 了解SOK的原理
了解SOK的原理
在上期文章中,我们对 HugeCTR Sparse Operation Kit (以下简称SOK) 的基本功能,性能,以及 API 用法做了初步的介绍,相信大家对如何使用 SOK 已经有了基本的了解。在这期文章中,我们将从在 TensorFlow 上使用 SOK 时常见的“数据并行-模型并行-数据并行”流程入手,带大家详细了解 SOK 的原理。
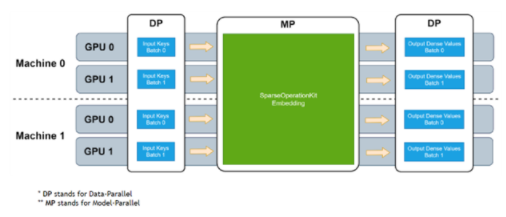
图 1:SOK 训练的数据并行-模型并行-数据并行流程
1. Input Dispatcher
Input Dispatcher 的职责是将数据以并行的形式的输入,分配到各个 GPU 上。总共分为以下几个步骤:
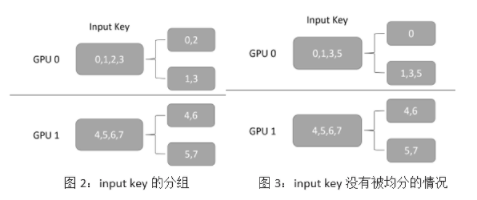
第一步:对每个 GPU 接收到的数据并行的 category key,按照 key 求余 GPU 的数量计算出其对应的 GPU ID,并分成和 GPU 数量相同的组;同时计算出每组内有多少 key。例如图 2 中,GPU 的总数为 2,GPU 0 获取的输入为[0, 1, 2, 3],根据前面所讲的规则,它将会被分成[0, 2], [1, 3]两组。注意,在这一步,我们还会为每个分组产生一个 order 信息,用于 output dispacher 的重排序。
第二步:通过 NCCL 交换各个 GPU 上每组 key 的数量。由于每个 GPU 获取的输入,按照 key 求余 GPU 数量不一定能够均分,如图 3 所示,提前在各个 GPU 上交换 key 的总数,可以在后面交换 key 的时候减少通信量。
第三步:使用 NCCL,在各个 GPU 间按照 GPU ID 交换前面分好的各组 key,如图 4 所示。
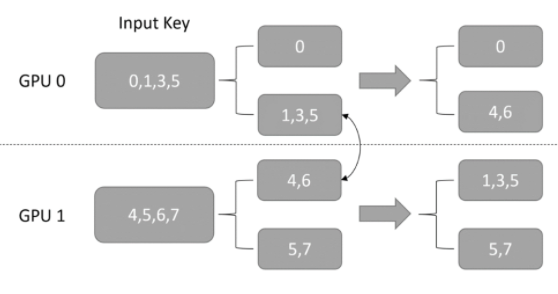
图 4:GPU 间交换 Input key
Step4:对交换后的所有 key 除以 GPU 总数,这一步是为了让每个 GPU 上的 key的数值范围都小于 embedding table size 整除 GPU 的数量,保证后续在每个 worker 上执行 lookup 时不会越界,结果如图 5 所示。
总而言之,经过上面 4 个步骤,我们将数据并行地输入,按照其求余 GPU 数量的结果,分配到了不同对应的 GPU 上,完成了 input key 从数据并行到模型并行的转化。虽然用户往每个 GPU 上输入的都可以是 embedding table 里的任何一个 key,但是经过上述的转化过程后,每个 GPU 上则只需要处理 embedding table 里 1/GPU_NUMBER 的 lookup。
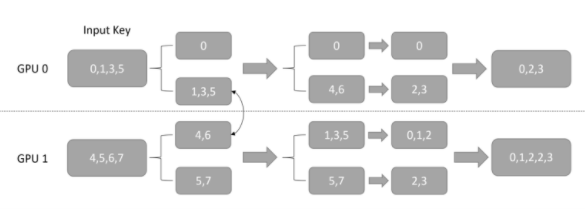
图 5:整除 input key
2. Lookup
Lookup 的功能比较简单,和单机的 lookup 的行为相同,就是用 input dispatcher 输出的 key,在本地的 embedding table 里查询出对应的 embedding vector,我们同样用一个简单的图来举例。注意下图中 Global Index 代表每个 embedding vector 在实际的 embedding table 中对应的 key,而 Index 则是当前 GPU 的“部分”embedding table 中的 key。
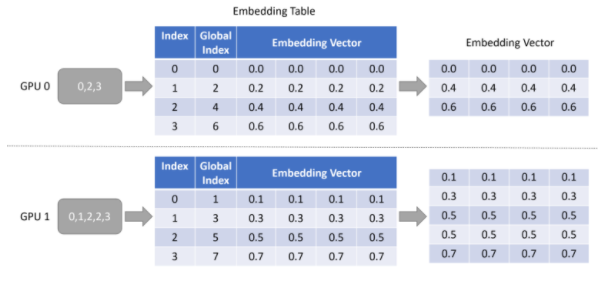
图 6:使用 Embedding Table 进行 Lookup
3. Output Dispatcher
和 input dispatcher 的功能对应,output dispatcher 是将 embedding vector 按照和 input dispatcher 相同的路径、相反的方向将 embedding vector 返回给各个 GPU,让模型并行的 lookup 结果重新变成数据并行。
第一步:复用 input dispatcher 中的分组信息,将 embedding vector 进行分组,如图 7 所示。
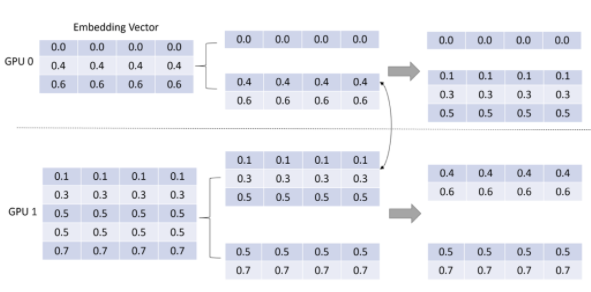
图 7:Embedding vector 的分组
第二步:通过 NCCL 将 embedding vector 按 input dispatcher 的路径返还,如图 8 所示。
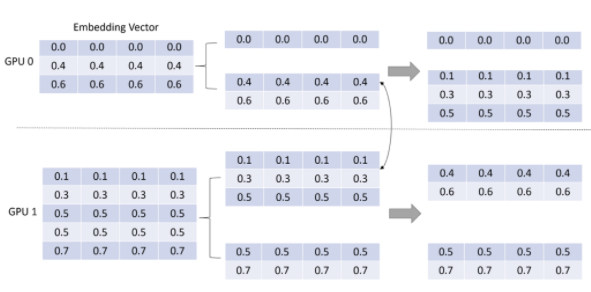
图 8:Embedding vector 的返还
第三步:复用 input dispatcher 第一步骤的结果,将 embedding vector 进行重排序,让其和输入的 key 顺序保持一致,如图 9 所示。

图 9:Embedding vector 的重排序
可以看到, GPU 0 上输入的[0, 1, 3, 5],最终被转化为了[0.0, …], [0.1, …], [0.3, …], [0.5, …] 四个 embedding vector,虽然其中有 3 个 embedding vector 被存储在 GPU 1 上,但是以一种对用户透明的方式,在 GPU 0 上拿到了对应的 vector。在用户看来,就好像整个 embedding table 都存在 GPU 0 上一样。
4. Backward
在 backward 中,每个 GPU 会得到和 input 的 key 所对应的梯度,也就是数据并行的梯度。此时的梯度对应的 embedding vector 可能并不在当前 GPU 上,所以还需要做一步梯度的交换。这个步骤和 output dispatcher 的第三步骤中的工作流程的路径完全相同,只是方向相反。 仍然以前面的例子举例,GPU 0 获取了 key [0, 1, 3, 5]的梯度,我们把它们分别叫做 grad0, grad1, grad3, grad5;由于 grad1,grad3,grad5 对应的 embedding vector 在 GPU 1 上,所以我们把它们和 GPU 1 上的 grad4, grad6 进行交换,最终在得到了 GPU 0 上的梯度为[grad0, grad4, grad6],GPU 1 上的梯度为[grad1, grad3, grad5, grad5, gard7]。
结语
以上就是 SOK 将数据并行转化为模型并行再转回数据并行的过程,这整个流程都被封装在了 SOK 的 Embedding Layer 中,用户可以直接调用相关的 Python API 即可轻松完成训练。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4729浏览量
128890 -
API
+关注
关注
2文章
1499浏览量
61962 -
python
+关注
关注
56文章
4792浏览量
84627
发布评论请先 登录
相关推荐


SOK在手机行业的应用案例






 工商网监
工商网监
评论