 关于YOLOU中模型的测试
关于YOLOU中模型的测试
这里推荐一个YOLO系列的算法实现库YOLOU,此处的“U”意为“United”的意思,主要是为了学习而搭建的YOLO学习库,也借此向前辈们致敬,希望不被骂太惨;
整个算法完全是以YOLOv5的框架进行,主要包括的目标检测算法有:YOLOv3、YOLOv4、YOLOv5、YOLOv5-Lite、YOLOv6、YOLOv7、YOLOX以及YOLOX-Lite。
同时为了方便算法的部署落地,这里所有的模型均可导出ONNX并直接进行TensorRT等推理框架的部署,后续也会持续更新。
01
模型精度对比
 服务端模型 这里主要是对于YOLO系列经典化模型的训练对比,主要是对于YOLOv5、YOLOv6、YOLOv7以及YOLOX的对比,部分模型还在训练之中,后续所有预训练权重均会放出,同时对应的ONNX文件也会给出,方便大家部署应用落地。 注意,这里关于YOLOX也没完全复现官方的结果,后续有时间还会继续调参测试,尽可能追上YOLOX官方的结果。 下表是关于YOLOU中模型的测试,也包括TensorRT的速度测试,硬件是基于3090显卡进行的测试,主要是针对FP32和FP16进行的测试,后续的TensorRT代码也会开源。目前还在整理之中。
服务端模型 这里主要是对于YOLO系列经典化模型的训练对比,主要是对于YOLOv5、YOLOv6、YOLOv7以及YOLOX的对比,部分模型还在训练之中,后续所有预训练权重均会放出,同时对应的ONNX文件也会给出,方便大家部署应用落地。 注意,这里关于YOLOX也没完全复现官方的结果,后续有时间还会继续调参测试,尽可能追上YOLOX官方的结果。 下表是关于YOLOU中模型的测试,也包括TensorRT的速度测试,硬件是基于3090显卡进行的测试,主要是针对FP32和FP16进行的测试,后续的TensorRT代码也会开源。目前还在整理之中。 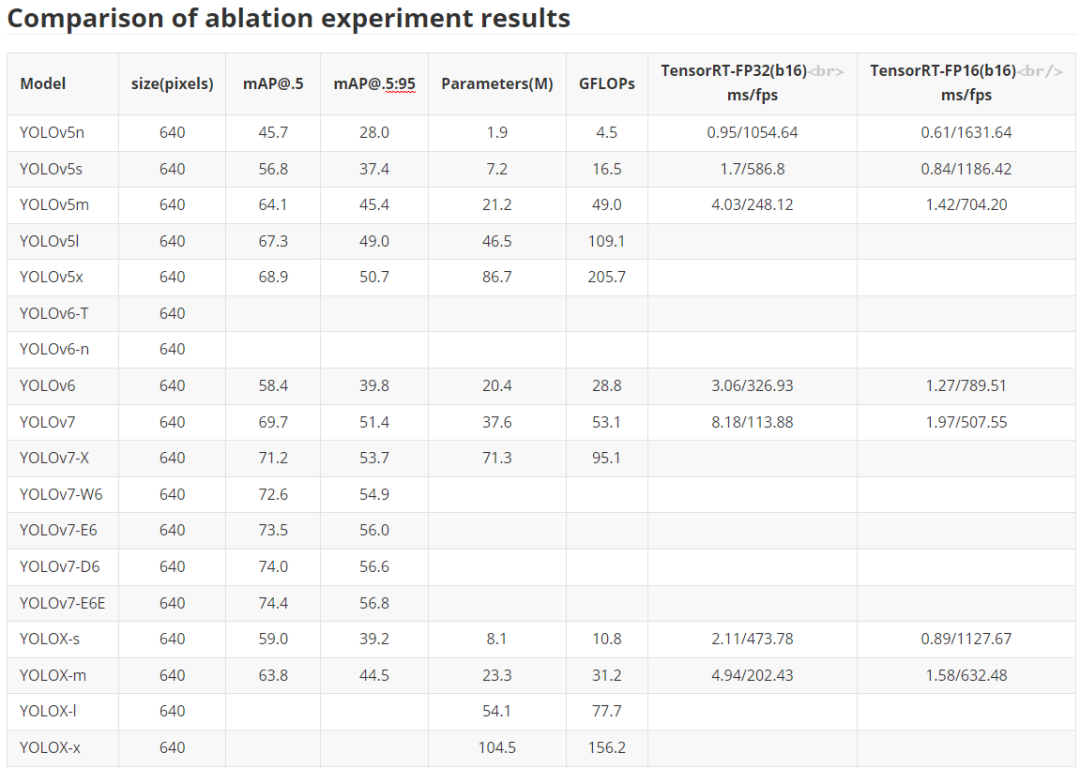 轻量化模型 为了大家在手机端或者其他诸如树莓派、瑞芯微、AID以及全志等芯片的部署,YOLOU也对YOLOv5和YOLOX进行了轻量化设计。 下面主要是对于边缘端使用的模型进行对比,主要是借鉴之前小编参与的YOLOv5-Lite的仓库,这里也对YOLOX-Lite进行了轻量化迁移,总体结果如下表所示,YOLOX-Lite基本上可以超越YOLOv5-Lite的精度和结果。
轻量化模型 为了大家在手机端或者其他诸如树莓派、瑞芯微、AID以及全志等芯片的部署,YOLOU也对YOLOv5和YOLOX进行了轻量化设计。 下面主要是对于边缘端使用的模型进行对比,主要是借鉴之前小编参与的YOLOv5-Lite的仓库,这里也对YOLOX-Lite进行了轻量化迁移,总体结果如下表所示,YOLOX-Lite基本上可以超越YOLOv5-Lite的精度和结果。 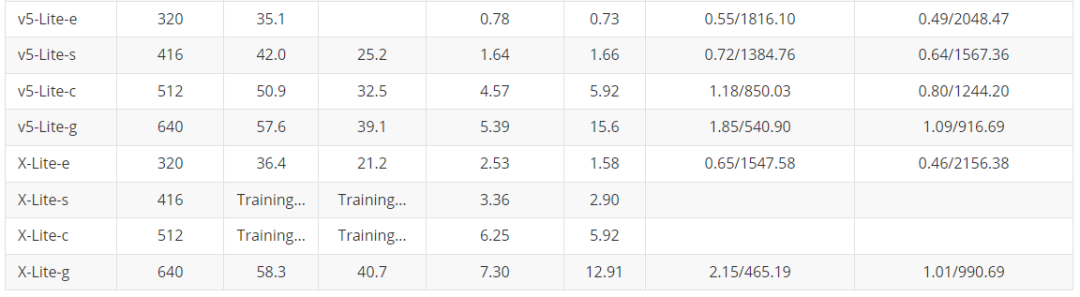
02
如何使用YOLOU?
安装 这里由于使用的是YOLOv5的框架进行的搭建,因此安装形式也及其的简单,具体如下:
gitclonehttps://github.com/jizhishutong/YOLOU cdYOLOU pipinstall-rrequirements.txt数据集 这里依旧使用YOLO格式的数据集形式,文件夹形式如下:
train:../coco/images/train2017/ val:../coco/images/val2017/具体的标注文件和图像list如下所示:
├──images#xx.jpgexample │├──train2017 ││├──000001.jpg ││├──000002.jpg ││└──000003.jpg │└──val2017 │├──100001.jpg │├──100002.jpg │└──100003.jpg └──labels#xx.txtexample ├──train2017 │├──000001.txt │├──000002.txt │└──000003.txt └──val2017 ├──100001.txt ├──100002.txt └──100003.txt参数配置 YOLOU为了方便切换不同模型之间的训练,这里仅仅需要配置一个mode即可切换不同的模型之间的检测和训练,具体意义如下:
 注意:这里的mode主要是对于Loss计算的选择,对于YOLOv3、YOLOv4、YOLOv5、YOLOR以及YOLOv5-Lite直接设置mode=yolo即可,对于YOLOX以及YOLOX-Lite则设置mode=yolox,对于YOLOv6和YOLOv7则分别设置mode=yolov6和mode=yolov7; 注意由于YOLOv7使用了Aux分支,因此在设置YOLOv7时有一个额外的参数需要配置,即use_aux=True。 具体训练指令如下:
注意:这里的mode主要是对于Loss计算的选择,对于YOLOv3、YOLOv4、YOLOv5、YOLOR以及YOLOv5-Lite直接设置mode=yolo即可,对于YOLOX以及YOLOX-Lite则设置mode=yolox,对于YOLOv6和YOLOv7则分别设置mode=yolov6和mode=yolov7; 注意由于YOLOv7使用了Aux分支,因此在设置YOLOv7时有一个额外的参数需要配置,即use_aux=True。 具体训练指令如下:
pythontrain.py--modeyolov6--datacoco.yaml--cfgyolov6.yaml--weightsyolov6.pt--batch-size32检测指令如下:
pythondetect.py--source0#webcam file.jpg#image file.mp4#video path/#directory path/*.jpg#glob 'https://youtu.be/NUsoVlDFqZg'#YouTube 'rtsp://example.com/media.mp4'#RTSP,RTMP,HTTPstream
-
硬件
+关注
关注
11文章
3312浏览量
66199 -
模型
+关注
关注
1文章
3226浏览量
48806 -
代码
+关注
关注
30文章
4779浏览量
68516
原文标题:汇集YOLO系列所有算法,YOLOU算法实现库来啦
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于模型的动态测试工具TPT
关于multisim中仿真模型的建立
动态模型在软件系统测试过程中的应用研究
一种新的软件测试模型—软件层次化模型
关于模型测试与持续集成相结合的可行性分析
辐射测试中Antenna与EUT的测试距离换算

Simulink集成模型测试太慢怎么办?






 工商网监
工商网监
评论