 掌握多核编程和调试的挑战
掌握多核编程和调试的挑战
在本文中,我们将讨论多核处理的各个方面,包括了解不同类型的多核处理器以及为什么这些设备在今天变得普遍和流行。然后,我们将研究在芯片上拥有多个内核所带来的一些挑战,以及现代多核感知调试器如何帮助使这些复杂任务更易于管理。
系统性能
有许多方法可以提高嵌入式计算系统的性能,从巧妙的编译器算法到高效的硬件解决方案。编译器优化对于从易于阅读和理解的高级语言代码中获得最有效的指令调度非常重要。除此之外,系统可以利用项目中可用的并行性来一次处理多个事情。当然,缩放时钟频率可能是从计算系统中获得更高性能的有效方法。
不幸的是,可以假设时钟速度呈几何级数增长的时代已经过去。而代码优化只能给你带来这么多的改进,尤其是现在,经过多代编译器技术的发展。这让我们将并行性视为随着时间的推移继续扩展我们的系统性能的最佳机会。
并行性
挖井是一项难以并行化的任务。其他人可以帮忙,把泥土铲走,但实际挖洞通常是一个人的工作。结果,增加更多的人不会更快地完成工作。事实上,其他人可能只是妨碍并减慢进程。有些任务不适合并行化。
其他任务很容易并行化。挖沟是一项适合并行化的任务。许多人可以并肩工作。
这张图片显示了一种称为 MIMD(多指令多数据)的并行形式。每个挖掘机都是一个独立的单元,可以执行不同的任务。在这种情况下,您可以想象四台挖掘机完成工作的时间大约是一台挖掘机的1/4 。
使用 SIMD(单指令多数据),单个挖掘机可能会使用像这样的铲子。
SIMD 单元一次只能执行一种类型的计算,但它可以并行执行多条数据。这些类型的指令在许多处理器的向量处理单元中很常见。如果您的数据非常规则,并且您需要对大型数据集(例如在图像处理中)反复执行相同的操作,这将非常有用。然而,对于更一般的计算任务,该模型缺乏灵活性并且不会产生性能提升。
这导致我们选择将多个完整的 CPU 子系统放在一个芯片上,从而创建多核处理器。一个芯片上的多个内核可以扩展性能。每个内核都是一个完整的 CPU,可以独立工作或与其他内核协同工作。
不同类型的多核处理
处理器芯片上可能有不同类型的内核组合,以及工作在它们之间的分配方式。
同构多核处理器具有相同处理器内核的两个或多个副本。每个核心都自主运行,并且可以通过共享内存或邮箱系统等多种机制与其他核心进行通信和同步。每个处理器都有自己的寄存器和功能单元,并且可能有自己的本地内存或缓存。然而,使这种同质化的原因在于我们正在查看的所有内核都是同一类型的。
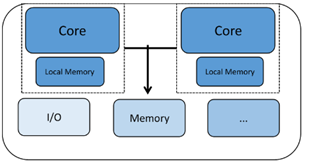
另一种类型的多核芯片称为异构多核,具有两种或多种不同类型的 CPU 内核。这里的内核可能具有非常不同的特性,这使得它们非常适合系统处理需求的不同部分。一个例子可能是蓝牙通信芯片,其中一个内核专用于管理蓝牙协议栈,而另一个内核可能管理外部通信、应用程序处理、人机界面等。这种多核芯片可用于需要两者的应用程序一个核心的实时专用性能和另一个核心的系统管理功能。
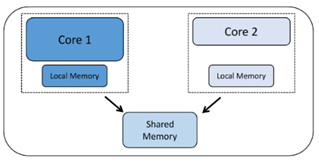
现在我们来看看核心是如何使用的。当您拥有多个内核并且这些内核运行相同的项目代码库时,就会发生对称多处理 (SMP)。不同的内核可能同时运行代码的不同部分,但代码是作为单个项目构建的,并由一些控制程序(如实时操作系统 (RTOS))分派到不同的内核。必要时,以这种方式工作的内核必须属于同一类型,因为它们都使用为一种类型的处理器编译的相同项目代码。
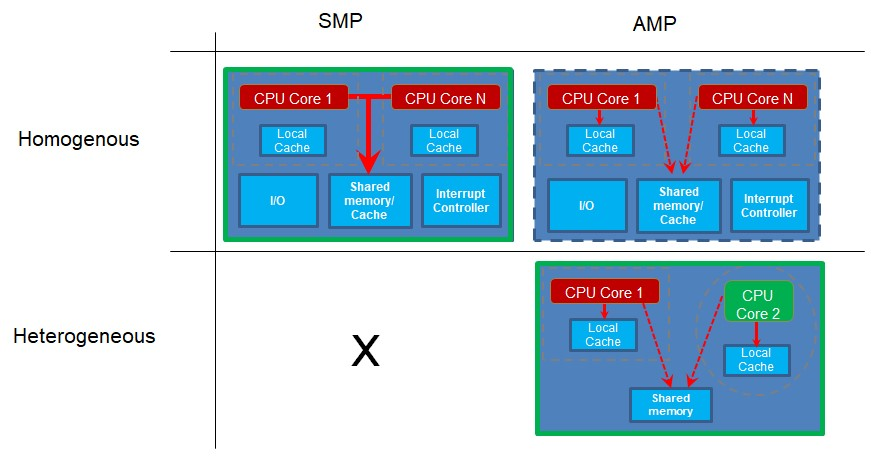
当您拥有多个内核或处理器并且每个处理器都运行自己的项目应用程序时,就会发生非对称多处理 (AMP)。独立的核心可能会不时同步或通信,但它们每个都有自己执行的代码库。由于他们每个人都在运行自己的项目,因此这些内核可以是不同类型的,也可以是异构内核。但是,这不是必需的。如果两个或多个相同类型的内核运行不同的项目代码,则它们是同质内核,运行 AMP。
请注意,对于 SMP 操作,您必须拥有多个同质内核,因为它们都运行来自同一个项目代码库的代码。但是,如果您有多个项目具有不同的代码库以运行不同的内核,则这些项目可能是不同的内核,例如在异构系统中。但是,如果内核相同,那也可以。
使用多核的原因
在过去的几年里,在 1960 年代中期创造的摩尔定律似乎终于失去了动力,或者至少正在放缓。处理器时钟频率不再每 2-3 年翻一番,事实上,最高速度的 CPU 多年来一直在低个位数 GHz 范围内达到上限。
继续推动性能极限的一种方法是让更多 CPU 内核协同工作,前提是您可以有效地使用它们。
虽然速度已经趋于稳定,但晶体管尺寸却在继续缩小。虽然速度比过去慢,但小型晶体管可以在单个芯片上封装更多逻辑。因此,使用这些晶体管将多个 CPU 内核放在一个芯片上可以利用多个 CPU 和内存子系统之间更快、更宽的总线互连。
异构非对称多处理在应用程序具有两个或多个具有非常不同的特征和要求的工作负载时非常有用。一种可能依赖于实时和中断延迟,而另一种可能更依赖于吞吐量而不是响应时间。该模型运行良好:例如,设备可能专用一个内核来管理蓝牙或 Zigbee 等通信协议栈,而另一个内核则充当运行人类交互和整体系统管理操作的应用处理器。隔离的通信处理器可以提供协议栈所需的出色实时响应。此外,通信软件可以通过标准认证,通过将功能修改与系统的这一部分分开,使整个产品易于认证。
使用多核的挑战
当您在一个芯片上放置多个 CPU 内核时会带来哪些挑战?好吧,让我们深入研究一下。
单一应用程序或软件可能无法有效地使用可用的计算资源。您需要将应用程序组织成可以同时运行的并行任务,以使用多个内核的资源。这可能需要软件工程师以一种不熟悉的方式来考虑嵌入式设计。迁移现有的单循环代码可能不是很容易。线程太少甚至线程太多都可能成为性能障碍。
在多个线程或进程之间共享数据结构或 I/O 设备的应用程序可能存在串行瓶颈。为了维护数据完整性,对这些共享资源的访问可能必须使用锁定技术进行序列化,例如,读锁、读写锁、写锁、自旋锁、互斥锁等。由于多个线程或试图获取锁以使用共享资源的进程之间的高锁争用,设计低效的锁可能会造成瓶颈。这可能会降低应用程序或软件的性能。如果某些内核停止等待其他内核等待公共锁导致两个内核的性能比一个差,则应用程序的性能甚至会随着内核或处理器数量的增加而降低。
不均匀分布的工作负载在利用计算资源方面可能效率低下。您可能必须将大型任务分解为可以并行运行的较小任务。您可能必须将串行算法更改为并行算法以提高性能和可扩展性。但是,如果一些任务运行得非常快,而另一些任务需要大量时间,则快速任务可能会花费大量时间等待长任务完成。这会导致宝贵的计算资源闲置和性能扩展不佳。
RTOS 可能会帮助您,但可能无法解决所有问题。在 SMP 系统中,这实际上是在多个类似内核上调度任务的必要条件。要做的工作可以按数据或按功能划分。如果您按数据块划分事物,则每个线程可能会执行处理管道中的所有步骤。或者,您可能让一个线程在函数中执行一个步骤,而另一个线程执行下一步,等等。一种技术相对于另一种技术的优势将取决于要完成的工作的特征。
在多核环境中调试
调试多核系统时有用的第一件事是所有内核的可见性。理想情况下,我们应该能够同时或单独启动和停止核心——也就是说,在其他核心运行或停止时单步执行一个核心。多核断点对于根据另一个核的状态来控制一个核的操作非常有用。
多核跟踪可能很难实现。管理来自多个内核的高带宽跟踪信息,以及处理来自不同类型内核的潜在不同类型的跟踪数据是一个真正的挑战。
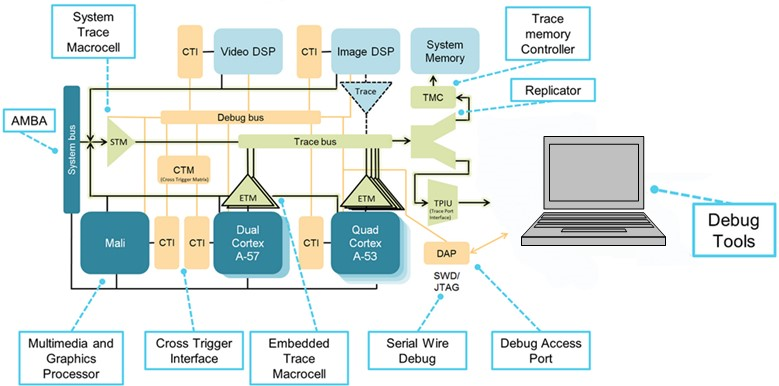
(来源:IAR Systems,图表由 Arm Ltd. 提供)
Here is an example of a processor with both heterogeneous and homogeneous multicore implementations. There are two homogeneous core groups, one based on a dual Arm Cortex-A57 and the other on a quad Cortex-A53. These groups are homogeneous within themselves but heterogeneous among the two groups.
CoreSight 调试架构提供了与所有内核上的调试资源进行通信的协议和机制,调试器负责管理所有这些信息并解析来自不同内核的消息。交叉触发接口和矩阵(CTI、CTM)允许同时停止两个内核、触发跟踪等。跟踪基础设施包括用于平滑跟踪流的串行 (SWD) 和并行 (TPIU) 跟踪端口,以及将来自每个源的跟踪合并为单个流的跟踪漏斗。与双核部分相比,图中所示的芯片控制起来要复杂得多。
IAR Embedded Workbench 中的 C-SPY 调试器支持对称和非对称多核调试。这是通过多核选项卡上的调试器选项启用的。要启用对称多核调试,只需要输入内核数量,让调试器知道要与多少个不同的处理器通信。其他 IDE 可能有类似的可用选项。
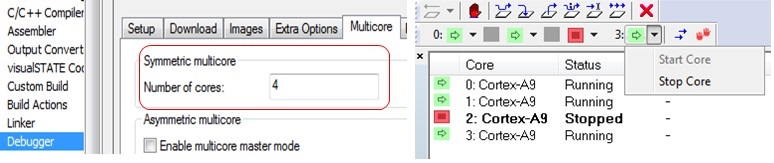
在右侧(上图),您可以在调试器中看到一个视图,其中 4 核 Cortex-A9 SMP 集群显示其内核状态,其中 2 号内核停止,而其他三个内核正在执行。
非对称多核系统可能使用异构多核部分,例如 ST STM32H745/755,它具有一个 Cortex-M7 内核和一个单独的 Cortex-M4。在这种情况下,当调试器运行时,它会使用 IDE 的两个实例(Master 和 Node)。每个核心一个,因为两个核心运行不同的项目代码。
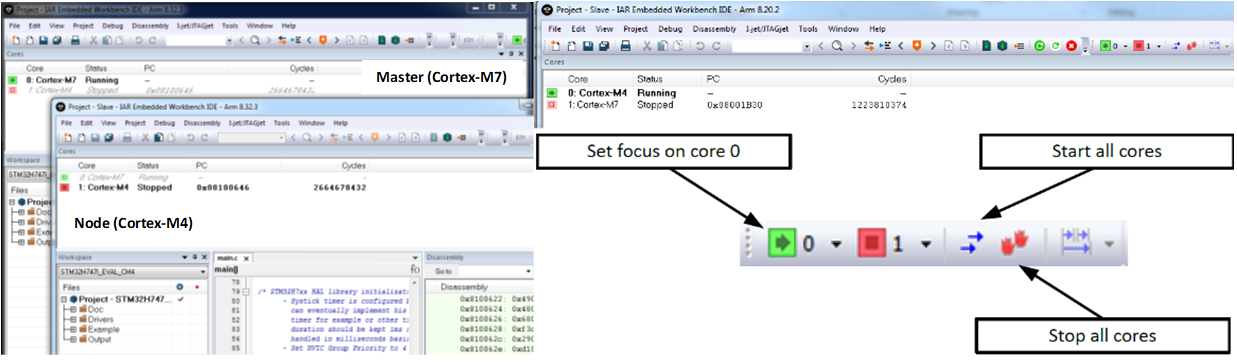
在 IDE 的每个实例中,都有关于正在控制的核心以及在另一个窗口中控制的另一个核心的状态信息。可以选择一些选项来控制调试器的行为,以便一起或单独启动和停止内核在开发人员的控制之下。
由于交叉触发接口 (CTI) 和交叉触发矩阵 (CTM) 共同构成了 Arm 嵌入式交叉触发功能,因此这种完全控制成为可能。共有三个 CTI 组件,一个在系统级,一个专用于 Cortex-M7,一个专用于 Cortex-M4。三个 CTI 通过 CTM 相互连接,如下图所示。调试器可以通过系统访问端口和相关的 APB-D 访问系统级和 Cortex-M4 CTI。Cortex-M7 CTI 物理集成在 Cortex-M7 内核中,可通过 Cortex-M7 访问端口访问。
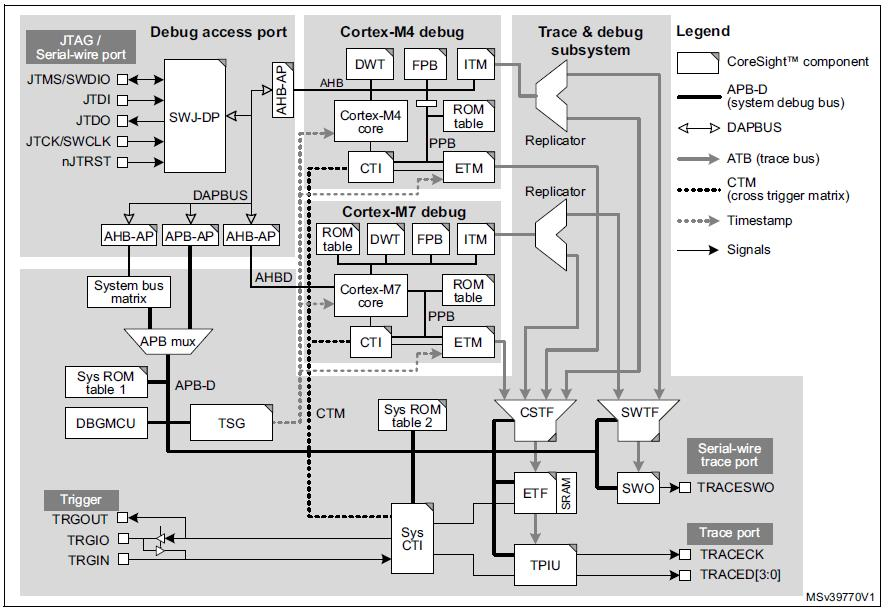
(来源:IAR Systems,图表由 STMicroelectronics 提供,来自 M0399 参考手册)
CTI 允许来自各种来源的事件触发调试和跟踪活动。例如,在一个处理器内核中达到的断点可以停止另一个处理器,或者可以将在外部触发输入上检测到的转换设置为开始代码跟踪。
在此示例中,异构多核处理器在单个芯片上具有 Cortex-M7 内核和 Cortex-M4 内核,使用了两个独立的程序:一个在 Cortex-M4 上运行,另一个在 Cortex-M7 上运行。每个项目都使用 FreeRTOS 来管理处理器上运行的软件。两个内核通过共享内存接口进行通信。但是,应用程序都使用 FreeRTOS 消息传递机制与其他处理器进行通信,并隐藏了底层机制的复杂性。因此,从一个 CPU 的角度来看,它只是通过另一个任务发送或接收消息。另一个任务恰好在另一个 CPU 内核上运行是透明的。
下图是 IDE 中的 Workspace explorer 寡妇。此处显示了两个项目的概述,因此您可以查看 Cortex-M7 和 Cortex-M4 项目的内容。
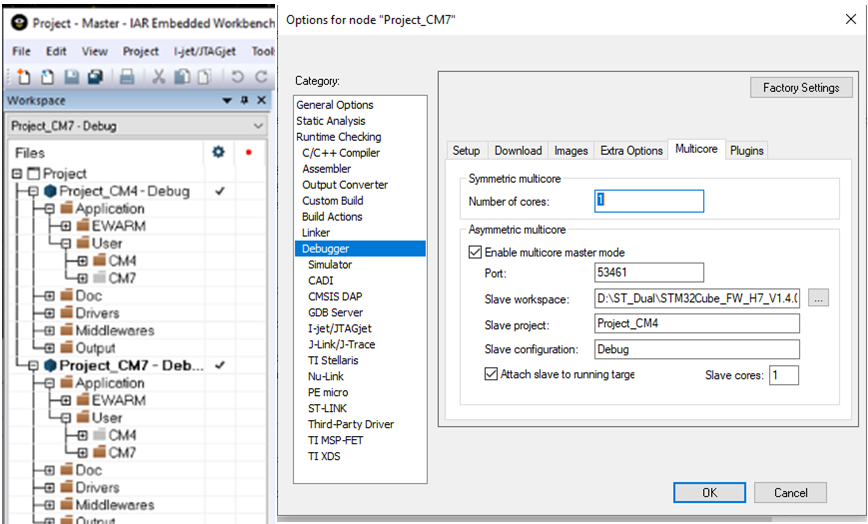
通过选择窗口底部的其他选项卡之一,您可以将焦点切换到 M4 项目或 M7 项目。
Cortex-M7 项目有一个任务,它向 Cortex-M4 上运行的任务发送消息。Cortex-M4 有两个正在运行的接收任务实例。Cortex-M7 有一个“检查”任务,它会定期运行以查看事情是否仍在正常运行。
最后,调试器加载这两个项目。这意味着为第二个调试器启动了一个额外的 Embedded Workbench 实例。
要为非对称多处理支持设置调试器,我们需要将一个项目指定为“主”项目,将另一个项目指定为“节点”项目。事实上,选择是任意的,只决定了哪个项目有能力在启动时启动另一个。
“节点”项目没有特殊设置,并且不知道它正在作为另一个项目的“节点”运行。
这样,当“主”项目启动其调试器时,它会自动启动 IDE 的另一个实例以适应第二个调试器会话,第二个项目将在其中运行。
概括
当摩尔定律用完时,多核可以提高性能。然而,多核带来了调试挑战,并且需要特定的开发方法,以便应用程序可以最大限度地利用多核架构。
配置调试设置后,多核调试从未如此简单。如果您以前使用过调试单核的工具,您将认识到其中包含的所有内容,并且您可能永远不会理解其他人谈论多核调试对他们来说有多困难。
现代硬件和软件工具将帮助您克服多核调试挑战。
注意:除非另有说明,否则图片均由 IAR Systems 提供。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19259浏览量
229650 -
芯片
+关注
关注
455文章
50714浏览量
423136 -
嵌入式
+关注
关注
5082文章
19104浏览量
304797
发布评论请先 登录
相关推荐
【中级】labview每日一教【11.14】labview多核编程篇
NI LabVIEW的多核编程技术指南
基于RealView的多核调试
多核架构及编程技术
多核专家系列:多核软件迁移与开发:挑战与解决方案

多核软件调试方法与困难
多核软件调试的难点和新方法分析
KeyStone多核SoC工具套件
基于NI LabVIEW图形化编程对多核处理器和其他并行硬件进行编程
多核处理器的基本架构是什么?有哪些调试方法?
多核JTAG调试方法的特点及应用挑战






 工商网监
工商网监
评论