 用CUDA 11 . 2 C ++编译器加速应用程序性能
用CUDA 11 . 2 C ++编译器加速应用程序性能
11 . 2 CUDA C ++编译器结合了旨在提高开发者生产力和 GPU 加速应用性能的特性和增强。
编译器工具链将 LLVM 升级到 7 . 0 ,这将启用新功能并有助于改进 NVIDIA GPU 的编译器代码生成。设备代码的链接时间优化( LTO )(也称为设备 LTO )在 CUDA 11 . 0 工具包版本中作为预览功能引入,现在作为全功能优化功能提供。 11 . 2 CUDA C ++编译器可以可选地生成一个函数,用于为设备的功能内联诊断报告,它可以提供编译器的内联决策的洞察力。这些诊断报告可以帮助高级 CUDA 开发人员进行应用程序性能分析和调优工作。
CUDA C ++编译器默认地将设备函数内嵌到调用站点。这使得优化设备代码的汇编级调试成为一项困难的任务。对于使用 11 . 2 CUDA C ++编译器工具链编译的源代码,[EZX223]和 NVIEW 计算调试器可以在调用堆栈回溯中显示内联设备功能的名称,从而改进调试体验。
这些和其他新特性被纳入 CUDA C ++ 11 . 2 编译器,我们将在这个帖子中进行深入的跳水。继续读!
使用设备 LTO 加速应用程序性能
CUDA 11 . 2 的特点是 设备 LTO ,它为以单独编译模式编译的设备代码带来了 LTO 的性能优势。在 CUDA 5 . 0 中, NVIDIA 引入了独立编译模式,以提高开发人员设计和构建 GPU 加速应用程序的效率。没有单独的编译模式,编译器只支持整个程序编译模式, CUDA 应用程序中的所有设备代码必须限制在单个翻译单元中。单独的编译模式使您可以自由地跨多个文件构造设备代码,包括 GPU 加速的库和利用增量构建。单独的编译模式允许您关注源代码模块化。
但是,单独的编译模式限制在编译时可以执行的性能优化范围内。诸如跨单个翻译单元边界的设备函数内联之类的优化不能在单独的编译模式下执行。与整个程序编译模式相比,这会导致在单独编译模式下生成次优代码,尤其是在针对设备代码库进行链接时。使用设备 LTO ,在单独编译模式下编译的应用程序的性能与整个编译模式相当。
LTO 是 CPU 编译器工具链中一个强大的优化功能,我们现在正在使 GPU 加速代码可以访问它。对于单独编译的设备代码, Device LTO 支持仅在 NVCC 整个程序编译模式下才可能进行的设备代码优化。使用设备 LTO ,您可以利用源代码模块化的好处,而不必牺牲整个程序编译的运行时性能好处。
优化设备代码的增强调试
我们做了一些增强,以便在某些情况下更容易调试优化的设备代码。
精确调试
使用 CUDA 11 . 2 ,大多数内联函数都可以在cuda-gdb和 Nsight 调试器的调用堆栈回溯中看到。您拥有性能优化代码路径的一致回溯,更重要的是,您可以更精确地确定错误或异常的调用路径,即使所有函数都是内联的。
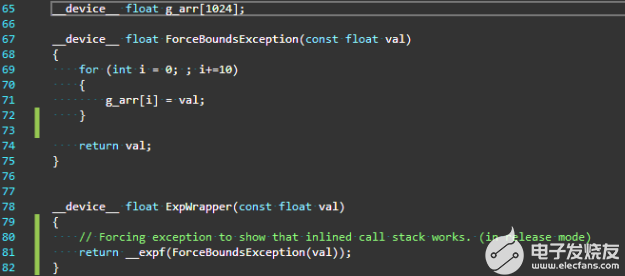
图 1 显示了一个场景示例,在调试异常时,此功能可以节省大量时间。
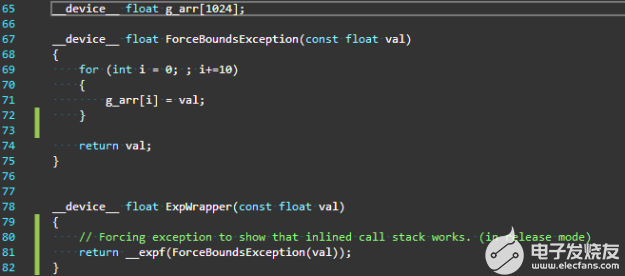
图 1 。在第 71 行强制数组越界异常的示例代码
在图 1 中,函数ExpWrapper调用ForceBoundsException,该函数注入一个数组越界异常。因为函数ForceBoundsException与函数ExpWrapper定义在同一个文件中,所以它只是简单地内联在那里。如果没有对 CUDA 11 . 2 中添加的内联函数的回溯支持,调用堆栈将只显示未内联在此调用路径中的顶级调用方。在本例中,它恰好是函数ExpWrapper的调用者,因此异常点处的调用堆栈如图 2 所示,排除了所有其他内联函数调用。

图 2 。 CUDA 11 . 2 之前没有内联函数的调用堆栈报告行号,没有完全回溯。
从图 2 中的调用堆栈可以明显看出,调用堆栈中的信息非常少,无法有意义地调试最终导致异常点的执行路径。如果不知道函数是如何内联的,调用堆栈中提供的行号 71 也没有用处。在一个三层的深层函数调用中,这个问题看起来很容易找到。随着堆栈越来越深,这个问题可能会迅速升级。我们知道,这可能是相当令人沮丧的。
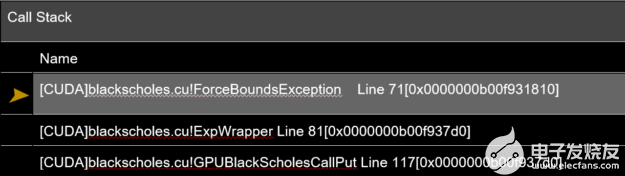
图 3 。在 CUDA 11 . 2 中,一种带有内联函数的调用堆栈。
在 CUDA 11 . 2 中, NVIDIA 通过为内联函数添加有意义的调试信息,朝着优化代码的符号调试迈出了一步。现在生成的调用堆栈既精确又有用,包括在每个级别调用的所有函数,包括那些内联的函数。这使您不仅可以确定发生异常的确切函数,还可以消除触发异常的确切调用路径的歧义。
它变得更好了!
更多的调试信息,即使是最优化的代码
对内联函数调试的改进不仅是在调用堆栈回溯上查看内联函数,而且还扩展到源代码查看。在 CUDA 11 . 2 之前,当函数调用被积极内联时,反汇编代码的源代码视图是神秘而紧凑的(图 4 )。
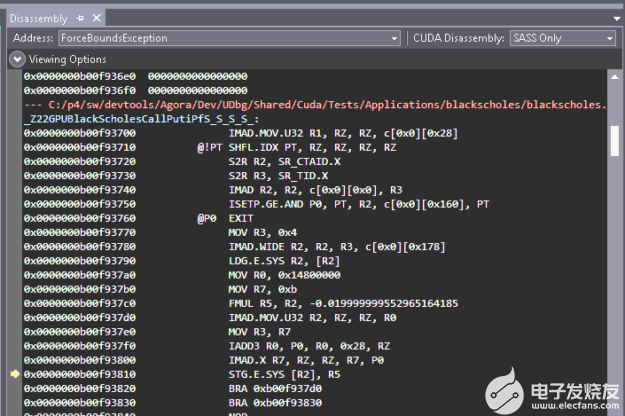
图 4 。 CUDA 11 . 2 之前的源代码反汇编视图
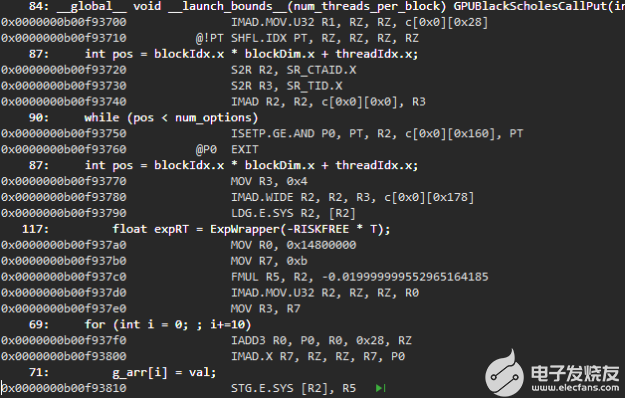
图 5 。 CUDA 11 . 2 上启用源代码的反汇编代码视图。
有更多的调试信息,包括行信息和源代码行被标记到反汇编代码段。
图 5 显示了 CUDA 11 . 2 上相同反汇编代码段的源代码视图。您可以为优化的代码段获得更详细的源代码视图,并且可以单步执行它们。行信息和源代码行被标记到反汇编源代码视图中,即使对于内联代码段也是如此。
要启用此功能,将--generate-line-info(或-lineinfo)选项传递给编译器就足够了。对优化的设备代码进行全面的符号调试还不可用。在某些情况下,您可能仍然需要使用-G选项进行调试。然而,仅仅拥有一个精确的调用堆栈和一个详细的源代码查看就可以决定性地提高调试性能优化代码的效率,从而提高开发人员的工作效率。
但还不止这些!
对诊断报告内联的见解
传统上,当编译器做出应用程序开发人员看不到的基于启发式的优化决策时,编译器有点像黑匣子。
其中一个关键的优化就是函数内联。如果没有对汇编输出进行繁重的后处理,就很难理解内联的编译器启发式方法。只要知道哪些函数是内联的,哪些不是内联的,就可以节省很多时间,这就是我们在 CUDA 11 . 2 中介绍的。现在您不仅知道函数何时没有内联,而且还知道为什么函数不能内联。然后可以重构代码,向函数 de Clara 选项添加内联关键字,或者执行其他源代码重构(如果可能的话)。
您可以通过一个新选项--optimization-info=inline获得关于优化器内联决策的诊断报告。启用内联诊断时,当函数无法内联时,优化器会报告其他诊断。
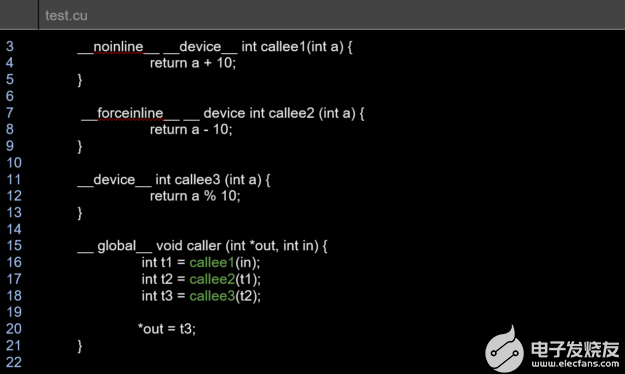
图 6 。样品测试. cu 用于以下内联诊断生成的文件。
remark: test.cu:16:12: _Z7callee2i inlined into _Z6callerPii with cost=always
remark: test.cu:17:11: _Z7callee3i inlined into _Z6callerPii with cost=always
remark: test.cu:18:12: _Z7callee1i not inlined into _Z6callerPii because it should never be inlined (cost=never)
在某些情况下,您可能会得到更详细的诊断:
remark: x.cu:312:28: callee not inlined into caller because callee doesn't have forceinline attribute and is too big for auto inlining (CalleeSize=666)
有关内联的诊断报告对于重构代码以适当地使用内联函数的性能优势非常有用。内联诊断在编译器运行内联过程时发出。当从编译器多次调用内联程序时,前一个过程中未内联的调用站点可能会内联到后一个过程中通过。那个 CUDA C ++编译器文档解释了如何在 NVCC 调用期间使用此选项。
通过并行编译减少构建时间
可以使用 -gencode/-arch/-code 命令行选项同时调用 CUDA C ++编译器,以编译多个 GPU 架构的 CUDA 设备代码。虽然这是一个方便的特性,但它可能会导致由于几个中间步骤而增加构建时间。
特别地,编译器需要对 CUDA C ++源代码进行多次处理,并使用不同的 __CUDA__ARCH__ 内置宏的值来指定每个不同的计算架构,包括额外的预处理步骤,其中内置的宏未被定义,以编译主机平台的源代码。之后,预处理的 CUDA C ++设备代码实例必须编译成指定的每个目标 GPU 架构的机器代码。这些步骤目前是连续进行的。
为了减轻由多个编译过程产生的编译时间的增加,从 CUDA 11 。 2 版本开始, CUDA C ++编译器支持一个新的 —threads 《number》 命令行选项(简称-t)来生成单独的线程以并行执行独立编译传递。如果在单个 nvcc 命令中编译多个文件, -t 将并行编译这些文件。 参数确定 NVCC 编译器为并行执行独立编译步骤而生成的独立辅助线程数。
对于特殊情况 -t0 ,使用的线程数是机器上的 CPU 数。当调用 NVCC 为多个 GPU 架构同时编译 CUDA 设备代码时,此选项有助于减少总体构建时间。默认情况下,这些步骤是连续执行的。
Example
以下命令为两个虚拟体系结构生成。 ptx 文件: compute_52 和 compute_70 。对于 compute_52 ,为两个 GPU 目标生成。 cubin 文件: sm_52 和 sm_60 ;对于 compute_70 ,为 sm_70. 生成。 cubin 文件
nvcc -gencode arch=compute_52,code=sm_52 -gencode arch=compute_52,code=sm_60 -gencode arch=compute_70,code=sm_70 t.cu
并行编译有助于在编译大量应用 CUDA C ++设备代码到多个 GPU 目标的应用程序时减少总体构建时间。如果源代码主要是 C / C ++主机代码,只有少量 CUDA 设备代码,或者如果仅以单个虚拟架构/ GPU-SM 组合为目标,则可能不会减少整个构建时间。换句话说,构建时的加速可能会因程序、编译目标特性以及 NVCC 可以生成的并行编译线程的数量而异。
NVCC 启动 helper 线程来动态地并行执行编译步骤(如 CUDA 编译轨迹图 中所描述的),受编译步骤之间的序列化依赖关系的约束,其中编译步骤仅在其依赖的所有先前步骤完成之后才在单独的线程上启动。
图 7 显示了当 NVCC 生成的独立编译线程的限制增加时( -t N 选项),由于并行编译而导致的 CUDA 编译加速是如何变化的。这适用于需要不同级别的独立编译步骤的编译轨迹,这些步骤可以并行执行。
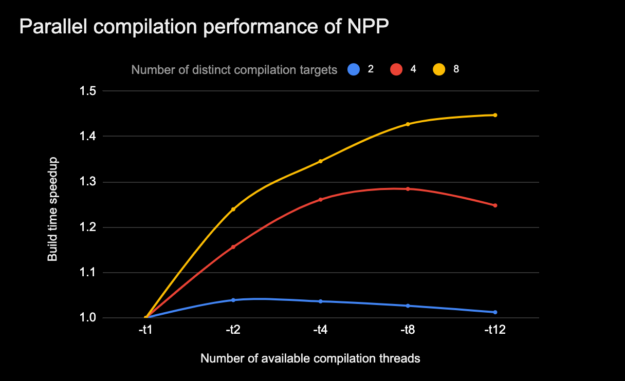
图 7 。为多个 GPU 架构编译 NVIDIA 性能原语( NPP )的并行编译加速。
CPU 型号: i7-7800X CPU @ 3 。 50GHz # CPU : 12 ,每核线程数: 2 ,每插槽核数: 6 ,内存: 31G 。 (所有的编译都使用 make-j8 )
NVCC 并行线程编译特性可以与进程级构建并行性(即, make -j N )一起使用。但是,必须考虑主机平台的特性,以避免过度订阅生成系统资源(例如, CPU 核心数、可用内存、其他工作负载),这可能会对总体生成时间产生负面影响。
新的编译器内置提示,可以更好地优化设备代码
CUDA 11 。 2 支持新的内置程序,使您能够向编译器指示编程提示,以便更好地生成和优化设备代码。
使用 __builtin_assume_aligned , 可以向编译器提示指针对齐,编译器可以使用指针对齐进行优化。类似地, __builtin_assume 和 __assume 内置可以用来指示运行时条件,以帮助编译器生成更好的优化代码。下一节将深入研究每个特定的内置提示函数。
void * __builtin_assume_aligned(const void *ptr, size_t align)
void *__builtin_assume_aligned(const void *ptr, size_t align, offset)
__builtin_assume_aligned内置函数可用于向编译器提示作为指针传递的参数至少与align字节对齐。当参数(char *)ptr - offset至少与align字节对齐时,可以使用带有offset的版本。两个函数都返回参数指针。
编译器可以使用这种对齐提示来执行某些代码优化,如加载/存储矢量化,以更好地工作。考虑一下这里显示的函数中的示例代码,该函数使用内置函数来指示参数ptr可以假定至少与 16 个字节对齐。
__device int __get(int*ptr)
{
int *v = static_cast
(__builtin_assume_aligned(ptr, 16));
return *v + *(v+1) + *(v+2) + *(v+3);
}
前面的代码示例在使用nvcc -rdc=true -ptx foo.cu编译时没有内置函数,生成了以下 PTX ,其中对返回表达式执行了四个单独的加载操作。
ld.u32 %r1, [%rd1]; ld.u32 %r2, [%rd1 + 4]; ld.u32 %r4, [%rd1 + 8]; ld.u32 %r6, [%rd1 +12];
当使用内置函数向编译器提示指针是 16 字节对齐的时,生成的 PTX 反映了这样一个事实:编译器可以将加载操作组合成一个向量化的加载操作。
ld.v4.u32 {%r1, %r2, %r3, %r4 }, [%rd1];
由于四个加载是并行执行的,因此单个矢量化加载操作所需的执行时间更少。这避免了向内存子系统发出多个请求的开销,同时还保持了较小的二进制大小。
void * __builtin_assume(bool exp)
__builtin__assume内置函数允许编译器假定提供的布尔参数为 true 。如果参数在运行时不为 true ,则行为未定义。参数表达式不能有副作用。尽管 CUDA 11 . 2 文档指出副作用已被丢弃,但此行为在将来的版本中可能会发生更改,因此可移植代码在提供的表达式中不应产生副作用。
例如,对于下面的代码段, CUDA 11 . 2toolkit 编译器可以用更少的指令优化 modulo-16 操作,因为知道num变量的值是肯定的。
__device__ int mod16(int num){__builtin_assume(num > 0);return num % 16;}
如下一个生成的 PTX 代码示例所示,当使用nvcc -rdc=true -ptx编译示例代码时,编译器为模运算生成一条 AND 指令。
ld.param.u32 %r1, [_Z5Mod16i_param_0];and.b32 %r2, %r1, 15;st.param.b32 [func_retval0+0], %r2;
如果没有提示,编译器必须考虑num值为负值的可能性,如生成的 PTX 代码(包括附加指令)所示。
ld.param.u32 %r1, [_Z5Mod16i_param_0];
shr.s32 %r2, %r1, 31;
shr.u32 %r3, %r2, 28;
add.s32 %r4, %r1, %r3;
and.b32 %r2, %r1, 15;
sub.s32 %r6, %r1, %r5
st.param.b32 [func_retval0+0], %r2;
使用时, NVCC 还支持类似的内置函数__assume(bool)cl . exe 文件作为主机编译器。
void * __builtin_unreachable(void)
在 CUDA 11 . 3 中,我们将介绍__builtin_unreachable内置函数。这个内置函数在 CUDA 11 . 3 中引入时,可用于向编译器指示控制流永远不会到达调用此函数的点。如果控制流在运行时到达该点,则程序具有未定义的行为。此提示可以帮助代码优化器生成更好的代码:
__device__ int get(int input)
{
switch (input)
{
case 1: return 4;
case 2: return 10;
default: __builtin_unreachable();
}
}
用 CUDA 11 . 3 中的nvcc -rdc=true -ptx编译早期代码片段生成的 PTX 将把整个 switch 语句优化为一条 SELECT 指令。
ld.param.u32 %r1, [_Z3geti_param_0];
setp.eq.s32 %p1, %r1, 1;
selp.b32 %r2, 4, 10, %p1;
st.param.b32 [func_retval0+0], %r2;
如果没有__builtin_unreachable调用,编译器将生成一个警告,指出控制流已到达非 void 函数的结尾。通常,必须注入一个伪返回 0 以避免出现警告消息。
__device__ int get(int input)
{
switch (input)
{
case 1: return 4;
case 2: return 10;
default: return 0;
}
}
添加 return 以避免编译器警告会导致更多的 PTX 指令,这也有抑制进一步优化的潜在副作用。
ld.param.u32 %r1, [_Z3geti_param_0]; setp.eq.s32%p1, %r1, 2; selp.b32%r2, 10, 0, %p1; setp.eq.s32%p2, %r1, 1; selp.b32%r3, 4, %r2, %p2; st.param.b32[func_retval0+0], %r2;
__builtin_assume和__builtin_assume_aligned函数在内部映射到llvm.assumeLLVM 内在函数。
“ 请注意,优化器 MIG ht 限制对 llvm.assume 保留仅用于形成内在函数输入参数的指令。如果用户提供的额外信息 llvm.assume 内在的并不能导致代码质量的全面提高。因此, llvm.assume 不应用于记录优化器可以以其他方式推断的基本数学不变量或对优化器没有多大用处的事实。”
某些主机编译器可能不支持早期的内置函数。在这种情况下,必须注意在代码中调用内置函数的位置。
下表给出了主机编译器为 gcc 时使用 __builtin_assume 的示例。由于 gcc 不支持此内置函数,因此在未定义 __CUDA_ARCH__ 宏的主机编译阶段,对 __builtin_assume 的调用不应出现在 __device__ 函数之外。

表 1 。当主机编译器不支持内置项时,使用内置项的示例。
有关如何使用这些内置函数的详细信息,请参阅 编译器优化提示函数 。
警告可以被抑制或标记为错误
NVCC 现在支持可以用来管理编译器诊断的命令行选项。您可以选择让编译器随诊断消息一起发出错误号,并指定编译器应将与错误号关联的诊断视为错误还是完全抑制。这些选项不适用于主机编译器或预处理器发出的诊断。在将来的版本中,编译器还将支持 pragmas ,以将特定的警告提升到错误或抑制它们。
Usage
--display-error-number (-err-no)
显示 CUDA 前端编译器生成的任何消息的诊断号。
--diag-error 《error-number》,。.. (-diag-error)
为 CUDA 前端编译器生成的指定诊断消息发出错误。
--diag-suppress 《error-number》,。.. (-diag-suppress)
抑制 CUDA 前端编译器生成的指定诊断消息。
Example
设备函数 hdBar 调用主机函数 hostFoo 并且变量 i 在 hostFoo 中未使用的示例代码:
void hostFoo(void)
{
int i = 0;
}
__host__ __device__ void hdBar(bool cond)
{
if (cond)
hostFoo();
}
以下代码示例显示带有默认警告的诊断号:
$nvcc -err-no -ptx warn.cu
warn.cu(1): warning #177-D: variable "i" was declared but never referenced
warn.cu(2): warning #20011-D: calling a __host__ function("hostFoo()") from a __host__ __device__ function("hdBar") is not allowed
以下代码示例将警告# 20011 升级为错误:
$nvcc -err-no -ptx -diag-error 20011 warn.cu
warn.cu(1): warning #177-D: variable "i" was declared but never referenced
warn.cu(2): error: calling a __host__ function("hostFoo()") from a __host__ __device__ function("hdBar") is not allowed
以下代码示例禁止显示警告# 20011 :
$nvcc -err-no -ptx -diag-suppress 20011 warn.cu warn.cu(1): warning #177-D: variable "i" was declared but never referenced
NVVM 升级到 LLVM 7 。 0
CUDA 11 。 2 编译器工具链接收 LLVM7 。 0 升级。
升级到 LLVM 7 。 0 将打开通向此 LLVM 版本中存在的新功能的大门。它通过利用 LLVM 7 中可用的新优化,为进一步实现性能调整工作提供了更坚实的基础。
图 8 显示了使用包含基于 LLVM7 。 0 的高级 NVVM 优化器的 11 。 2 编译器工具链编译的 HPC 应用程序子集对基于 Volta 和 Ampere 的 GPU 的运行时性能影响,而 11 。 1 编译器工具链包含基于 LLVM3 。 4 的高级 NVVM 优化器。
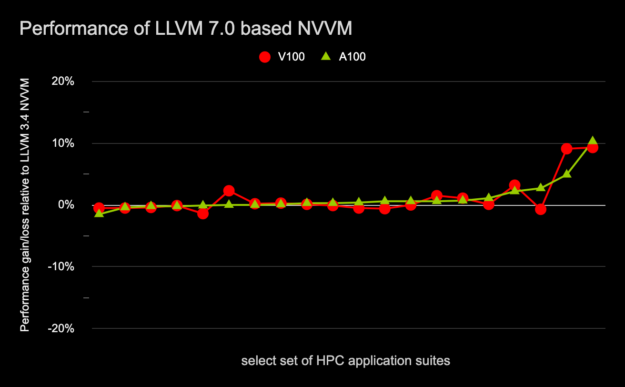
图 8 。 HPC 应用程序套件的 Geomean 性能增益/损失
相对于 LLVM3 。 4 ,基于 A100 和 V100 的 NVVM 。
libnvm 升级到 LLVM 7 。 0
使用 CUDA 11 。 2 版本, CUDA C ++编译器, LIbvvm 和 NVRTC 共享库都已升级到 LLVM 7 代码库。 libNVVM 库为 LLVM 提供了 GPU 扩展,以支持更广泛的社区,包括编译器、 DSL 转换器和针对 NVIDIA GPU 上计算工作负载的并行应用程序。 NVRTC 共享库有助于在运行时编译动态生成的 CUDA C ++源代码。
由于 libNVVM 库包含 llvm7 。 0 支持, libnvvmapi 和 nvvmir 规范已修改为与 llvm7 。 0 兼容。要更新输入 IR 格式,请参阅已发布的 NVVM IR 规范。此 libNVVM 升级与以前版本中支持的调试元数据 IR 不兼容。依赖于调试元数据生成的第三方编译器应该适应新的规范。在这次升级中, libnvm 也不推荐使用文本 IR 接口。我们建议您使用 LLVM 7 。 0 位码格式 。有关对基于 libnvm 的编译器软件所做更改的更多信息,请参阅 libNVVM 规范 和 NVVM IR 规范 。
此升级还带来了对源代码级调试支持的增强。编译器前端可能需要一个矮型表达式来指示在运行时保存变量值的位置。如果没有对 DWARF 表达式的适当支持,则无法在调试器中检查此类变量。 libNVVM 升级的一个重要方面是,使用 DWARF 表达式之类的操作可以更广泛地表达这些变量位置。 NVVM IR 现在使用 本质与操作 支持此类表达式。这样一个变量的最终位置用这些表达式用 DWARF 表示
试试 CUDA 11 。 2 编译器的功能
CUDA 11 。 2 工具包包含了一些专注于提高 GPU 性能和提升开发人员体验的功能。[VZX107 型]
编译器工具链升级到 LLVM 7 、设备 LTO 支持和新编译器内置的能力,这些能力可以利用来增强 CUDA C ++应用程序的性能。
对内联设备函数的虚拟堆栈回溯支持、关于函数内联决策的编译器报告、并行 CUDA 编译支持以及控制编译器警告诊断的能力是 CUDA 11 。 2 工具包中的新功能,旨在提高您的生产效率。
关于作者
Arthy Sundaram 是 CUDA 平台的技术产品经理。她拥有哥伦比亚大学计算机科学硕士学位。她感兴趣的领域是操作系统、编译器和计算机体系结构。
Jaydeep Marathe 是 NVIDIA 的高级编译工程师。他拥有北卡罗来纳州立大学计算机科学硕士和博士学位。
Hari Sandanagobalane 是 NVIDIA 的高级编译工程师。他拥有新加坡国立大学计算机科学硕士学位。
Gautam Chakrabarti 是 NVIDIA 的高级编译工程师。他的兴趣包括编译器技术,使高效的程序执行和改善开发人员的经验。他拥有密歇根州立大学计算机科学硕士学位。
Mukesh Kapoor 是 NVIDIA 的高级编译工程师。他拥有印度班加罗尔工业学院自动化硕士学位。Steve Wells 是 NVIDIA 的高级调试器工程师。他拥有滑铁卢大学的数学学士学位。Mike Murphy 是 NVIDIA 的高级编译工程师。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4978浏览量
102980 -
编译器
+关注
关注
1文章
1623浏览量
49107
发布评论请先 登录
相关推荐
在动态环境中使用CUDA图提高实际应用程序性能

PortlandGroup推出PGI CUDA编译器
如何使用英特尔Fortran编译器生成更快的应用程序
如何利用C/C++编写应用程序加速内核运行
AVR程序编译器avrubd应用程序免费下载

NVIDIA CUDA C ++编译器的新特性
用NVIDIA CUDA11.2 C ++编译器提高应用性能
使用NVIDIA数学库加速GPU应用程序
第6代光纤通道:加速全闪存数据中心的数据访问和应用程序性能






 工商网监
工商网监
评论