVIDIA 安培架构 GPUs 和 CUDA 编程模型的进步加快了程序执行,并降低了许多操作的延迟和开销。
新的 CUDA 11 特性为第三代张量核心、稀疏性、 CUDA 图、多实例 GPUs 、二级缓存驻留控制以及 NVIDIA 安培架构的其他一些新功能提供编程和 API 支持。
有关 CUDA 新特性的更多信息,请参阅即将发布的 NVIDIA A100 张量核 GPU 体系结构 白皮书。有关新 DGX A100 系统的详细信息,请参见 用 NVIDIA DGX A100 定义人工智能创新 。有关开发人员专区的更多信息,请参阅 NVIDIA 开发者 ,有关 CUDA 的更多信息,请参阅新的 CUDA 编程指南 。
结论
NVIDIA 的任务是加速我们这个时代的达芬奇和爱因斯坦的工作。科学家、研究人员和工程师致力于利用高性能计算( HPC )和人工智能解决世界上最重要的科学、工业和大数据挑战。
NVIDIA A100 Tensor Core GPU 在我们的加速数据中心平台上实现了下一个巨大的飞跃,在各个规模上都提供了无与伦比的加速度,使这些创新者能够在有生之年完成一生的工作。 A100 支持许多应用领域,包括 HPC 、基因组学、 5G 、渲染、深度学习、数据分析、数据科学和机器人技术。
今天,推进最重要的 HPC 和 AI 应用程序个性化医疗、会话式人工智能和深度推荐系统需要研究人员大刀阔斧。 A100 为 NVIDIA 数据中心平台提供动力,该平台包括 MellanoxHDR InfiniBand 、 NVSwitch 、 NVIDIA HGX A100 和用于扩展的 Magnum IO SDK 。这个集成的技术团队有效地扩展到数万个 GPUs ,以前所未有的速度训练最复杂的人工智能网络。
A100 GPU 的新 MIG 功能可以将每个 A100 划分为多达七个 GPU 加速器以实现最佳利用率,有效提高了 GPU 资源利用率和 GPU 访问更多用户和 GPU 加速应用程序。凭借 A100 的多功能性,基础设施经理可以最大限度地利用其数据中心中的每个 GPU ,以满足不同规模的性能需求,从最小的作业到最大的多节点工作负载。
关于作者
Ronny Krashinsky 设计 NVIDIA GPU 已有 10 年。他开始了他的 NVIDIA 研究生涯,后来加入了流式多处理器团队,设计了 voltasm 。罗尼是 100 个深度学习特性的首席架构师,他现在管理着 NVIDIA 的深度学习架构路线图。
Olivier Giroux 已经完成了十个 GPU 和六个由 NVIDIA 发布的 SM 体系结构。他是一位杰出的建筑师,专注于 GPU 程序语义,并主持 ISOC C ++子群的并发和并行。
Stephen Jones 是 CUDA 的架构师之一,他致力于定义语言、平台和运行它的硬件,以满足从高性能计算到人工智能的并行编程需求。在任职之前,他领导着 SpaceX 公司的vwin 与分析小组,致力于火箭发动机的大规模模拟。他曾在其他不同的行业工作过,包括网络、 CAD / CAM 和科学计算。自 2008 年以来,他一直是 CUDA 的一员。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4978浏览量
102982 -
gpu
+关注
关注
28文章
4729浏览量
128887 -
人工智能
+关注
关注
1791文章
47183浏览量
238209
发布评论请先 登录
相关推荐
英伟达a100和h100哪个强?英伟达A100和H100的区别
强核问世:NVIDIA发布全球最强GPU——A100 80GB GPU
NVIDIA A100,中国顶级云服务提供商和系统制造商的上佳之选
NVIDIA发布了首款基于NVIDIA Ampere架构的GPU ——NVIDIA A100 GPU
英伟达最新的NVIDIA DGX A100被命名为通用的AI集成架构系统
英伟达 A100 GPU 全面上市,推理性能比 CPU 快 237 倍
NVIDIA推出A100 80GB GPU,助力实现新一轮AI和科学技术突破
NVIDIA推出了基于A100的DGX A100
NVIDIA发布A100 80GB加速卡
Microsoft Azure推出VIDIA A100 GPU VM系列
英伟达a100和h100哪个强?
英伟达A100和A40的对比
英伟达A100的简介
英伟达h800和a100的区别





 工商网监
工商网监
评论