 内存的基本概念以及操作系统的内存管理算法
内存的基本概念以及操作系统的内存管理算法
内存的基本概念
内存是计算机系统中除了处理器以外最重要的资源,用于存储当前正在执行的程序和数据。内存是相对于CPU来说的,CPU可以直接寻址的存储空间叫做内存,CPU需要通过驱动才能访问的叫做外存。
内存一般采用半导体存储单元,分为只读存储器(ROM,Read Only Memory)、随机存储器(RAM,Random Access Memory)ROM一般只能读取不能写入,掉电后其中的数据也不会丢失。RAM既可以从中读取也可以写入,但是掉电后其中的数据会丢失。内存一般指的就是RAM。ROM在嵌入式系统中一般用于存储BootLoader以及操作系统或者程序代码或者直接当硬盘使用。近年来闪存(Flash)已经全面代替了ROM在嵌入式系统中的地位,它结合了ROM和RAM的长处,不仅具备电子可擦除可编程的特性,而且断电也不会丢失数据,同时可以快速读取数据。
两类内存管理方式
内存管理模块管理系统的内存资源,它是操作系统的核心模块之一。主要包括内存的初始化、分配以及释放。
从分配内存是否连续,可以分为两大类。
连续内存管理:
为进程分配的内存空间是连续的,但这种分配方式容易形成内存碎片(碎片是难以利用的空闲内存,通常是小内存),降低内存利用率。连续内存管理主要分为单一连续内存管理和分区式内存管理两种。
非连续内存管理:
将进程分散到多个不连续的内存空间中,可以减少内存碎片,内存使用率更高。如果分配的基本单位是页,则称为分页内存管理;如果基本单位是段,则称为分段内存管理。
当前的操作系统,普遍采用非连续内存管理方式。不过因为分配粒度较大,对于内存较小的嵌入式系统,一般采用连续内存管理。本文主要对嵌入式系统中常用的连续内存管理的分区式内存管理进行介绍。
分区式内存管理
分区式内存管理分为固定分区和动态分区。
固定分区:
事先就把内存划分为若干个固定大小的区域。分区大小既可以相等也可以不等。固定分区易于实现,但是会造成分区内碎片浪费,而且分区总数固定,限制了可以并发执行的进程数量。
动态分区:
根据进程的实际需要,动态地给进程分配所需内存。
动态分区式内存管理
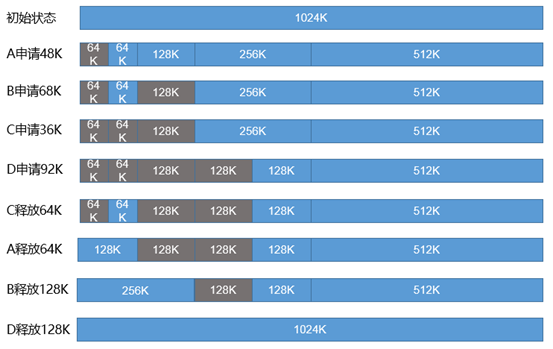
1运作机制动态分区管理一般采用空闲链表法,即基于一个双向链表来保存空闲分区。对于初始状态,整个内存块都会被作为一个大的空闲分区加入到空闲链表中。当进程申请内存时,将会从这个空闲链表中找到一个大小满足要求的空闲分区。如果分区大于所需内存,则从该分区中拆分出需求大小的内存交给进程,并将此拆分出的内存从空闲链表中移除,剩下的内存仍然是一个挂在空闲链表中的空闲分区。2数据结构
空闲链表法有多种数据结构实现,这里介绍一种较为简单的数据结构。每个空闲分区的数据结构中包含分区的大小,以及指向前一个分区和后一个分区的指针,这样就能将各个空闲分区链接成一个双向链表。

3内存分配算法
First Fit (首次适应算法)
First Fit要求空闲分区链表以地址从小到大的顺序连接。分配内存时,从链表的第一个空闲分区开始查找,将最先能够满足要求的空闲分区分配给进程。
Next Fit (循环首次适应算法)
Next Fit由First Fit算法演变而来。分配内存时,从上一次刚分配过的空闲分区的下一个开始查找,直至找到能满足要求的空闲分区。查找时会采用循环查找的方式,即如果直到链表最后一个空闲分区都不能满足要求,则返回到第一个空闲分区开始查找。
Best Fit (最佳适应算法)
从所有空闲分区中找出能满足要求的、且大小最小的空闲分区。为了加快查找速度,Best Fit算法会把所有空闲分区按其容量从小到大的顺序链接起来,这样第一次找到的满足大小要求的内存必然是最小的空闲分区。
Worst Fit (最坏适应算法)
从所有空闲分区中找出能满足要求的、且大小最大的空闲分区。Worst Fit算法按其容量从大到小的顺序链接所有空闲分区。
Two LevelSegregated Fit (TLSF)
使用两层链表来管理空闲内存,将空闲分区大小进行分类,每一类用一个空闲链表表示,其中的空闲内存大小都在某个特定值或者某个范围内。这样存在多个空闲链表,所以又用一个索引链表来管理这些空闲链表,该表的每一项都对应一种空闲链表,并记录该类空闲链表的表头指针。
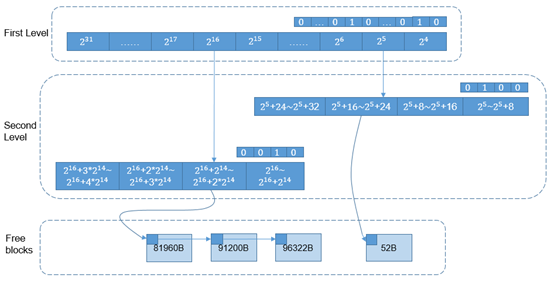
图中,第一层链表将空闲内存块的大小根据2的幂进行分类。第二层链表是具体的每一类空闲内存块按照一定的范围进行线性分段。
比如25这一类,以23即8分为4个内存区间
【25,25+8),
【25+8,25+16),
【25+16,25+24),
【25+24,25+32);
216这一类,以214分为4个小区间
【216,216+214),
【216+214,216+2*214),
【216+2*214,216+3*214),
【216+3*214,216+4*214)。
同时为了快速检索到空闲块,每一层链表都有一个bitmap用于标记对应的链表中是否有空闲块,比如第一层bitmap后3位010,表示25这一类内存区间有空闲块。对应的第二层bitmap为0100表示【25+16,25+24)这个区间有空闲块,即下面的52Byte。
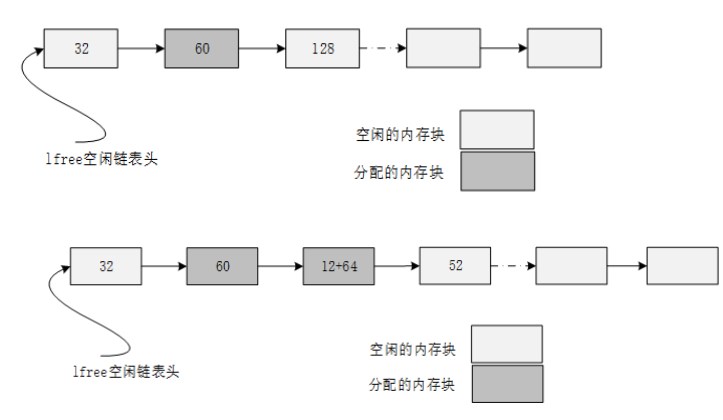
Buddysystems(伙伴算法)
Segregated Fit算法的变种,具有更好的内存拆分和回收合并效率。伙伴算法有很多种类,比如BinaryBuddies,Fibonacci Buddies等。Binary Buddies是最简单也是最流行的一种,将所有空闲分区根据分区的大小进行分类,每一类都是具有相同大小的空闲分区的集合,使用一个空闲双向链表表示。BinaryBuddies中所有的内存分区都是2的幂次方。
因为无论是已分配的或是空闲的分区,其大小均为 2 的幂次方,即使进程申请的内存小于分配给它的内存块,多余的内存也不会再拆分出来给其他进程使用,这样就容易造成内部碎片。
当进程申请一块大小为n的内存时的分配步骤为:
计算一个i值,使得2i-1
在空闲分区大小为2i的空闲链表中查找。
如果找到空闲块,则分配给进程。
如果2i的空闲分区已经耗尽,则在分区大小为2i+1的空闲链表中查找。
如果存在2i+1的空闲分区,则将此空闲块分为相等的两个分区,这两分区就是一对伙伴,其中一块分配给进程,另一块挂到分区大小为2i的空闲链表中。
如果2i+1的空闲分区还是不存在,则继续查找大小为2i+2的空闲分区。如果找到,需要进行两次拆分。第一次拆分为两块大小为2i+1的分区,一块分区挂到大小为2i+1的空闲链表中,另一块分区继续拆分为两块大小为2i的空闲分区,一块分配给进程,另一块挂到大小为2i的空闲链表中。
如果2i+2的空闲分区也找不到,则继续查找2i+3,以此类推。
在内存回收时,如果待回收的内存块与空闲链表中的一块内存互为伙伴,则将它们合并为一块更大的内存块,如果合并后的内存块在空闲链表中还有伙伴,则继续合并到不能合并为止,并将合并后的内存块挂到对应的空闲链表中。
下面的表格对上面6种算法的优缺点进行了比较:
内存算法优点缺点
First Fit高地址空间大空闲块被保留低地址空间被不断拆分,造成碎片;每次都从第一个空闲分区开始查找,增加了查找时的系统开销
Next Fit空闲分区分布比较均匀,算法开销小缺乏大内存空闲块
Best Fit用最小内存满足要求,保留大内存空闲块每次分配后所拆分出来的剩余空闲内存总是最小的,造成许多小碎片,算法开销大
Worst Fit每次分配后所拆分出来的剩余空闲内存仍较大,减少小碎片产生缺乏大内存空闲块,算法开销大
TLSF查找效率高,时间复杂度小,碎片问题表现良好内存回收时算法复杂,系统开销大
Buddy systems内部碎片比较严重外部碎片较少
审核编辑:汤梓红
-
cpu
+关注
关注
68文章
10854浏览量
211565 -
ROM
+关注
关注
4文章
563浏览量
85731 -
内存
+关注
关注
8文章
3019浏览量
74000 -
操作系统
+关注
关注
37文章
6801浏览量
123280
原文标题:如何高效管理MCU内存? 多种分配算法对比
文章出处:【微信号:mcugeek,微信公众号:MCU开发加油站】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论