 将OpenCL编译到FPGA
将OpenCL编译到FPGA
异构计算是指不断增长的一类系统,其中应用程序在不同的处理器和加速器设备的混合上执行以最大化吞吐量。在这种系统上执行程序需要一种编程范式,该范式向应用程序开发人员提供一致的系统视图。OpenCL 框架是为解决异构计算系统的需求和挑战而创建的行业标准。
在最基本的层面上,OpenCL 框架为应用程序程序员提供了与设备供应商无关的平台定义和跨所有实现该标准的设备的单一内存模型。这些特性使 OpenCL 程序员能够专注于正在开发的应用程序的核心挑战,而不是特定计算设备的特定细节。
OpenCL 框架的第一个组件是平台,它定义了可用于执行程序的资源。在一个 OpenCL 平台中,总是有一个主机处理器和至少一个加速设备。主机处理器负责将作业分派给加速器以及启动主机/加速器内存传输。此主机始终使用 CPU 实现,加速器可以是 CPU、GPU 或 FPGA。这些加速设备的控制是通过一组通用的 API 函数来实现的,这些 API 函数是 OpenCL 标准的一部分。
加速设备上的作业采用内核执行的形式。内核是运行在加速设备上的应用程序的计算功能。OpenCL 中的一个应用程序可能有一个或多个内核,每个内核的特点是表达一个数据并行操作。例如,图 1 显示了将在 CPU 上执行的程序转换为适合 OpenCL 的数据和任务并行表示。
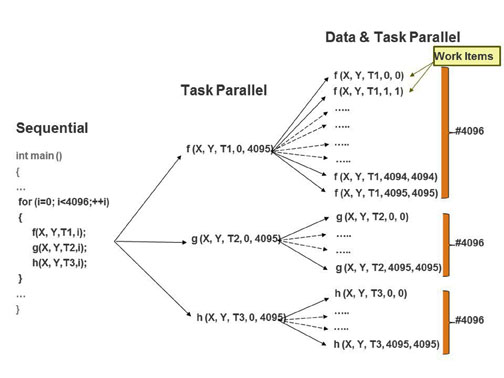
图 1:从顺序到 sata 和任务并行应用程序
在图 1 中代码的顺序版本中,函数 f、g 和 h 在“for”循环内执行。每个函数将数据集 X 和 Y 作为输入源并产生一个输出 T,它不会被“for”循环内的任何其他函数消耗。因此,代码的顺序版本中的循环可以分配给函数 f、g 和 h,以创建应用程序的任务并行表示,如图 1 的中心列所示。如果函数 f、g 和 h 的每次调用独立于上一个和下一个调用,则应用程序是任务和数据并行的,如图 1 的右侧列所示。函数 f、g 或 h 的每次调用代表加速设备执行的一个工作项。根据可用的计算资源,
除了为应用程序员提供与设备无关的数据并行编程模型外,OpenCL 还提供了统一的内存模型层次结构,如图 2 所示。
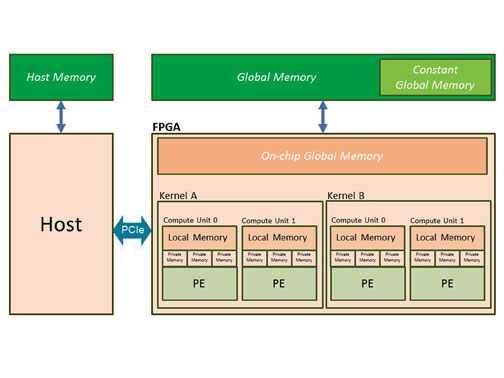
图 2:OpenCL 内存模型
在模型的应用层,内存空间分为主机内存和设备内存。与设备相关的内存进一步分为三个层次结构,包括全局内存、本地内存和私有内存。全局内存由连接到设备的内存组件(如 SDRAM)创建。映射到全局内存的缓冲区的管理由主机代码应用程序通过使用 OpenCL API 函数来处理。OpenCL API 函数用于确定缓冲区的大小以及对缓冲区的读写访问。在 OpenCL 内存模型支持的所有内存类型中,请务必记住,全局内存是容量最大、延迟最长的内存,
OpenCL 和 FPGA
FPGA 可以在制造后针对不同的算法进行编程,如图 3 所示,具有执行逻辑操作的查找表 (LUT)、存储 LUT 结果的触发器 (FF) 以及元件之间的连接和 I/O 焊盘,用于将数据输入和输出 IC。当代 FPGA 架构包含额外的计算 (DSP)、数据存储 (BRAM)、高速串行收发器和片外存储器控制器块。这些元素的组合为 FPGA 提供了为给定软件工作负载实现自定义逻辑的灵活性。
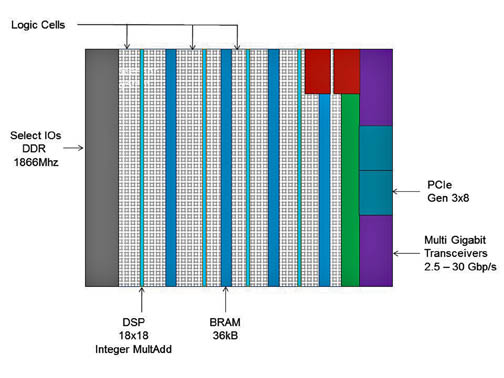
图 3:FPGA 的基本结构
在 OpenCL 的上下文中,由于内核代码的数据并行特性,FPGA 架构非常适合这种工作负载。与其他能够执行 OpenCL 内核的设备不同,FPGA 架构可以使用针对特定内核完全优化的内核进行定制,从而允许内核执行的并行性随 FPGA 设备的大小而扩展。
在加速器计算单元上执行的 OpenCL 应用程序内核。计算单元是指执行内核功能中的操作的处理器内核或加速器逻辑。
SHA-1 算法
SHA-1 算法是最常用的加密哈希函数之一。使用这些功能确保和检查数据完整性的能力已经成为在线签名和作为电子商务解决方案核心的安全套接字层 (SSL) 的基础。该函数非常适合 FPGA,因为它是通过 80 轮处理对 512 位数据集的与、异或、旋转、加法或移位操作组成的。每轮计算中使用的 512 位数据负载可以并行或块方式计算。
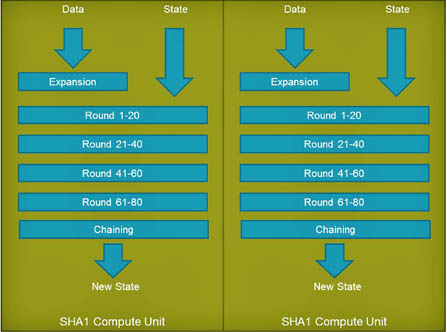
图 4:用于 SHA-1 的 FPGA 计算单元
SHA-1 功能的 FPGA 实现如图 4 所示。在此设计中,关键元素是创建自定义计算单元,以包含计算单个 SHA-1 所需的 80 轮处理。通过将所有 80 轮处理分组到同一个处理逻辑中,应用程序设计人员可以最大限度地减少与标准 CPU 实现所需的高速缓存或内存元素的交互。这反过来又增加了此功能的吞吐量并降低了维持所达到的吞吐量所需的功耗。下表总结了 FPGA 实现与 CPU 实现的优势:
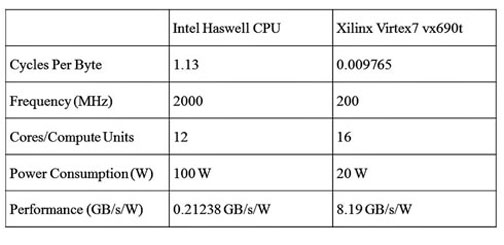
对于此比较,英特尔 Haswell CPU 有 12 个内核,能够执行任何 OpenCL 内核代码,但未针对任何特定工作负载进行优化。相比之下,FPGA 实现有 16 个内核优化为仅执行 SHA1 工作负载。加速器计算单元定制级别的差异直接转化为该工作负载的两个设备之间的性能差异。
Xilinx FPGA 结果是通过使用适用于 OpenCL、C 和 C++ 的 SDAccel 开发环境编译 SHA1 算法并在 Xilinx Virtex 7 器件上运行生成的二进制程序生成的。SDAccel 利用 FPGA 为数据中心应用程序加速提供高达 25 倍的性能功耗比,并结合了业界第一个支持 OpenCL、C 和 C++ 内核的任意组合的架构优化编译器,以及库、开发板和第一个完整的 CPU/GPU类似 FPGA 的开发和运行时经验。
审核编辑:汤梓红
-
FPGA
+关注
关注
1629文章
21728浏览量
602952 -
cpu
+关注
关注
68文章
10854浏览量
211563 -
OpenCL
+关注
关注
2文章
48浏览量
33297
发布评论请先 登录
相关推荐
Altera发布面向FPGA的OpenCL解决方案 简化FPGA开发
充分发挥FPGA优势 Altera首推新颖OpenCL工具
基于OpenCL标准的FPGA设计
Intel altera opencl 入门
Altera OpenCL
FPGA编译openCL内核文件出错
什么是OpenCL?面向FPGA的OpenCL有什么优点?
Altera发布业界第一个面向FPGA的OpenCL计划
面向Altera FPGA的OpenCL:提高性能和设计效能
C/C++/OpenCL 应用编译的SDSoC开发
针对OpenCL、C和 C++的SDAccel开发环境可利用FPGA实现数据中心应用加速
如何使用OpenCL轻松实现FPGA应用编程
Intel Cyclone V 开发板OpenCL使用手册免费下载
使用OpenCL for FPGA设计200万点频域滤波器





 工商网监
工商网监
评论