 Linux内核中Netfilter的设计与实现
Linux内核中Netfilter的设计与实现
Netfilter (配合 iptables)使得用户空间应用程序可以注册内核网络栈在处理数据包时应用的处理规则,实现高效的网络转发和过滤。很多常见的主机防火墙程序以及 Kubernetes 的 Service 转发都是通过 iptables 来实现的。
关于 netfilter 的介绍文章大部分只描述了抽象的概念,实际上其内核代码的基本实现不算复杂,本文主要参考 Linux 内核 2.6 版本代码(早期版本较为简单),与最新的 5.x 版本在实现上可能有较大差异,但基本设计变化不大,不影响理解其原理。
本文假设读者已对 TCP/IP 协议有基本了解。
Netfilter 的设计与实现
netfilter 的定义是一个工作在 Linux 内核的网络数据包处理框架,为了彻底理解 netfilter 的工作方式,我们首先需要对数据包在 Linux 内核中的处理路径建立基本认识。
数据包的内核之旅
数据包在内核中的处理路径,也就是处理网络数据包的内核代码调用链,大体上也可按 TCP/IP 模型分为多个层级,以接收一个 IPv4 的 tcp 数据包为例:
-
在物理-网络设备层,网卡通过 DMA 将接收到的数据包写入内存中的ring buffer,经过一系列中断和调度后,操作系统内核调用 __skb_dequeue 将数据包加入对应设备的处理队列中,并转换成 sk_buffer 类型(即 socket buffer - 将在整个内核调用栈中持续作为参数传递的基础数据结构,下文指称的数据包都可以认为是 sk_buffer),最后调用 netif_receive_skb 函数按协议类型对数据包进行分类,并跳转到对应的处理函数。如下图所示:
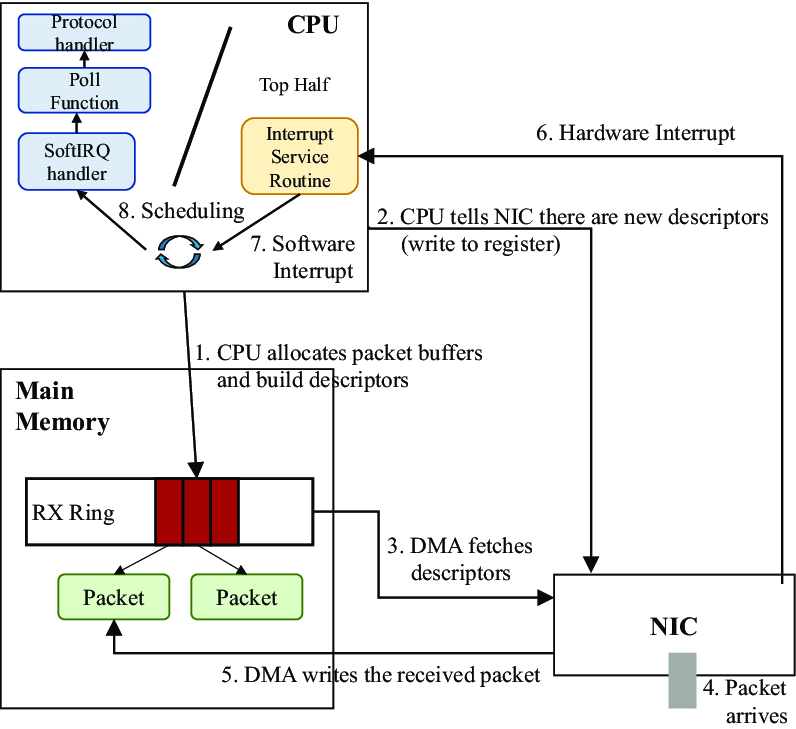
network-path
-
假设该数据包为 IP 协议包,对应的接收包处理函数ip_rcv将被调用,数据包处理进入网络(IP)层。ip_rcv检查数据包的 IP 首部并丢弃出错的包,必要时还会聚合被分片的 IP 包。然后执行ip_rcv_finish函数,对数据包进行路由查询并决定是将数据包交付本机还是转发其他主机。假设数据包的目的地址是本主机,接着执行的dst_input函数将调用ip_local_deliver函数。ip_local_deliver函数中将根据 IP 首部中的协议号判断载荷数据的协议类型,最后调用对应类型的包处理函数。本例中将调用 TCP 协议对应的tcp_v4_rcv函数,之后数据包处理进入传输层。
-
tcp_v4_rcv函数同样读取数据包的 TCP 首部并计算校验和,然后在数据包对应的 TCP control buffer 中维护一些必要状态包括 TCP 序列号以及 SACK 号等。该函数下一步将调用__tcp_v4_lookup查询数据包对应的 socket,如果没找到或 socket 的连接状态处于TCP_TIME_WAIT,数据包将被丢弃。如果 socket 处于未加锁状态,数据包将通过调用tcp_prequeue函数进入prequeue队列,之后数据包将可被用户态的用户程序所处理。传输层的处理流程超出本文讨论范围,实际上还要复杂很多。
netfilter hooks
接下来我们正式进入主题。netfilter 的首要组成部分是 netfilter hooks。
hook 触发点
对于不同的协议(IPv4、IPv6 或 ARP 等),Linux 内核网络栈会在该协议栈数据包处理路径上的预设位置触发对应的 hook。在不同协议处理流程中的触发点位置以及对应的 hook 名称(蓝色矩形外部的黑体字)如下,本文仅重点关注 IPv4 协议:
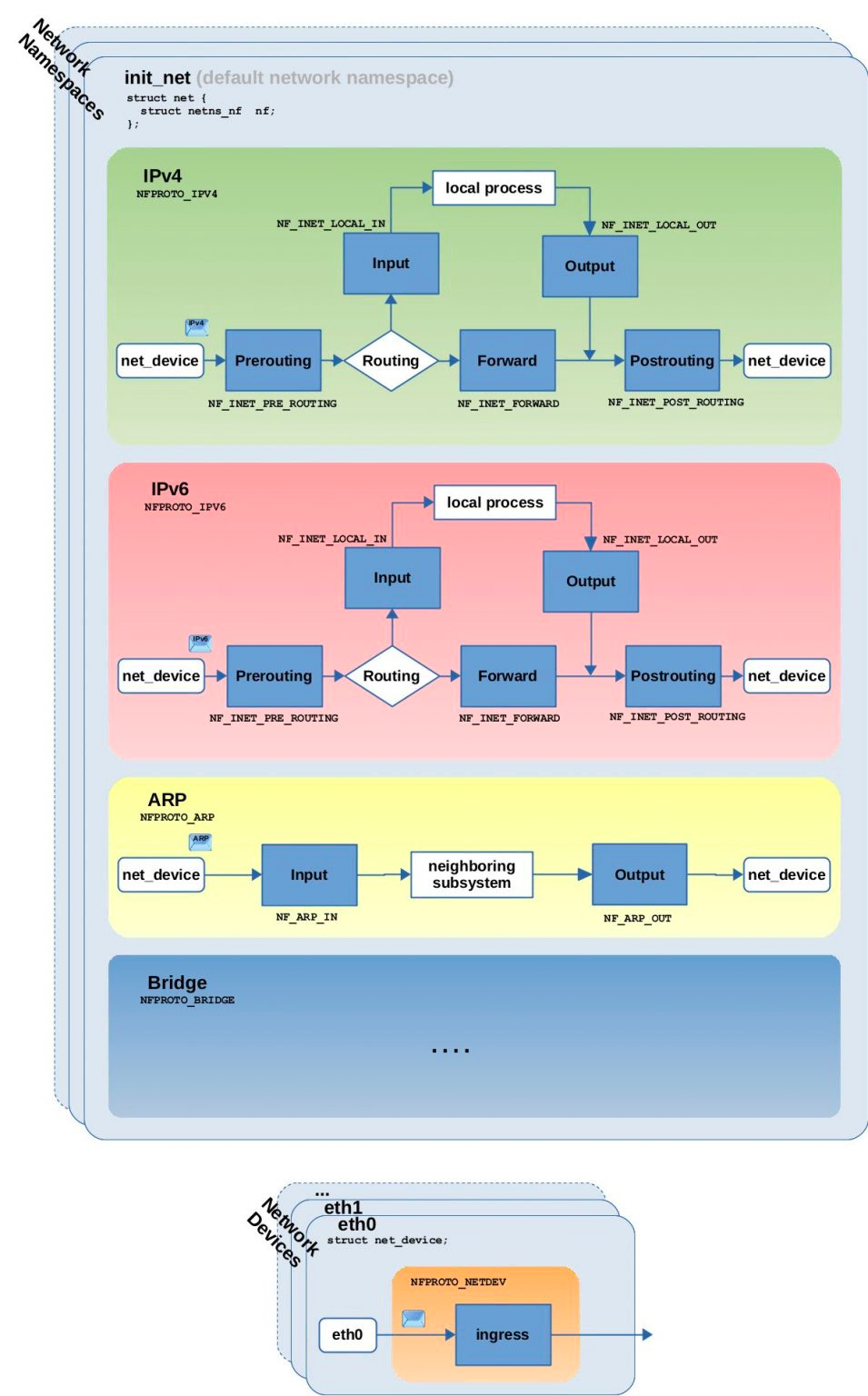
netfilter-flow
所谓的 hook 实质上是代码中的枚举对象(值为从 0 开始递增的整型):
enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS };
每个 hook 在内核网络栈中对应特定的触发点位置,以 IPv4 协议栈为例,有以下 netfilter hooks 定义:
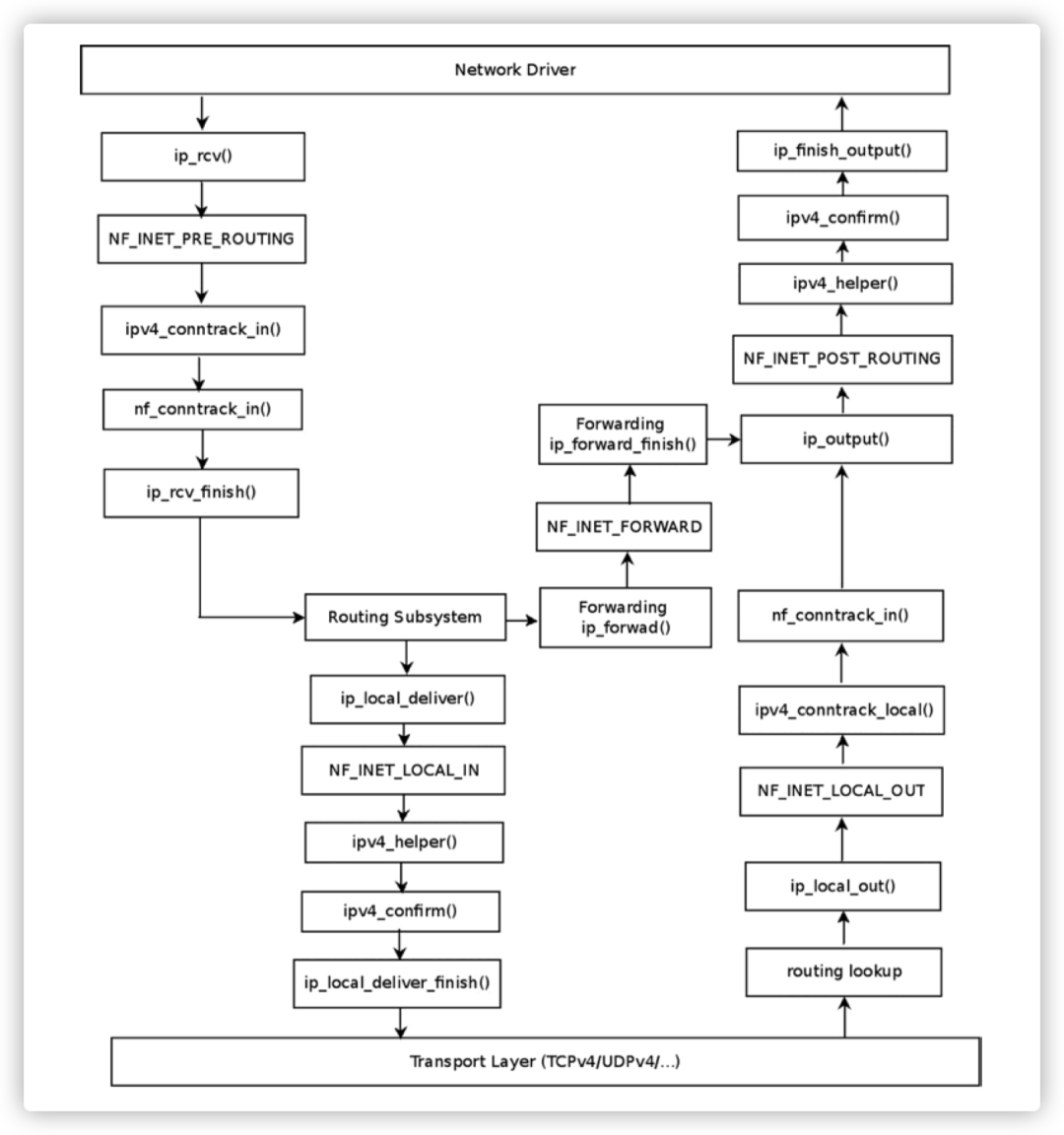
netfilter-hooks-stack
-
NF_INET_PRE_ROUTING: 这个 hook 在 IPv4 协议栈的ip_rcv 函数或 IPv6 协议栈的 ipv6_rcv 函数中执行。所有接收数据包到达的第一个 hook 触发点(实际上新版本 Linux 增加了 INGRESS hook 作为最早触发点),在进行路由判断之前执行。
-
NF_INET_LOCAL_IN: 这个 hook 在 IPv4 协议栈的ip_local_deliver() 函数或 IPv6 协议栈的 ip6_input() 函数中执行。经过路由判断后,所有目标地址是本机的接收数据包到达此 hook 触发点。
-
NF_INET_FORWARD: 这个 hook 在 IPv4 协议栈的ip_forward() 函数或 IPv6 协议栈的 ip6_forward() 函数中执行。经过路由判断后,所有目标地址不是本机的接收数据包到达此 hook 触发点。
-
NF_INET_LOCAL_OUT: 这个 hook 在 IPv4 协议栈的__ip_local_out() 函数或 IPv6 协议栈的 __ip6_local_out() 函数中执行。所有本机产生的准备发出的数据包,在进入网络栈后首先到达此 hook 触发点。
-
NF_INET_POST_ROUTING: 这个 hook 在 IPv4 协议栈的ip_output() 函数或 IPv6 协议栈的 ip6_finish_output2() 函数中执行。本机产生的准备发出的数据包或者转发的数据包,在经过路由判断之后, 将到达此 hook 触发点。
NF_HOOK 宏和 netfilter 向量
所有的触发点位置统一调用NF_HOOK这个宏来触发 hook:
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct sk_buff *)) { return NF_HOOK_THRESH(pf, hook, skb, in, out, okfn, INT_MIN); }
NF-HOOK接收的参数如下:
-
pf: 数据包的协议族,对 IPv4 来说是NFPROTO_IPV4。
-
hook: 上图中所示的 netfilter hook 枚举对象,如 NF_INET_PRE_ROUTING 或 NF_INET_LOCAL_OUT。
-
skb: SKB 对象,表示正在被处理的数据包。
-
in: 数据包的输入网络设备。
-
out: 数据包的输出网络设备。
-
okfn: 一个指向函数的指针,该函数将在该 hook 即将终止时调用,通常传入数据包处理路径上的下一个处理函数。
NF-HOOK的返回值是以下具有特定含义的 netfilter 向量之一:
-
NF_ACCEPT: 在处理路径上正常继续(实际上是在NF-HOOK中最后执行传入的okfn)。
-
NF_DROP: 丢弃数据包,终止处理。
-
NF_STOLEN: 数据包已转交,终止处理。
-
NF_QUEUE: 将数据包入队后供其他处理。
-
NF_REPEAT: 重新调用当前 hook。
回归到源码,IPv4 内核网络栈会在以下代码模块中调用NF_HOOK():
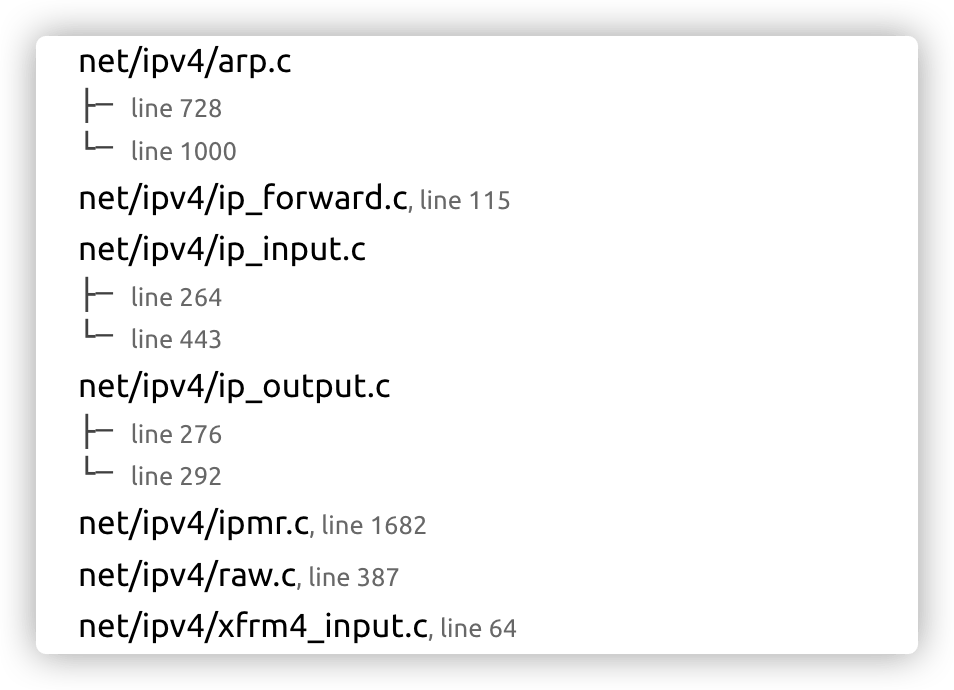
NF_HOOK
实际调用方式以`net/ipv4/ip_forward.c`[1] 对数据包进行转发的源码为例,在 ip_forward 函数结尾部分的第 115 行以 NF_INET_FORWARDhook 作为入参调用了 NF_HOOK 宏,并将网络栈接下来的处理函数 ip_forward_finish 作为 okfn 参数传入:
int ip_forward(struct sk_buff *skb) { .....(省略部分代码) if (rt->rt_flags&RTCF_DOREDIRECT && !opt->srr && !skb_sec_path(skb)) ip_rt_send_redirect(skb); skb->priority = rt_tos2priority(iph->tos); return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb->dev, rt->dst.dev, ip_forward_finish); .....(省略部分代码) }
回调函数与优先级
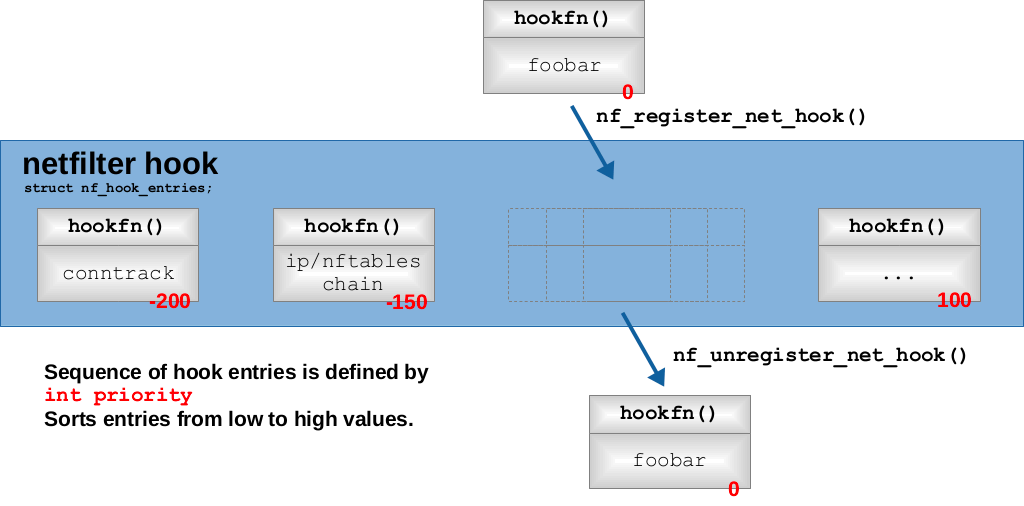
netfilter 的另一组成部分是 hook 的回调函数。内核网络栈既使用 hook 来代表特定触发位置,也使用 hook (的整数值)作为数据索引来访问触发点对应的回调函数。
内核的其他模块可以通过 netfilter 提供的 api 向指定的 hook 注册回调函数,同一 hook 可以注册多个回调函数,通过注册时指定的priority 参数可指定回调函数在执行时的优先级。
注册 hook 的回调函数时,首先需要定义一个 nf_hook_ops结构(或由多个该结构组成的数组),其定义如下:
struct nf_hook_ops { struct list_head list; /* User fills in from here down. */ nf_hookfn *hook; struct module *owner; u_int8_t pf; unsigned int hooknum; /* Hooks are ordered in ascending priority. */ int priority; };
在定义中有 3 个重要成员:
-
hook: 将要注册的回调函数,函数参数定义与NF_HOOK 类似,可通过 okfn参数嵌套其他函数。
-
hooknum: 注册的目标 hook 枚举值。
-
priority: 回调函数的优先级,较小的值优先执行。
定义结构体后可通过int nf_register_hook(struct nf_hook_ops *reg) 或 int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n); 分别注册一个或多个回调函数。同一 netfilter hook 下所有的nf_hook_ops 注册后以 priority 为顺序组成一个链表结构,注册过程会根据 priority 从链表中找到合适的位置,然后执行链表插入操作。
在执行 NF-HOOK 宏触发指定的 hook 时,将调用 nf_iterate 函数迭代这个 hook 对应的 nf_hook_ops 链表,并依次调用每一个 nf_hook_ops 的注册函数成员 hookfn。示意图如下:
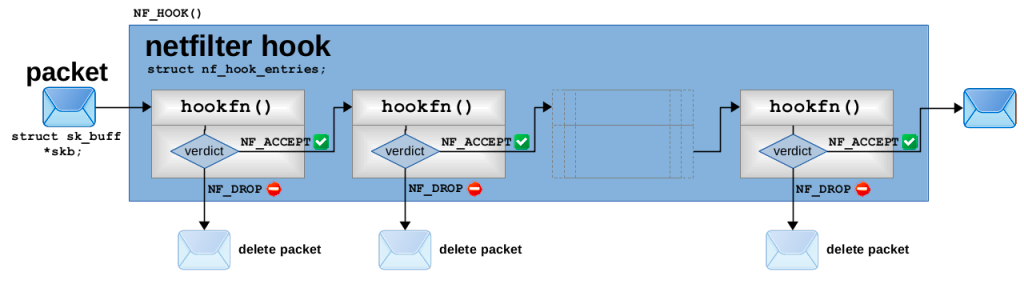
netfilter-hookfn1
这种链式调用回调函数的工作方式,也让 netfilter hook 被称为 Chain,下文的 iptables 介绍中尤其体现了这一关联。
每个回调函数也必须返回一个 netfilter 向量;如果该向量为NF_ACCEPT,nf_iterate 将会继续调用下一个 nf_hook_ops 的回调函数,直到所有回调函数调用完毕后返回 NF_ACCEPT;如果该向量为 NF_DROP,将中断遍历并直接返回 NF_DROP;**如果该向量为 **NF_REPEAT**,将重新执行该回调函数**。nf_iterate 的返回值也将作为 NF-HOOK 的返回值,网络栈将根据该向量值判断是否继续执行处理函数。示意图如下:
netfilter-hookfn2
netfilter hook 的回调函数机制具有以下特性:
-
回调函数按优先级依次执行,只有上一回调函数返回NF_ACCEPT 才会继续执行下一回调函数。
-
任一回调函数都可以中断该 hook 的回调函数执行链,同时要求整个网络栈中止对数据包的处理。
iptables
基于内核 netfilter 提供的 hook 回调函数机制,netfilter 作者 Rusty Russell 还开发了 iptables,实现在用户空间管理应用于数据包的自定义规则。
iptbles 分为两部分:
-
用户空间的 iptables 命令向用户提供访问内核 iptables 模块的管理界面。
-
内核空间的 iptables 模块在内存中维护规则表,实现表的创建及注册。
内核空间模块
xt_table 的初始化
在内核网络栈中,iptables 通过xt_table 结构对众多的数据包处理规则进行有序管理,一个 xt_table 对应一个规则表,对应的用户空间概念为 table。不同的规则表有以下特征:
-
对不同的 netfilter hooks 生效。
-
在同一 hook 中检查不同规则表的优先级不同。
基于规则的最终目的,iptables 默认初始化了 4 个不同的规则表,分别是 raw、 filter、nat 和 mangle。下文以 filter 为例介绍xt_table的初始化和调用过程。
filter table 的定义如下:
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | (1 << NF_INET_FORWARD) | (1 << NF_INET_LOCAL_OUT)) static const struct xt_table packet_filter = { .name = "filter", .valid_hooks = FILTER_VALID_HOOKS, .me = THIS_MODULE, .af = NFPROTO_IPV4, .priority = NF_IP_PRI_FILTER, }; (net/ipv4/netfilter/iptable_filter.c)
在iptable_filter.c[2] 模块的初始化函数 [iptable_filter_init](https://elixir.bootlin.com/linux/v2.6.39.4/C/ident/iptable_filter_init "iptable_filter_init") ****中,调用xt_hook_link 对 xt_table 结构 packet_filter 执行如下初始化过程:
-
通过 .valid_hooks 属性迭代 xt_table 将生效的每一个 hook,对于 filter 来说是 NF_INET_LOCAL_IN,NF_INET_FORWARD 和 NF_INET_LOCAL_OUT这 3 个 hook。
-
对每一个 hook,使用 xt_table 的 priority 属性向 hook 注册一个回调函数。
不同 table 的 priority 值如下:
enum nf_ip_hook_priorities { NF_IP_PRI_RAW = -300, NF_IP_PRI_MANGLE = -150, NF_IP_PRI_NAT_DST = -100, NF_IP_PRI_FILTER = 0, NF_IP_PRI_SECURITY = 50, NF_IP_PRI_NAT_SRC = 100, };
当数据包到达某一 hook 触发点时,会依次执行不同 table 在该 hook 上注册的所有回调函数,这些回调函数总是根据上文的 priority 值以固定的相对顺序执行:
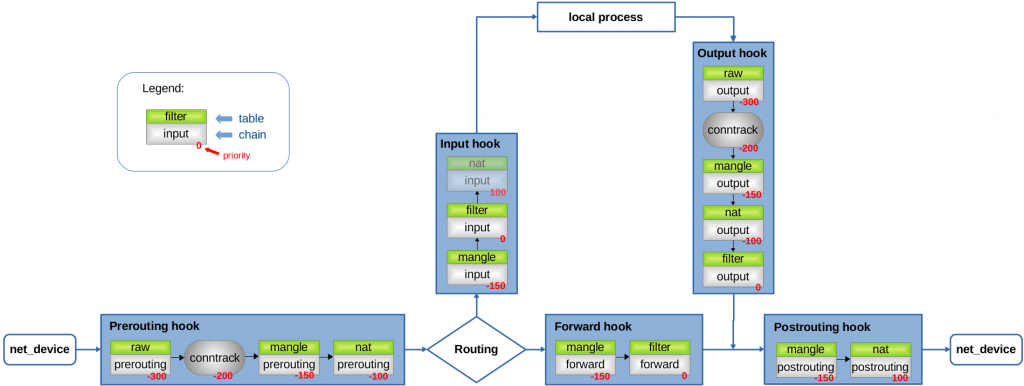
tables-priority
ipt_do_table()
filter 注册的 hook 回调函数 iptable_filter_hook[3] 将对 xt_table 结构执行公共的规则检查函数 ipt_do_table[4]。ipt_do_table 接收 skb、hook 和 xt_table作为参数,对 skb 执行后两个参数所确定的规则集,返回 netfilter 向量作为回调函数的返回值。
在深入规则执行过程前,需要先了解规则集如何在内存中表示。每一条规则由 3 部分组成:
-
一个 ipt_entry 结构体。通过 .next_offset 指向下一个 ipt_entry 的内存偏移地址。
-
0 个或多个 ipt_entry_match 结构体,每个结构体可以动态的添加额外数据。
-
1 个 ipt_entry_target 结构体, 结构体可以动态的添加额外数据。
ipt_entry 结构体定义如下:
struct ipt_entry { struct ipt_ip ip; unsigned int nfcache; /* ipt_entry + matches 在内存中的大小*/ u_int16_t target_offset; /* ipt_entry + matches + target 在内存中的大小 */ u_int16_t next_offset; /* 跳转后指向前一规则 */ unsigned int comefrom; /* 数据包计数器 */ struct xt_counters counters; /* 长度为0数组的特殊用法,作为 match 的内存地址 */ unsigned char elems[0]; };
ipt_do_table 首先根据 hook 类型以及 xt_table.private.entries属性跳转到对应的规则集内存区域,执行如下过程:
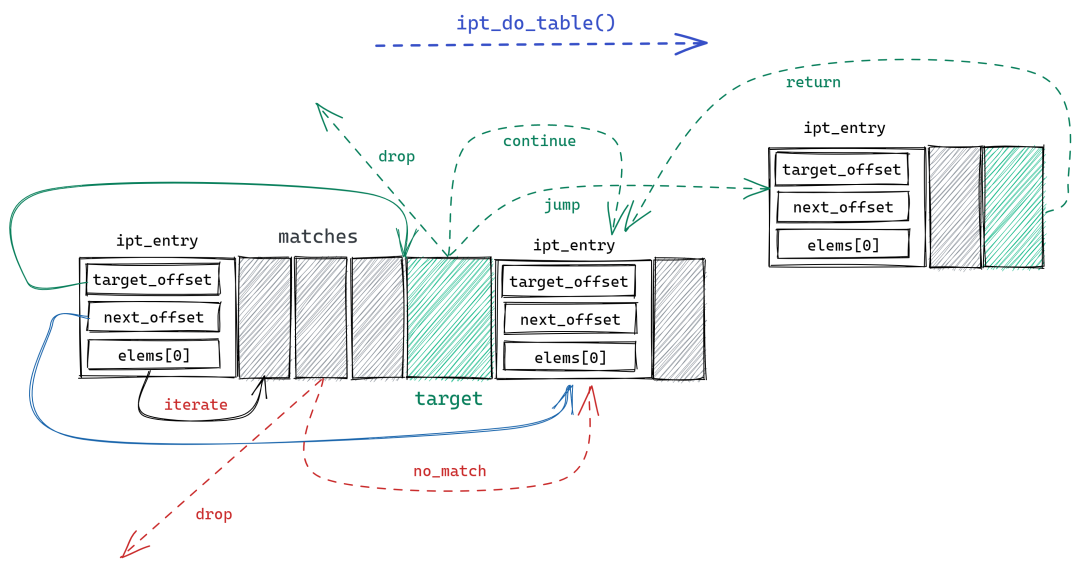
ipt_do_table
-
首先检查数据包的 IP 首部与第一条规则 ipt_entry 的 .ipt_ip 属性是否一致,如不匹配根据 next_offset 属性跳转到下一条规则。
-
若 IP 首部匹配 ,则开始依次检查该规则所定义的所有 ipt_entry_match 对象,与对象关联的匹配函数将被调用,根据调用返回值有返回到回调函数(以及是否丢弃数据包)、跳转到下一规则或继续检查等结果。
-
所有检查通过后读取 ipt_entry_target,根据其属性返回 netfilter 向量到回调函数、继续下一规则或跳转到指定内存地址的其他规则,非标准 ipt_entry_target 还会调用被绑定的函数,但只能返回向量值不能跳转其他规则。
灵活性和更新时延
以上数据结构与执行方式为 iptables 提供了强大的扩展能力,我们可以灵活地自定义每条规则的匹配条件并根据结果执行不同行为,甚至还能在额外的规则集之间栈式跳转。
由于每条规则长度不等、内部结构复杂,且同一规则集位于连续的内存空间,iptables 使用全量替换的方式来更新规则,这使得我们能够从用户空间以原子操作来添加/删除规则,但非增量式的规则更新会在规则数量级较大时带来严重的性能问题:假如在一个大规模 Kubernetes 集群中使用 iptables 方式实现 Service,当 service 数量较多时,哪怕更新一个 service 也会整体修改 iptables 规则表。全量提交的过程会 kernel lock 进行保护,因此会有很大的更新时延。
用户空间的 tables、chains 和 rules
用户空间的 iptables 命令行可以读取指定表的数据并渲染到终端,添加新的规则(实际上是替换整个 table 的规则表)等。
iptables 主要操作以下几种对象:
-
table:对应内核空间的 xt_table 结构,iptable 的所有操作都对指定的 table 执行,默认为 filter。
-
chain:对应指定 table 通过特定 netfilter hook 调用的规则集,此外还可以自定义规则集,然后从 hook 规则集中跳转过去。
-
rule:对应上文中 ipt_entry、ipt_entry_match 和ipt_entry_target,定义了对数据包的匹配规则以及匹配后执行的行为。
-
match:具有很强扩展性的自定义匹配规则。
-
target:具有很强扩展性的自定义匹配后行为。
基于上文介绍的代码调用过程流程,chain 和 rule 按如下示意图执行:
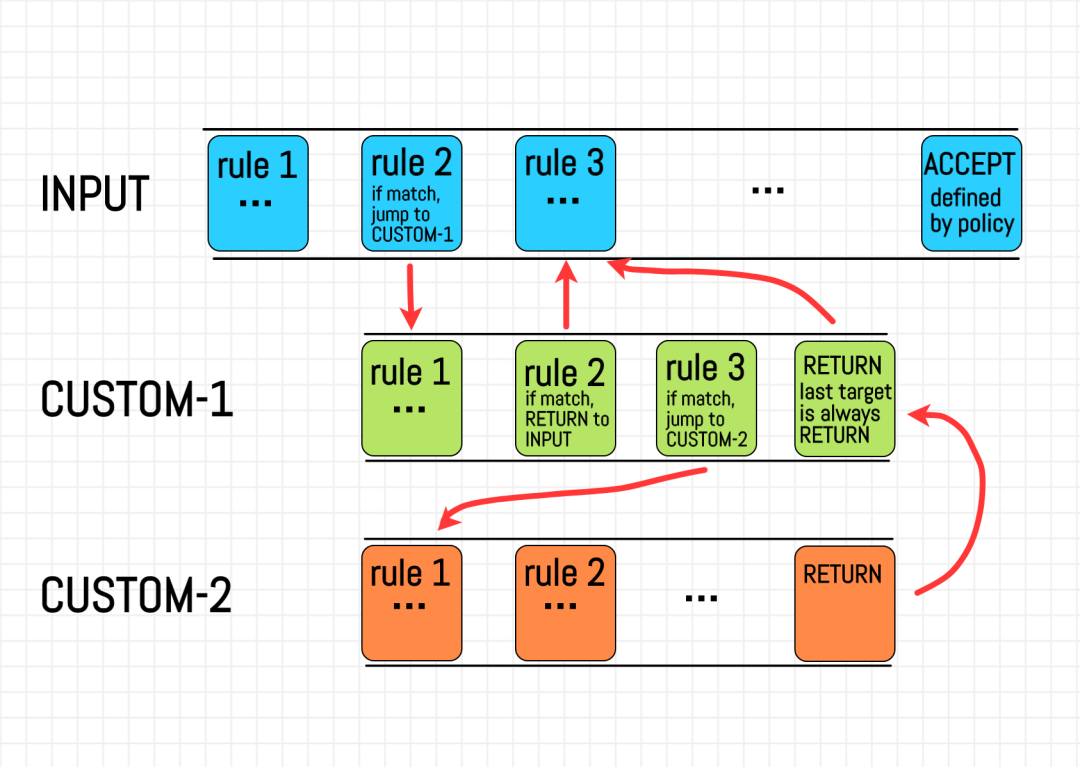
iptables-chains
对于 iptables 具体的用法和指令本文不做详细介绍。
conntrack
仅仅通过 3、4 层的首部信息对数据包进行过滤是不够的,有时候还需要进一步考虑连接的状态。netfilter 通过另一内置模块conntrack进行连接跟踪(connection tracking),以提供根据连接过滤、地址转换(NAT)等更进阶的网络过滤功能。由于需要对连接状态进行判断,conntrack在整体机制相同的基础上,又针对协议特点有单独的实现。
原文标题:深入理解 netfilter 和 iptables
文章出处:【微信公众号:一口Linux】欢迎添加关注!文章转载请注明出处。
-
Linux
+关注
关注
87文章
11292浏览量
209316 -
数据包
+关注
关注
0文章
260浏览量
24384 -
netfilter
+关注
关注
0文章
6浏览量
7190
原文标题:深入理解 netfilter 和 iptables
文章出处:【微信号:yikoulinux,微信公众号:一口Linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何去实现netfilter呢
如何解决编译内核报错的问题?
netfilter技术分析及在入侵响应中的应用
Linux新型内核防火墙研究和应用
基于Netfilter的NAT技术及其应用
基于Netfilter内核态网络流量分析研究
netfilter技术分析
什么是netfilter?netfilter是什么意思?
Iptables移植到嵌入式Linux系统

Linux 6.2内核合并了新的Zstd实现

Netfilter 的设计与实现





 工商网监
工商网监
评论