 压缩语音以跨电话系统传输所需的模数转换
压缩语音以跨电话系统传输所需的模数转换
本文介绍了压扩主题——跨电话系统的人类语音的数字化、传输和转换。
简要背景
电话系统自发明以来一直处于高需求状态,并且已经从公共交换电话网络 (PSTN) 发展为现代无线数字移动系统。基于模数转换的脉冲编码调制 (PCM) 系统已经使用了六年。应该注意的是,无论使用哪种编码,所有电话系统都是通过利用人类语音和听觉机制背后的基本事实来工作的。
人类言语和听觉机制
语音是人类之间的自然交流机制。单词由不同的音素、幅度不同的单个声音组成,安静的音素比响亮的音素出现的频率更高。一般来说,人类产生的语音信号的频率范围为 70Hz~400Hz,而人类听觉的频率范围为20Hz~20kHz。我们的听力具有选择性,对300 Hz 至 10 kHz范围内产生的声音提供最高灵敏度。
这些以实验为依据的事实得出的结论是,当在 0.3 到 3.4 kHz 范围内记录语音信号时,听者很容易理解说话者所传达的信息。
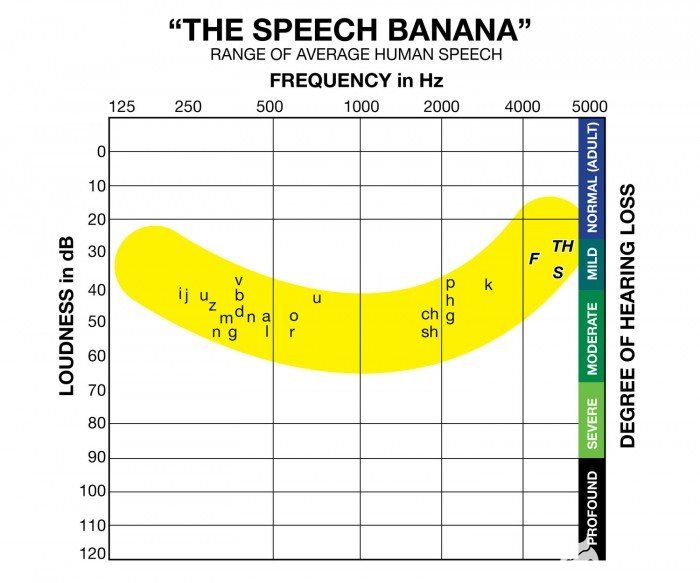
图 1. “语音香蕉”显示了音素及其在识别所需的各种幅度下的频率。图片由Clear Value Hearing提供。
当听力能力以分贝等级表示时,它的范围从 0 dB SPL(听力阈值)到 130 dB SPL(疼痛阈值)。
较低幅度和较高幅度之间的 比率很大。在一般意义上,较低幅度的声音被认为是耳语,而较高幅度的声音被认为是喊叫。然而,即使是正常的会话语音也有相当大的幅度变化,因为它是由不同的音素组成的。此外,可以看出,更安静的音素比响亮的音素携带更多的信息并且具有更多的熵。
无压扩的基于 PCM 的电话系统
电话系统最初是作为vwin 系统出现的,现在已经变成了数字系统。因此,无论我们说什么都需要数字化然后传输——因此实际的模拟语音信号需要在接收端进行恢复。任何模拟信号到其数字形式的转换都包括三个重要阶段:采样、量化和编码。
语音信号的采样
采样是一个过程,通过该过程,我们可以将在所有时刻定义的原始信号转换为仅在特定时刻定义的离散信号。
我们如何决定在哪些点定义信号?
我们首先考虑一个基本但非常重要的事实,即我们不仅对从发送方传输信号感兴趣,而且对在接收方恢复信号感兴趣。
与该过程相关的定理是著名的奈奎斯特定理,该定理指出,只有在至少以其中包含的最高频率两倍的速率对其进行采样时,才能忠实地恢复传输信号。
因此,如果最高频率是f,那么我们需要对信号进行采样的频率应该大于或等于 2 f。反过来,这意味着我们需要在距离小于或等于 1/2 f的时刻定义我们的信号 (由于频率和时间彼此成反比)。
从上一节的讨论中,我们知道我们对电话交谈的兴趣跨越了 0.3 到 3.4 kHz 的频率范围。并且任何成功的信号传输都需要存在保护频带,因此整个范围变为0 到 4 kHz。因此,在我们的例子中,8 kHz (= 2 x 4 KHz) 的采样率是一个不错的选择。
这表明,在采样之后,我们的语音信号沿时间轴离散化,其中相邻样本之间的间距将为 18KHz=125微秒18KHz=125微秒。
语音信号的量化与编码
请注意,采样仅对时间轴上的信号进行数字化(参见图 2 所示的典型示例,其中红色正弦信号通过采样转换为蓝色离散值信号)。然而,为了使语音信号在本质上完全数字化,我们需要沿其幅度轴对其进行离散化,这被视为量化。
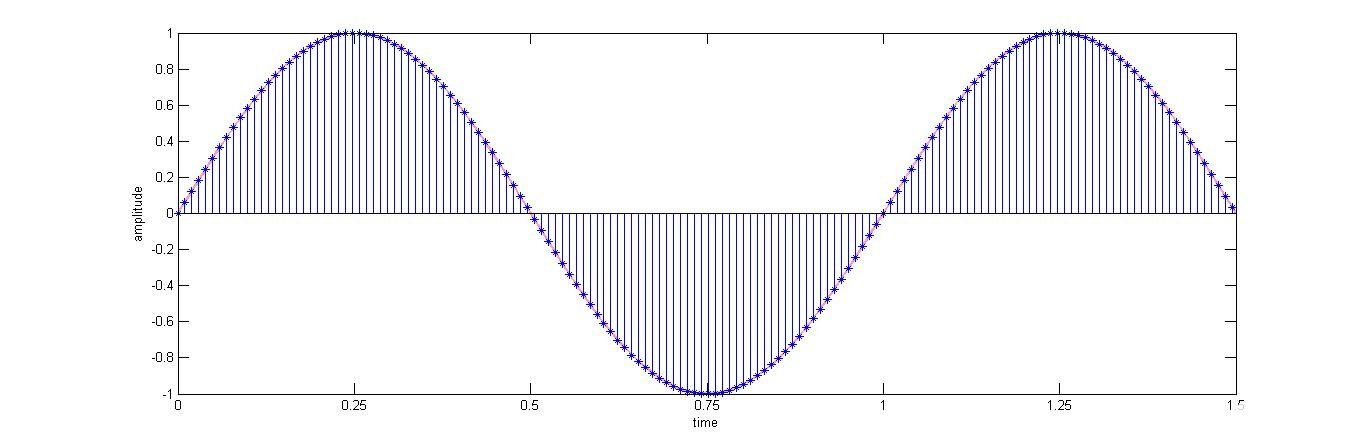
图 2.正弦波采样
现在,我们的下一个问题将与采样的情况非常相似——我们如何决定何时沿其幅度轴定义我们的信号?换句话说,我们定义信号幅度的点之间的间距应该是多少(这在技术上称为步长)?
即使在这种情况下,我们也需要选择步长,记住我们需要在接收端有最小的失真信号。这么想,让我们假设我们选择一个非常小的步长来量化低幅度信号(正弦波在值 +1 和 -1 之间变化,在图 3a 中以粉红色显示)。较小的步长意味着我们将沿其幅度轴以非常接近的间隔定义我们的信号(图 3a),因此定义我们的信号所需的步数将非常大,这需要大量的比特来对其进行编码,这需要很大的带宽。
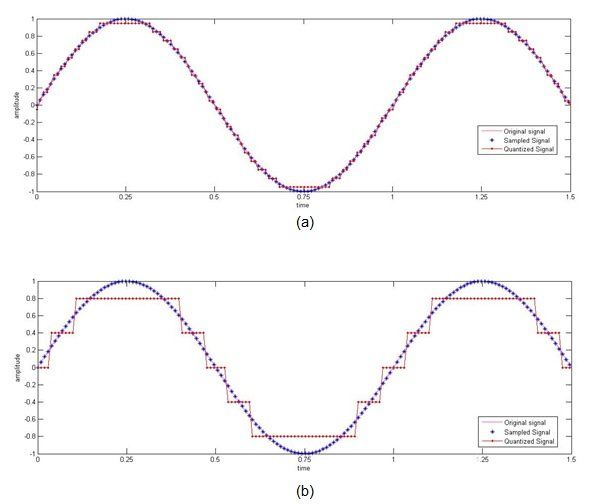
图 3. (a) 小步长 (b) 大步长的低幅度正弦波量化
考虑到带宽,让我们假设我们使用太少的步骤来定义我们的信号。较少的步数意味着我们沿其幅度轴定义信号的点之间的间距较大。这使我们能够非常粗略地定义我们的信号(图 3b),当我们在接收端重构信号时,这会导致问题,因为在量化过程中会丢失很多存在的信息。
接下来,我们分析在大振幅信号的情况下改变步长的影响。这在目前的情况下很重要,因为我们从关于人类言语和听力机制部分的讨论中知道,我们感兴趣的信号(言语)包含广泛的幅度。
图 4 使用与图 3 相同的步长来检查量化的效果,当幅度增加四倍时(图 4 中的原始正弦波的峰峰值幅度在 +4 到 -4 之间变化)。在这里,图 4a 再次强调了这样一个事实,即当我们需要复制原始信号时,较小的步长总是更好。
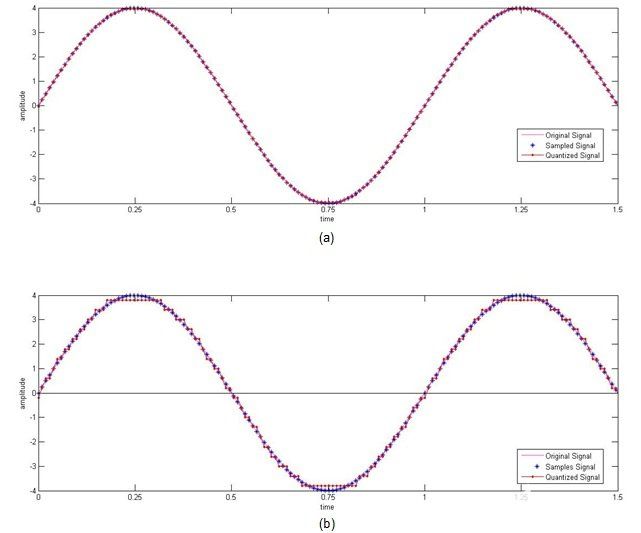
图 4. (a) 小步长 (b) 大步长的大振幅正弦波量化
另一个需要注意的重点是,图 4b 中的量化信号不像图 3b 中所示的量化信号那样失真。也就是说,当信号幅度较高时,使用大步长的量化仍然会产生可接受的结果。这意味着当涉及到大幅度信号时,被证明对于低幅度信号“非常大”的步长并不是“那么大”。换句话说,可以说信号的幅度越高,量化它的步长就越大,而不会产生太大的失真。
压扩:简介
每个研究人员都相信,任何系统,无论多么好,都可以以某种方式进行改进。然而,为了找出最有效(或更好)的方法,必须仔细审查目前采用的概念和方法,并且必须从不同的角度进行审查。
为了在我们的案例中实现这一点,让我们回顾文章的路径,同时思考两个重要点。
首先,请回想一下,就其中包含的信息而言,人类语言不是各向同性的。语音中较安静的音素比大声的音素出现得更频繁并且包含更多的信息。其次,请注意,与较低幅度的信号相比,对于较高幅度的信号,选择用于量化信号的步长可以更大(而不影响其质量)。
如果是这样,为什么我们不能使用较小的步长量化低幅度的语音信号,而对幅度较大的语音信号使用较大的步长呢?可以办到。事实上,这种使用非均匀电平量化语音信号的技术被称为“压缩扩展”,是压缩和扩展的组合。
压缩扩展是使用不等量化级别对信号进行编码的过程。在该技术中,大量的小电平用于对低幅度信号进行编码,而较高幅度的信号使用少量的大电平进行编码。这意味着通过使用压扩,我们可以用更少的电平量化我们的语音信号,同时保持所需的保真度。此外,级别数越少意味着要编码的比特越少,这意味着带宽要求降低。
结论
本文介绍了与人类语音相关的概念及其在基于 PCM 的电话系统中的特征。我希望您已经获得了关于压扩及其在电信领域的重要性的肤浅知识。
-
PCM
+关注
关注
1文章
195浏览量
53203 -
模数转换
+关注
关注
1文章
216浏览量
36864
发布评论请先 登录
相关推荐
Nios II语音加密传输系统有什么作用?
基于UDP协议的语音传输系统设计及实现
基于DSP网络电话终端语音传输的研究
IP网络电话中常用的语音压缩编码技术的性能分析

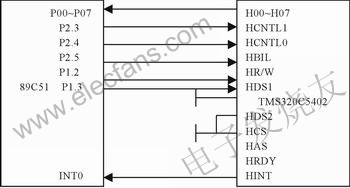
基于DSP芯片TMS320C5402的数字压缩语音录放系统
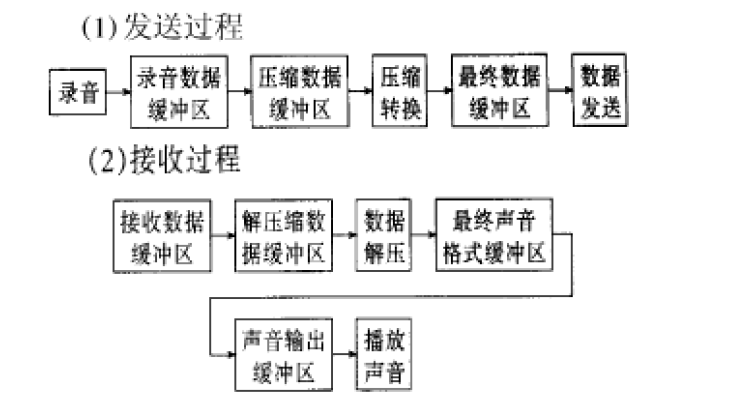
一种语音压缩处理通用DSP系统的设计与实现
MSP430 的语音与音频压缩/解压缩技术
如何使用UDP协议设计及实现语音传输系统的方法详细说明
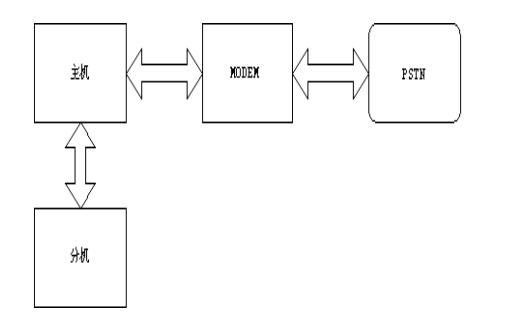
基于DSP技术模数兼容的多通道数字电话设计






 工商网监
工商网监
评论