 RapidStream:FPGA HLS设计的并行物理实现
RapidStream:FPGA HLS设计的并行物理实现
FPGA的布局布线软件向来跑得很慢。事实上,FPGA供应商已经花了很大的精力使其设计软件在多核处理器上运行得更快。
最近,在ACM的FPGA 2022会议上发表了一篇题为“RapidStream: FPGA HLS设计的并行物理实现”的论文,论文中描述了一种非常有趣的方法,通过FPGA设计软件推动HLS设计更快地运行在多核处理器上。
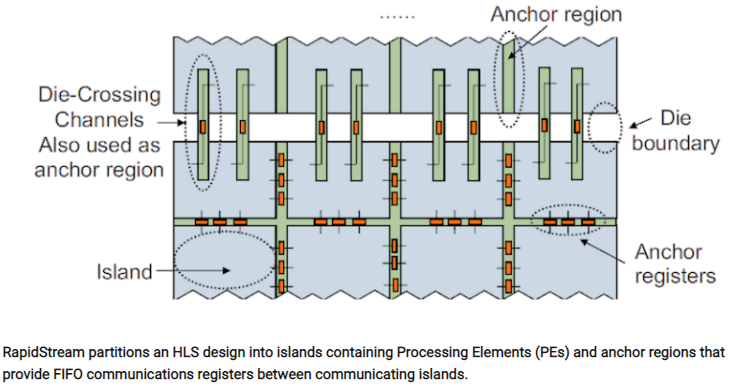
这篇论文由UCLA、AMD-Xilinx、根特大学和康奈尔大学的研究团队撰写,描述了RapidStream自动分区算法,将数据流设计分割成多个“island”,在划分的island之间插入“anchor regions”,然后通过anchor regions中的寄存器将每个island的信号连起来整合到整个设计中。
所有这些划分和拼接背后的目的是将HLS设计分割成小块,交付给现代服务器中的多个核心。这种策略已经有悠久的历史,现在被用于加速FPGA的开发。
这个过程有三个主要的HLS级约束:
1、非重叠分区——并行化不同island的物理实现;
2、流水线化的island间连接——每个island间连接都流水线化,以满足时序要求;
3、直接连接——每个island只能与相邻的island直接连接。当并行化设计布局布线时,这个约束是至关重要的。
(注意:这些约束与用于控制逻辑综合的各种约束完全不同,它处于一个更高的层次。)
RapidStream的开发者将数据流设计定义为一组并行处理元素(processing element,简称PE)和一组根据设计的数据流需求将PE连接起来的FIFO。PE内部可以很复杂,但只能通过FIFO接口与其他PE进行数据通信。
如上所述,RapidStream将FPGA fabric划分为两种region:大小相同的region和在相邻region之间以窄列和行放置的anchor region。有趣的是,RapidStream似乎是专门为AMD-Xilinx Virtex UltraScale+ FPGA构建的,这是由FPGAchiplet(AMD-Xilinx语言中的超级逻辑区域,简称SLR)制成的2.5D器件。
这篇论文包含了几个描述RapidStream工作性能的图表。下图显示了在分区后,六种不同的数据流设计与没有分区的流水线/非流水线版本时钟速率的比较。
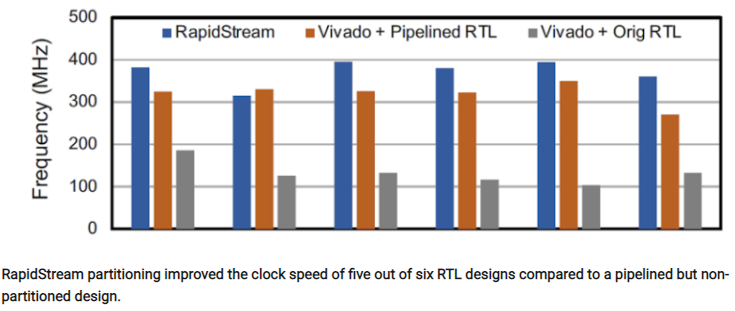
从上图可以看出,RapidStream比所有非流水线版本的时钟速率更高。这是意料之中的,因为流水线是FPGA时钟速度改进的核心。然而,六种情况中,有五种情况RapidStream的结果比相同设计的流水线RTL版本要好,这个结果要引起我们的注意。
下面是布局布线的时间结果对比:
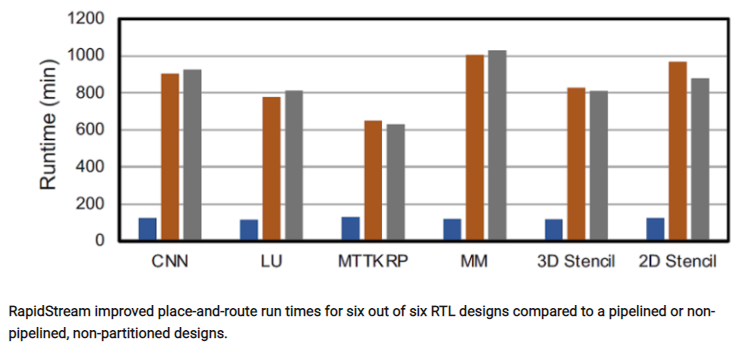
RapidStream的布局布线运行时间比未分区设计的结果要好得多。这是因为RapidStream可以将每个分区送给不同的处理器核心来布局布线。
虽然FPGA供应商试图让布局布线算法在多核处理器上工作得更快,但RapidStream的开发人员根据经验发现,如果FPGA设计没有分区,在超过两个处理器核心上运行AMD-Xilinx Vivado设计工具时并没有太大改善。
如果有读者正在用FPGA开发HLS设计——特别是AMD-Xilinx FPGA,那么应该会对RapidStream感兴趣。更细节的内容可以在GitHub上找到。
原文标题:HLS分区加速FPGA布局布线!
文章出处:【微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
FPGA
+关注
关注
1629文章
21729浏览量
602986 -
Xilinx
+关注
关注
71文章
2167浏览量
121303 -
布局布线
+关注
关注
1文章
88浏览量
15170 -
HLS
+关注
关注
1文章
129浏览量
24097
原文标题:HLS分区加速FPGA布局布线!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
助力AIoT应用:在米尔FPGA开发板上实现Tiny YOLO V4
如何在FPGA中实现按键消抖
优化 FPGA HLS 设计
FPGA在人工智能中的应用有哪些?
在多FPGA集群上实现高级并行编程
基于FPGA的图像采集与显示系统设计
一种在HLS中插入HDL代码的方式
请问如何使用fx3芯片来对FPGA进行并行配置?
基于FPGA的网络加速设计实现
# FPGA 编程如何工作?
为何高端FPGA都非常重视软件
fpga芯片的主要特点包括 fpga芯片上市公司
如何使用FPGA驱动并行ADC和并行DAC芯片?





 工商网监
工商网监
评论