 使用RAPIDS加速实现SHAP的模型可解释性
使用RAPIDS加速实现SHAP的模型可解释性
机器学习( ML )越来越多地用于医疗、教育和金融服务等多个领域的决策。由于 ML 模型被用于对人们有实际影响的情况,因此了解在消除或最小化偏见影响的决策中考虑了哪些特征是至关重要的。
模型解释性 帮助开发人员和其他利益相关者理解模型特征和决策的根本原因,从而使流程更加透明。能够解释模型可以帮助数据科学家解释他们的模型做出决策的原因,为模型增加价值和信任。在本文中,我们将讨论:
对模型可解释性的需求
使用 SHAP 的可解释性
使用 演示笔记本 在 Azure 机器学习上使用 SHAP 进行模型解释。
为什么我们需要解释性?
有六个主要原因证明机器学习中需要模型互操作性:
理解模型中的公平性问题
对目标的准确理解
创建健壮的模型
调试模型
解释结果
启用审核
了解模型中的公平性问题: 可解释模型可以解释选择结果的原因。在社会背景下,这些解释将不可避免地揭示对代表性不足群体的固有偏见。克服这些偏见的第一步是看看它们是如何表现出来的。
更准确地理解目标: 对解释的需要也源于我们在充分理解问题方面的差距。解释是确保我们能够看到差距影响的方法之一。它有助于理解模型的预测是否符合利益相关者或专家的目标。
创建稳健的模型: 可解释模型可以帮助我们理解预测中为什么会存在一些差异,这有助于使预测更加稳健,并消除预测中极端和意外的变化;以及为什么会出现错误。增强稳健性也有助于在模型中建立信任,因为它不会产生显著不同的结果。
模型可解释性还可以帮助调试模型,解释 向利益相关者提供成果,并使 auditing 以满足法规遵从性。
需要注意的是,在某些情况下,可解释性 MIG 不太重要。例如,在某些情况下,添加可解释模型可以帮助对手欺骗系统。
现在我们了解了什么是可解释性以及为什么我们需要它,让我们看看最近非常流行的一种实现方法。
使用 SHAP 和 cuML 的 SHAP 的可解释性
有不同的方法旨在提高模型的可解释性;一种模型不可知的方法是 夏普利值 。这是一种从联盟博弈论中衍生出来的方法,它提供了一种公平地将“支出”分配给各个功能的方法。在机器学习模型的情况下,支出是模型的预测/结果。它的工作原理是计算整个数据集的 Shapley 值并将其组合。
cuML 是 RAPIDS 中的机器学习库,支持单 GPU 和多 GPU 机器学习算法,通过 内核解释程序 和 置换解释者 提供 GPU 加速模型解释能力。 核形状 是 SHAP 最通用和最常用的黑盒解释程序。它使用加权线性回归来估计形状值,使其成为一种计算效率高的近似值方法。
内核 SHAP 的 cuML 实现为快速 GPU 模型提供了加速,就像 cuML 中的那些模型一样。它们也可用于基于 CPU 的模型,在这些模型中仍然可以实现加速,但由于数据传输和模型本身的速度,它们 MIG 可能会受到限制。
在下一节中,我们将讨论如何在 Azure 上使用 RAPIDS 内核 SHAP 。
使用解释社区和 RAPIDS 实现可解释性
InterpretML 是一个开源软件包,将最先进的机器学习可解释性技术集成在一起。虽然本产品的解释包中涵盖了主要的解释技术和玻璃盒解释模型, Interpret-Community 扩展了解释存储库,并进一步整合了社区开发的和实验性的解释性技术和功能,这些技术和功能旨在实现现实场景的解释性。
我们可以将其扩展到 解释 Microsoft Azure 上的模型 ,稍后将对其进行更详细的讨论。解释社区提供各种解释模型的技术,包括:
Tree 、 Deep 、 Linear 和 Kernel Explainers 基于形状,
vwin 解释者 基于训练 全局代理模型 (训练模型以近似黑盒模型的预测),以及
排列特征重要性( PFI )解释者 基于 布雷曼关于兰德森林的论文 ,其工作原理是对整个数据集一次一个特征的数据进行洗牌,并估计其对性能指标的影响;变化越大,功能越重要。它可以解释整体行为,而不是个人预测。
在社区中集成 GPU 加速 SHAP
为了使 GPU – 加速 SHAP 易于最终用户访问,我们将 integrated 从 cuML 的 GPU 内核解释者 添加到 interpret-community 包中。有权访问 Azure 上具有 GPU s 的虚拟机 ( NVIDIA Pascal 或更高版本)的用户可以安装 RAPIDS (》= 0.20 )并通过将 use _ ZFK5]标志设置为 True 来启用 GPU 解释程序。
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes, use_gpu=True)
新添加的 GPUKernelExplainer 还使用 cuML K- 均值 来复制 shap.kmeans 的行为。 KMeans 减少了解释者要处理的背景数据的大小。它总结了通过 K 个平均样本传递的数据集,这些样本由数据点的数量加权。将 sklearn K-Means 替换为 cuML 使我们能够利用 GPU 的速度提升,即使在 SHAP 之前的数据预处理过程中也是如此。
基于我们的实验,我们发现,当与 cuML KerneleExplainer 一起使用时, cuML 模型在某些情况下会产生最高可达 270 倍的速度提升的最佳结果。我们还看到了具有优化和快速预测调用的模型的最佳加速,如优化的 sklearn 。 svm 。 LinearSVR 和 cuml 。 svm 。 SVR ( kernel =’ linear ‘) 所示。
Azure 中的模型解释
Azure 机器学习提供了一种通过 azureml-interpret SDK 包获取常规和自动化 ML 培训说明的方法。它使用户能够在训练和推理期间,在真实世界数据集上实现大规模的模型可解释性[2]。我们还可以使用交互式可视化来进一步探索整体和单个模型预测,并进一步了解我们的模型和数据集。 Azure 解释使用解释社区包中的技术,这意味着它现在支持 RAPIDS 形状。我们将浏览一个演示 Azure 上使用 cuML 形状的模型可解释性 的示例笔记本。
在 GPU 虚拟机上使用自定义 Docker 映像设置 RAPIDS 环境(本例中为标准的_ NC6s _ v3 )。
| from azureml.core import Environment | |
| environment_name = "rapids" | |
| env = Environment(environment_name) | |
| env.docker.enabled = True | |
| env.docker.base_image = None | |
| env.docker.base_dockerfile = """ | |
| FROM rapidsai/rapidsai:0.19-cuda11.0-runtime-ubuntu18.04-py3.8 | |
| RUN apt-get update && \ | |
| apt-get install -y fuse && \ | |
| apt-get install -y build-essential && \ | |
| apt-get install -y python3-dev && \ | |
| source activate rapids && \ | |
| pip install azureml-defaults && \ | |
| pip install azureml-interpret && \ | |
| pip install interpret-community==0.18 && \ | |
| pip install azureml-telemetry | |
| """ | |
| env.python.user_managed_dependencies = True |
 by
by 我们提供了一个脚本( train_explain.py ),它使用 cuML SVM 模型训练和解释了一个二进制分类问题。在这个例子中,我们使用 希格斯数据集 来预测一个过程是否产生希格斯玻色子。它有 21 个由加速器中的粒子探测器测量的运动学特性。
然后,该脚本使用 GPU SHAP KerneleExplainer 生成模型解释。
生成的解释使用我们的 ExplanationClient 上传到 Azure 机器学习,这是上传和下载解释的客户端。这可以在您的计算机上本地运行,也可以在 Azure 机器学习计算机上远程运行。
生成的解释上传到 Azure 机器学习运行历史记录后,您可以在 Azure 机器学习工作室 中的解释仪表板上查看可视化。
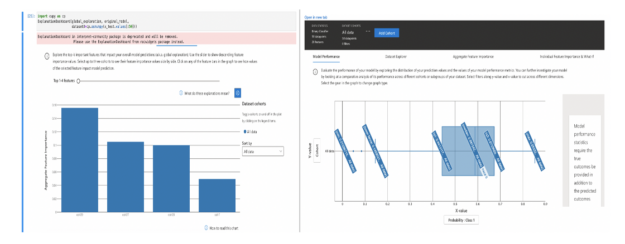
图 1 :显示模型性能和特性重要性的解释仪表板。
我们在 Azure 中的单个 explain _全局调用上对 CPU 和 GPU 实现进行了基准测试。 explain _ global 函数在使用 explain _ local 时返回聚合特征重要性值,而不是实例级特征重要性值。我们比较了 cuml 。 svm 。 SVR ( kernel =’ rbf ‘)与 sklearn 。 svm 。 SVR ( kernel =’ rbf ‘)对形状为( 10000 , 40 )的合成数据的影响。
从表 1 中我们可以观察到,当我们使用 GPU 虚拟机( Standard _ NC6S _ v3 )时,与具有 16 个内核的 CPU 虚拟机( Standard _ DS5 _ v2 )相比, 2000 行解释的速度提高了 420 倍。我们注意到,在 16 核 CPU 虚拟机上使用 64 核 CPU 虚拟机(标准_ D64S _ v3 )可以产生更快的 CPU 运行时间(大约 1 。 3 倍)。这种更快的 CPU 运行仍然比 GPU 运行慢得多,而且更昂贵。 GPU 运行速度快了 380 倍,成本为 0 。 52 美元,而 64 核 CPU 虚拟机的成本为 23 美元。我们在 Azure 的美国东部地区进行了实验。
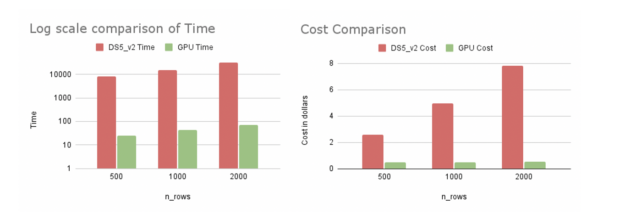
图 2 : Azure 上 CPU 和 GPU 虚拟机的比较。
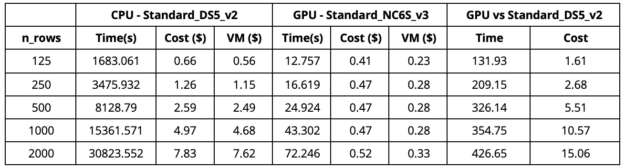
表 1 :标准 DS5 和标准 NC6s _ v3 的比较。
从我们的实验来看,在 Azure 上使用 cuML 的 KernelExplainer 被证明更具成本和时间效率。随着行数的增加,速度会更好。 GPU SHAP 不仅解释了更多的数据,而且还节省了更多的资金和时间。这会对时间敏感的企业产生巨大影响。
这是一个简单的例子,说明如何在 Azure 上使用 cuML 的 SHAP 进行解释。这可以扩展到具有更有趣的模型和数据集的更大示例。
关于作者
Nanthini 是 NVIDIA 的数据科学家和软件开发人员。她在 RAPIDS 团队工作,该团队专注于使用 GPU 加速数据科学管道。她的工作包括进行概念验证、开发和维护功能、将 RAPIDS 与外部框架集成,以及通过示例用例演示这些工具的使用。最近,她一直致力于 RAPIDS 框架和微软解释之间的集成。 2019 ,她获得了宾夕法尼亚大学计算机科学硕士学位。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4729浏览量
128887 -
机器学习
+关注
关注
66文章
8406浏览量
132557
发布评论请先 登录
相关推荐
基于LIBS技术的煤炭灰分、挥发分和热值定量分析及特征工程研究

RAPIDS cuDF将pandas提速近150倍

一种基于因果路径的层次图卷积注意力网络

FPGA加速深度学习模型的案例
常见AI大模型的比较与选择指南
LLM大模型推理加速的关键技术
基于FPGA的脉冲神经网络模型应用探索
【大规模语言模型:从理论到实践】- 阅读体验
【大语言模型:原理与工程实践】核心技术综述
Meta发布SceneScript视觉模型,高效构建室内3D模型
AI算法在矿山智能化中的应用全解析
爱立信推出认知软件新功能
顶刊TIP 2023!浙大提出:基于全频域通道选择的的无监督异常检测






 工商网监
工商网监
评论