 Python pacp模块:自动识别文字中的省市区并将其绘图
Python pacp模块:自动识别文字中的省市区并将其绘图
一个用于提取简体中文字符串中省,市和区并能够进行映射,检验和简单绘图的python模块。
举个例子:
["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
↓ 转换
|省 |市 |区 |地址 |
|上海市|上海市|徐汇区|虹漕路461号58号楼5楼 |
|福建省|泉州市|洛江区|万安塘西工业区 |
注:“地址”列代表去除了省市区之后的具体地址
也可以将大段文本中所有提到的地址提取出来,并且自动将相邻的存在所属关系的地址归并到一条记录中(0.5.5版本新功能):
"分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区"
↓ 转换
|省 |市 |区 |
|上海市|上海市|徐汇区|
|福建省|泉州市|洛江区|
|江苏省|南京市|鼓楼区|
代码目前仅仅支持python3
pip install cpca
注:cpca是chinese province city area的缩写
如果觉得本模块对你有用的话,施舍个star,谢谢。
常见安装问题:
在 windows 上可能会出现类似如下问题
Building wheel for pyahocorasick (setup.py) ... error
先去下载 Microsoft Visual C++ Build Tools, 安装完成后,再重新使用 pip install cpca 安装,即可解决问题
开始使用
本模块中最主要的方法是cpca.transform,该方法可以输入任意的可迭代类型(如list,pandas的Series类型等),然后将其转换为一个DataFrame,下面演示一个最为简单的使用方法:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "北京朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str)
df
输出的结果为(adcode为官方地址编码):
省 市 区 地址 adcode
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 310104
1 福建省 泉州市 洛江区 万安塘西工业区 350504
2 北京市 市辖区 朝阳区 北苑华贸城 110105
如果你想获知程序是从字符串的那个位置提取出省市区名的,可以添加一个pos_sensitive=True参数:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "北京朝阳区北苑华贸城"]
import cpca
df = cpca.transform(location_str, pos_sensitive=True)
df
输出如下:
省 市 区 地址 adcode 省_pos 市_pos 区_pos
0 上海市 上海市 徐汇区 虹漕路461号58号楼5楼 310104 -1 -1 0
1 福建省 泉州市 洛江区 万安塘西工业区 350504 -1 0 3
2 北京市 市辖区 朝阳区 北苑华贸城 110105 -1 -1 0
从大段文本中提取多个地址(0.5.5版本新功能):
import cpca
df = cpca.transform_text_with_addrs("分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区")
df
结果为(注意 transform_text_with_addrs 获得的数据,“地址”列都是空的):
省 市 区 地址 adcode
0 上海市 市辖区 徐汇区 310104
1 福建省 泉州市 洛江区 350504
2 江苏省 南京市 鼓楼区 320106
transform_text_with_addrs 还支持和 transform 类似的 index, pos_sensitive 以及 umap 参数
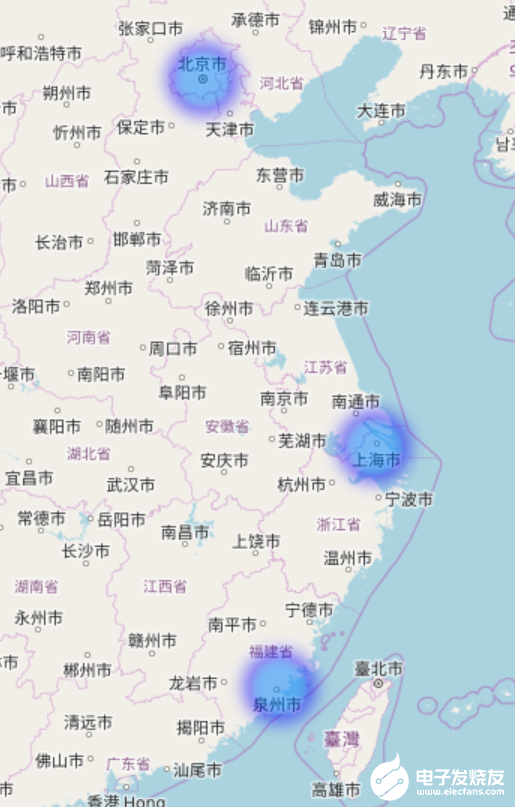
绘图:
模块中还自带一些简单绘图工具,可以在地图上将上面输出的数据以热力图的形式画出来.
这个工具依赖folium,为了减小本模块的体积,所以并不会预装这个依赖,在使用之前请使用pip install folium .
代码如下:
import cpca
from cpca import drawer
df = cpca.transform_text_with_addrs("分店位于徐汇区虹漕路461号58号楼5楼和泉州市洛江区万安塘西工业区以及南京鼓楼区")
drawer.draw_locations(df[cpca._ADCODE], "df.html")
审核编辑 黄昊宇
-
自动识别
+关注
关注
3文章
221浏览量
22831 -
python
+关注
关注
56文章
4792浏览量
84627
发布评论请先 登录
相关推荐
垃圾短信?手机自动识别垃圾短信逻辑的分析

客流统计自动识别摄像头

中国物品编码中心一行莅临新大陆自动识别参观调研
MCU串口自动识别波特率原理分析
PCM9211的默认模式下,ADC和RXIN2( 光纤输入)是自动识别的吗,并且光纤具有输入优先级?
智能化升级:机载无人机摄像头如何自动识别目标?

光学识别字符是自动识别技术吗
水位自动识别摄像机

多光谱明火自动识别摄像机

RFID军标单装自动识别铭牌 - 提升效率首选
自动识别水位预警摄像机

通道堵塞自动识别摄像机

护目镜佩戴自动识别预警摄像机






 工商网监
工商网监
评论