 基于Coretex-M3 Design Start的语音识别和声源定位识别系统
基于Coretex-M3 Design Start的语音识别和声源定位识别系统
写在前面
能获得企业大奖其实是出乎预料的,论复杂程度我自己认为可能也无法比的上其他学校的朋友们的(不过是因为今年没有线下交流,着实无法看到大家的作品),但我觉得组委会能选择我们组作为企业大奖,可能也是想通过我们来拓宽大家的思路,而并不一定是我们的作品做的是多么完美。
学习了近几年ARM杯的作品,感觉大家都是在同一个领域做文章(当然去年那组BLDC的hxd例外),那就是视觉和图像处理方面。这方面感觉大家做的都非常好了,无论是用现成的算法拆分成verilog中的矩阵运算,还是利用HLS这类高层次综合工具,我觉得如果继续做视觉方面的内容我们可能再怎么努力也无法达到他人积累多年经验的程度,所以我们选择换一个角度。
人类有五种感官,嗅觉和味觉目前来说无法做到辅助(笑,还剩下听觉、视觉和触觉,视觉被我们直接否定了,那么触觉呢?目前高精度的传感器也不是我们能企及做到的了,这和生物医学电子有关,那么我们的眼前就只有一个选择了:听觉。
这也正是我们选择做这个系统的原因之一,还有一个原因是我们能感觉得到现在的消费电子都逐渐在向声学方面走,例如苹果的HomePod,华为的Sound X,还有小米最近刚推出的小米Sound,这些都是非常高端的走计算声学方向的家居产品,它们的受众非常广,而且在这两年疫情的影响下,更多的人会选择在线会议,那么一个优秀的声学处理装置就显得更为重要了。
1.设计简介
1.1 总体介绍
本作品是基于Coretex-M3 Design Start的语音识别和声源定位识别系统,包括Digilent NexysVideo开发板、自制麦克风矩阵模块、ESP8266无线互联模块、LCD屏幕、载体小车以及安卓端APP组成。
本系统在Xilinx Artix-7中搭建ARM Cortex-M3软核作为中央处理器,使用自制的MEMS硅片麦克风阵列作为声音信号采集器,利用Artix-7中自带的XADC将麦克风输出的vwin 量信号转换为数字信号并通过AXI4-FULL传输给DDR3控制器,DDR3控制器根据用户的控制选择输入和输出,当开始语音识别后,将开启后1s内的数据从DDR3中直接利用Burst读入语音识别模块,该模块利用HLS综合,包括语音的MFCC特征提取、BP神经网络的执行等过程,将最终得出的语音识别结果保存在寄存器中并能使CPU通过AXI4-Lite读取;当开启声源定位后,数据利用AXI4-Stream直接搬移到算法电路模块,对四路麦克风同时进行流水线处理,经过信号的处理和变换后得到声源方位数据通过UART串口输出到ESP8266,ESP8266利用局域网将数据传至安卓APP。
有一点我们的体会可以分享给其他朋友们,如果我们在一段时间内只需要处理一段定长的数据,那么我们可以不利用DMA,而是仅仅利用AXI的Burst传输即可,例如采集1s的信号寸到DDR中一段连续区域以后,将这些的音频信号数据整个Burst到加速器中,这样可以充分发挥总线桥的作用,并节省一个DMA的资源,还可以减小数据搬移过来过去的时延。
1.2 硬件架构
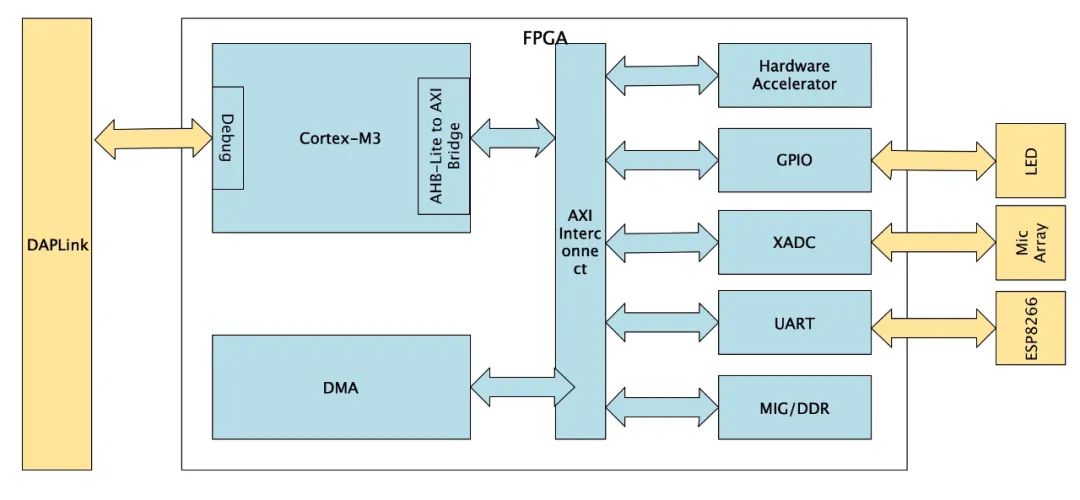
在本系统中,由于最终制作的语音识别加速器和声源定位加速器都使用AXI系列总线配置寄存器和读写数据,同时DDR3由AXI总线接口的MIG管理,因此为了方便实用和同一总线,使整个架构简洁,我们将除了ITCM和DTCM外的所有外设连接在由AHB转换之后的AXI总线桥上。
1.3 语音识别加速器
语音识别采用的方案是利用MFCC提取特征,之后利用BP神经网络拟合特征系数对应的神经网络隐含层参数。首先输入的语音数据从DDR经过Burst传输到信号处理模块中,经过预处理(去工频噪声、音量均衡)后提取MFCC,再利用BP网络将MFCC系数与训练过的语句一一对应输出对应的结果。语音识别的网络的权重参数采用的是MATLAB离线训练的方法,然后把训练的权重数据保存在coe文件中,利用HLS综合出IP。
流程图如下:

1.4 声源定位加速器
声源定位加速器融合了TDOA(Time Difference of Arrival 到达时间差)和空域波束指向性加权的方法。
由四个全向性麦克风M1, M2, M3, M4组成的差分麦克风列,如图2.10所示。四麦克风等间隔的分布在直径为D的圆周上。
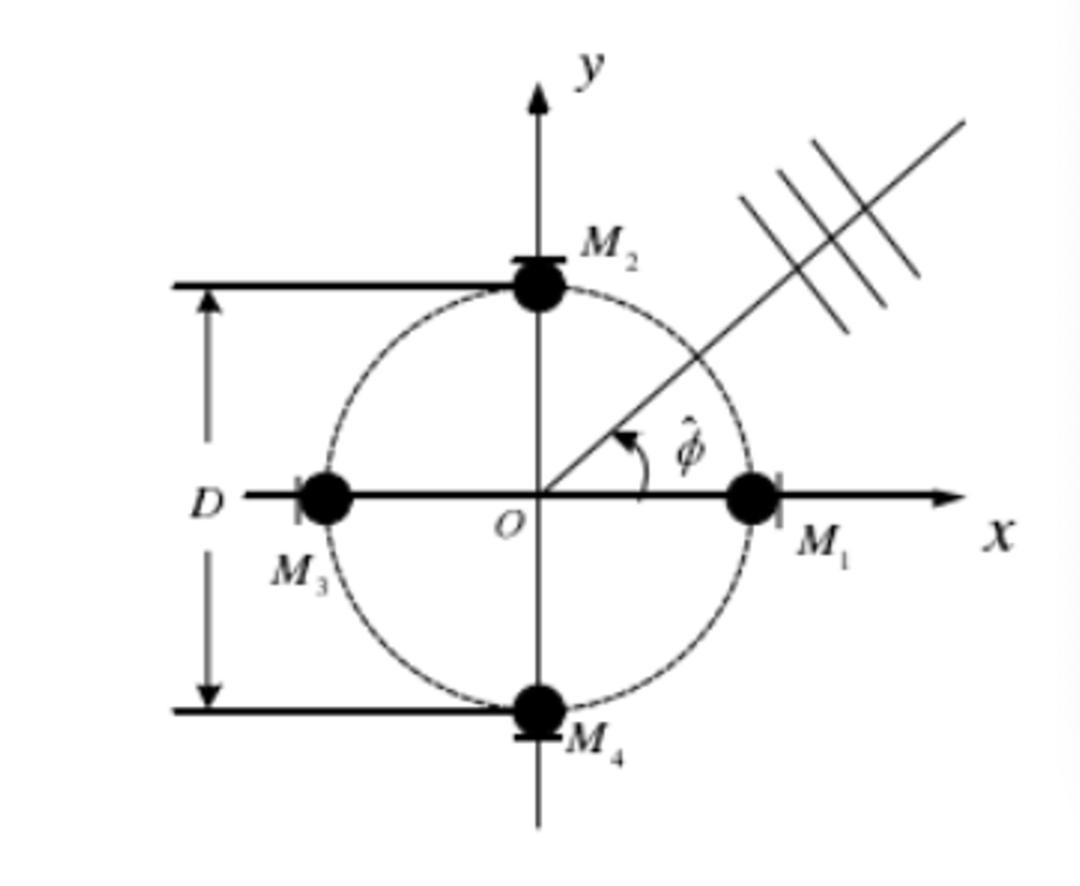
差分麦克风阵列的输出信号包括原点处的声压信号和原点处振速的两个正交分量,可以得到声源在原点处的声强,进而由声强的方向得到目标方位的估计值。需要指出的是,基于声强估计的声源定位方法通常只适用于单声源的情况。同时,对于全向麦克风而言(不同于“心”形指向麦克风),并没有对特定角度的声源信号进行增强或削弱,这就使得在进行声源定位时往往受到其他方向的干扰。采用空域波束指向性加权的方法,可以只增强期望方向上的信号,削弱其他方向上的干扰信号,提高信干比,使得输出结果中特定方向上的信息能量增大。
2.作品外观和使用体验
作品成品外观如下:



审核编辑 :李倩
-
语音识别
+关注
关注
38文章
1739浏览量
112634 -
识别系统
+关注
关注
1文章
138浏览量
18810 -
CORETEX
+关注
关注
0文章
2浏览量
6316
原文标题:【2021集创赛作品分享】第三期 | Cortex-M3语音识别声源定位系统
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于语音识别的智能会议系统具备哪些交互功能
RFID识别系统
物联网系统智能控制产品的语音识别方案_离线语音识别芯片分析


智能玩具用离线语音识别芯片有什么优势


基于FPGA的指纹识别系统设计
多目标智能识别系统
基于OpenCV的人脸识别系统设计
语音识别和自然语言处理的区别和联系
整合离线语音识别ASR和TTS,内存映射时发生内存不足怎么解决?
基于GIS的SAR多目标智能识别系统
车载语音识别系统语音数据采集标注案例






 工商网监
工商网监
评论