 Linux内核的内存屏障的原理和用法分析
Linux内核的内存屏障的原理和用法分析
圈里流传着一句话“珍爱生命,远离屏障”,这足以说明内存屏障是一个相当晦涩和难以准确把握的东西。使用过弱的屏障,会导致软件不稳定。使用过强的屏障,会引起性能问题。所以工程上,追求恰到好处、不偏不倚的屏障。本文力求用最浅显的语言,讲清楚内存屏障最晦涩的道理,本文也会给出五个工程案例,这些案例皆见于开源的代码,不涉及任何组织和个人未公开的技术。
一、引子
我国古代著名程序猿韩愈曾经写下一个名为《春雪》的函数:
新年都未有芳华,二月初惊见草芽。
白雪却嫌春色晚,故穿庭树作飞花。
这段代码讲述了一个关于memory reorder的故事,在计算机世界里面,冬天和春天并没有明确的界限,明明已经是春天了,但是还飘着冬天的雪。
下面我们看另外一段程序:

我们能确保c = 4吗?实际上,任何一个角度都确定不了。比如CPU0上面a = 3是“下雪”,flag = 1是“春天”,a=3看似在flag=1之前,实际可能由于memory reorder的原因发生在flag = 1之后,所以flag即便已经等于1,a也不一定等于3。
我们再退一万步讲,哪怕CPU0上面确实确保了春天不下雪,flag=1的时候a 100%就等于了3,那CPU1那边就万无一失了吗?答案也是否定的,因为,在CPU1上面,即便我们的代码是if(flag==1),接下来才做c=a+1,我们也不能确保a的load一定发生在flag==1之后。别忘了,CPU1会投机执行,比如碰到if(flag==1)这种条件,CPU可能直接忽略,不管三七二十一,还是可能先执行 load a, a+1的动作,然后反过来发现flag等于1,然后我认为我的投机是成功的;即便投机失败,CPU只需要保证load a, a+1的这些指令不retired就好。所以CPU1的load a, a+1完全可能发生在flag确切地等于1之前,因此即便CPU0保序了,CPU1仍然不能确保c=4。
我们看看CPU1在投机成功时候的行为逻辑和思想情感:
1. flag==1吗?
2. 不知道啊!我现在还没读出flag呢!
3. 管它呢,先假装flag==1吧,投机一把,执行loada, 把a+1看看
4.flag==1吗?哇,它真地等于1,太爽了,load a和a+1已经做完了。
如果投机失败了呢?
1. flag==1吗?
2.不知道啊!我现在还没读出flag呢!
3. 管它呢,先假装flag==1吧,投机一把,执行loada, 把a+1看看
4. flag==1吗?Oh,shit,它不等于1,load a, a+1白做了.....
这就是弱序系统的典型特点。请问CPU为什么要这么“混乱”?这正是现代CPU为了保证高效执行厉害的地方,但是也引入软件使用上的复杂度。这种复杂度,类似于宋代著名程序媛李清照的函数《声声慢·寻寻觅觅》:“寻寻觅觅,冷冷清清,凄凄惨惨戚戚。乍暖还寒时候,最难将息。三杯两盏淡酒,怎敌他、晚来风急?雁过也,正伤心,却是旧时相识。满地黄花堆积,憔悴损,如今有谁堪摘?守着窗儿,独自怎生得黑。梧桐更兼细雨,到黄昏、点点滴滴。这次第,怎一个愁字了得!”请问李清照童鞋说的究竟是春天还是秋天还是春天呢?据说至今也没有人能够解密。仅凭“乍暖还寒”一定会觉得是初春,但是你再继续看到“雁过也”、“满地黄花堆积”,这显然又不是春天的景象。
罢了罢了,这一切都不重要了,重要的是,四季并不分明,四季没有明确的界限。这是我们要牢记的第一个point!
二、屏障
正是因为四季没有明确的界限,所以当我们希望看到明确的顺序的时候,我们希望引入一道屏障。让冬天跑不到春天,让春天跑不过去冬天。
典型的ARM64有这么几种屏障:
a. DMB:Data Memory Barrier
b. DSB:Data Synchronization Barrier
c. ISB:Instruction Synchronization Barrier
d. LDAR(Load-Acquire)/STLR(Store-Release)
我们随便打开ARM的手册,看一个DMB的定义:
The Data Memory Barrier (DMB) prevents the reordering of specified explicit data accesses acrossthe barrier instruction. All explicit data load or store instructions, which are executed by the PEin programorder before the DMB, are observed by all Observerswithin a specified Shareabilitydomain before the data accesses after the DMB in program order.
码农的内心是崩溃的,人生已经这么悲催了,你为什么还要拿这样的绕口令来折磨我?什么叫“are observed by all Observers”?
下面我们给大家讲述2只狗狗出家门的故事:
上图的2只狗,首先在一个inner shareable domain里面,比如是自己的家门里面;然后是在一个outer shareable domain里面,比如是小区的出口;最后在太阳系里面。这2只小狗,出每一道门,都有observer可以看见它,有的observer是inner的(observer1),有的observer是outer的(observer2),有的observer属于full system,比如天上的嫦娥(observer3)。
现在我们提出如下需求:
a. 黄狗狗出门后白狗狗出门。
b. 黄狗狗和白狗狗出门后,放烟雾消杀。
当我们提出这样的需求的时候,我们看3样东西:
1. 我们首先要看需要保证顺序的2个事物的特征
在需求1里面,是2只特征一样的东西,都是狗狗;在需求2里面,两个事物之间一个是狗狗,一个是消杀的烟雾,显然不是同类。
狗狗在硬件和Linux软件层面上,可以理解为针对内存的memory load/store指令;放烟雾,这种不属于memory的load/store,比如你执行的是tlbi、add加法或者写的是ARM64系统寄存器(MSR指令),则显然不属于memory load/store。
这里就涉及到DMB和DSB的一个本质区别,DMB针对的是memory的load/store之间;DSB强调的是同类或不同类事物的先后完成。
所以对于这个场景,我们正确的屏障是:
load黄狗狗
dmb ??
load白狗狗
dsb ??
MSR消毒烟雾
第一个是dmb,第2个是dsb。上面dmb和dsb后面都加了两个“?”,证明这里有情况,什么情况?接着看。
2. 其次我们要看保序的observer在哪里
比如是家门口的小姑娘observer1(ISH,inner shareable)、还是小区门口的小姑娘observer2(OSH,outer shareable),还是天上的嫦娥呢(SY, Full System)?如果只是observer1看到黄狗狗先出门,白狗狗再出门,延迟显然更小。在越大的访问范围保序,硬件的延迟越大。假设我们现在的保序需求是:
a. 小区门口(outer shareable)的observer2先看到黄狗狗出来,再看到白狗狗出来;
b. 家门口(inner shareable)的observer1先看到两只狗狗出来,再看到放烟雾。
对于这个场景,我们正确的屏障是:
load黄狗狗
dmb OSH?
load白狗狗
dsb ISH?
MSR消毒烟雾
在DMB后面我们跟的是OSH,在DSB后面我们跟的是ISH,是因为observer的位置不一样。注意,能用小observer的不用大observer。小区门口的observer,没有透视眼+望远镜,是看不到你家门口的狗狗的。
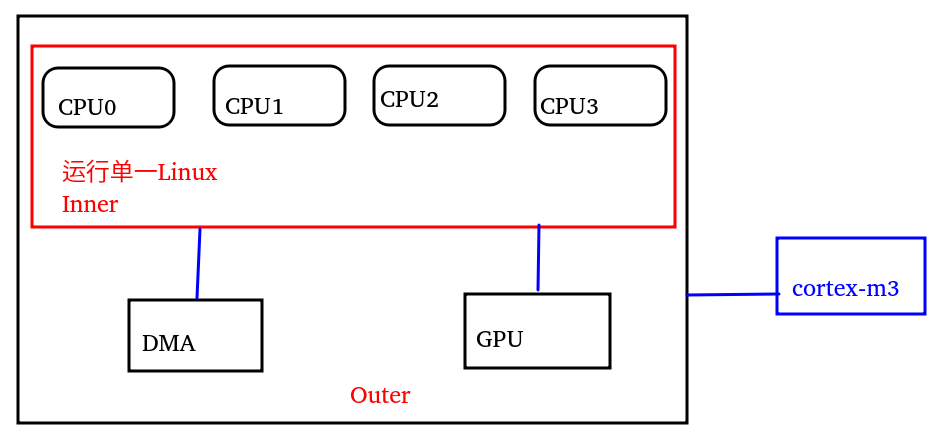
在一个典型的ARM64系统里面,运行Linux的各个CPU在一个inner;而GPU,DMA和CPU则同位于一个outer;当然还有可能孤悬海外的一个Cortex-M3的MCU,尽管可以和CPU以某种方式通信,但是不太参与inner以及outer里面的总线interconnect。
3. 最后我们保序的方向是什么
前面我们只关心狗狗的出门(load),假设两只狗狗都是进门(store)呢?或者我们现在要求黄狗狗先进门,白狗狗再出门呢?这个时候,我们要约束屏障的方向。
比如下面的代码,约束了observer1(inner)先看到黄狗狗出门,再看到白狗狗出门:
load黄狗狗
dmb ISHLD
load白狗狗
比如下面的代码,约束了observer2(outer)先看到黄狗狗进门,再看到白狗狗进门:
store黄狗狗
dmb OSHST
store白狗狗
这里我们看到一个用的是LD,一个用的是ST。我们再来看几个栗子,它们都是干什么的:
a.A(load); dmb ISHLD; B; C(load/store)
保证Inner内,A和C的顺序,只要A是load,无论C是load还是store;如果B既不是load也不是store,而是别的性质的事情,则dmb完全管不到B;
b. A(load); dsb ISHLD; B; C(load/store)
保证Inner内,A和C的顺序,只要A是load,无论C是load还是store;无论B是什么事情,inner都先到干完了A,再干B(注意这里是dsb啊,亲)。
c. A(store); dmb ISHLD; B; C(store)
A,B,C三个东西完全乱序,因为dmb约束不了性质不同的B,“LD”约束不了A和C的store顺序。
d. A(store); dmb ISHST; B; C(store)
ST约束了A和C 2个东西在inner这里看起来是顺序的,因为dmb约束不了B,所以B和A、C之间乱序。
注意上述4个屏障,由于都是ISH,故都不能保证observer2和observer3的顺序,在observer2和3眼里,上述所有屏障,A、B、C都是乱序的。
另外,如果无论什么方向,我们都要保序,我们可以去掉LD和ST,这样的保序方向是any-any。
到这里我们要牢记3个point:谁和谁保序;在哪里保序;朝哪个方向保序。
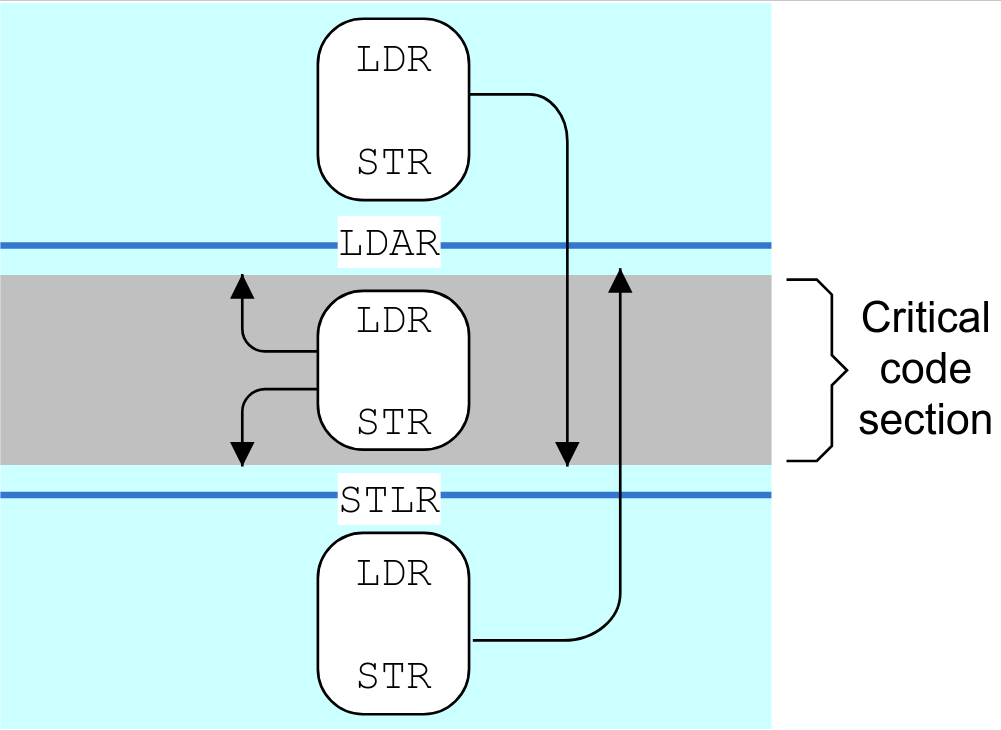
由此,我们可以清楚地看到DMB和DSB的区别,一个是保序内存load,store;一个是保序内存load,store + 其他指令。ISB的性质会有很大的不同,ISB主要用于刷新处理器中的pipeline,因此可确保在 ISB 指令完成后,才从内存系统中fetch位于该指令后的其他指令。比如你更新了代码段的PTE,需要重新取指。而LDAR(Load-Acquire)/STLR(Store-Release)则是比较新的one-way barrier。如下图,LDAR之前的LDR、STR可以跑到LDAR之后,但是不能跑到STLR之后;STLR之后的LDR,STR可以跑到STLR之前,但是不能跑到LDAR之前。所以STLR堵住了前面的往后面跑,LDAR堵住了后面的往前面跑。下面夹在LDAR和STLR之间的LDR,STR由于两边都是单向车道,而且都与它的行进方向相反,所以它夹在死胡同里,哪里也去不了。
注意,LDAR和STLR与前面的dmb, dsb有本质的不同,它本身是要跟地址的。比如现在家里有3只狗狗:
假设我们现在的要求是黄狗狗一定要在红尾哈巴狗之后出门,而白狗狗什么时候出我们都不在乎,则代码逻辑为:
ldr 白狗狗
ldar红尾哈巴狗
ldr 黄狗狗
黄狗狗被红尾哈巴狗的ldar挡住了,而白狗狗没有被任何东西挡住,它可以:
1. 第一个出门
2. 红尾哈巴狗出门后,黄狗狗出门前出门
3. 最后一个出门。
三、API
在Linux内核,有4组经典API:
SMP屏障
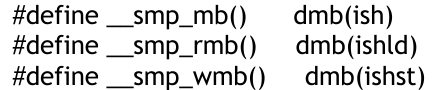
此屏障主要用于运行Linux的多个核之间对内存访问的保序,所以它主要是dmb,它是ish,通过ld、st来区分保序的方向。
DMA屏障

此屏障主要用于运行Linux的多个核与DMA引擎之间的保序,所以它主要是dmb,它是osh,通过ld、st来区分保序的方向。
屏障

非常严格的完成屏障,mb()保证了前面的指令的完成,前面的指令不必是load,store,比如可以是TLBI。dsb(ld)、dsb(st)则要弱一点,分别保证前面的load,store执行完了才执行后面的指令。
load_acquire/store_release
逻辑通常是一种成对的__smp_load_acquire()、__smp_store_release()逻辑,特别适合2个或者多个CPU之间的链式保序。在ARM64里面用的是stlr,ldar实现如下:

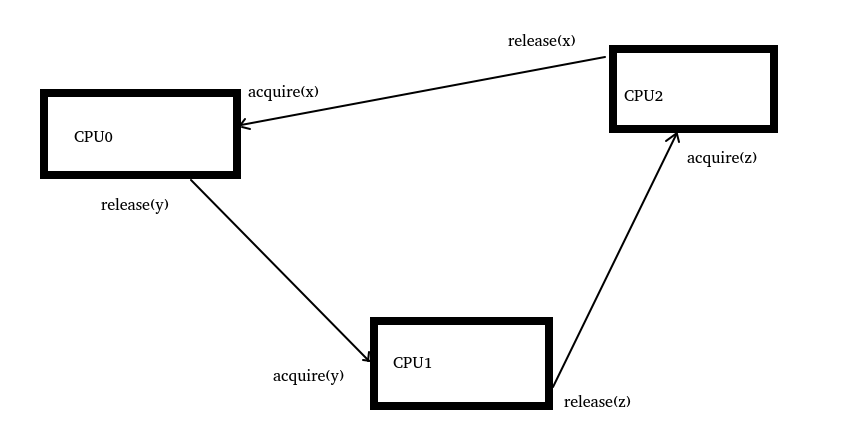
比如,下面的代码逻辑,保证了CPU0、CPU1、CPU2这3个CPU在链条上保序访问:

中间循环了一个链条逻辑,从而保证了这三个CPU中间内存访问的一些保序:
下面我们进入五个工程实战,“熟读唐诗三百首,不会吟诗也会吟”,最后我们会形成针对内存屏障正确用法的语感,而全然忘记语法。
实战一:运行Linux的多核通过中断通信
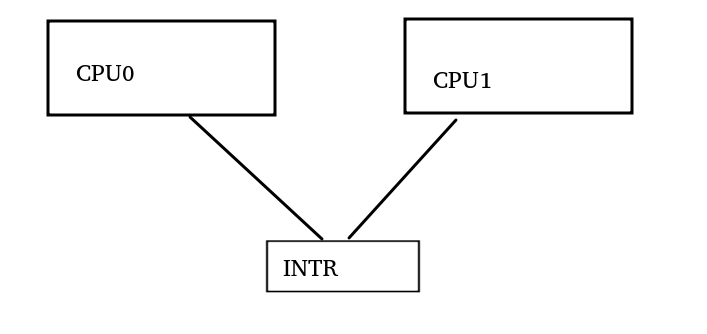
它的一般模式是:CPU0在DDR填入一段数据,然后通过store指令写INTR的寄存器向CPU1发送中断。
store数据
barrier?
store intr寄存器
中间应该用什么barrier?我们来回忆一下三要素:
a. 谁和谁保序?-> CPU0和CPU1这2个observer之间看到保序
b. 在哪里保序?-> 只需要CPU1看到CPU0写入DDR和intr寄存器是保序的
c. 朝哪个方向保序?-> CPU0写入一段数据,然后写入intr寄存器,只需要在st方向保序。
由此,我们得出结论,应该使用的barrier是:dmb + ish + st,显然就是smp_wmb。内核代码drivers/irqchip/irq-bcm2836.c也可以证实这一点:
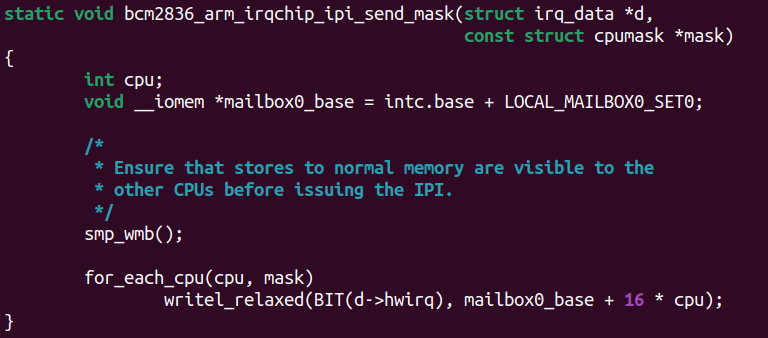
里面的注释非常清晰,smp_wmb()保证了发起IPI之前,其他CPU应该先观察到内存的数据在位。
现在我们把INTR换成gic-v3,就会变地tricky很多。gic-v3的IPI寄存器并不是映射到内存空间的,而是一个sys寄存器,通过MSR来写入。前面我们说过DMB只能搞定load/store之间,搞不定load/store与其他东西之间。
最开始的gic-v3驱动的作者其实也误用了smp_wmb,造成了该驱动的稳定性问题。于是Shanker Donthineni童鞋进行了一个修复,这个修复的commit如下:
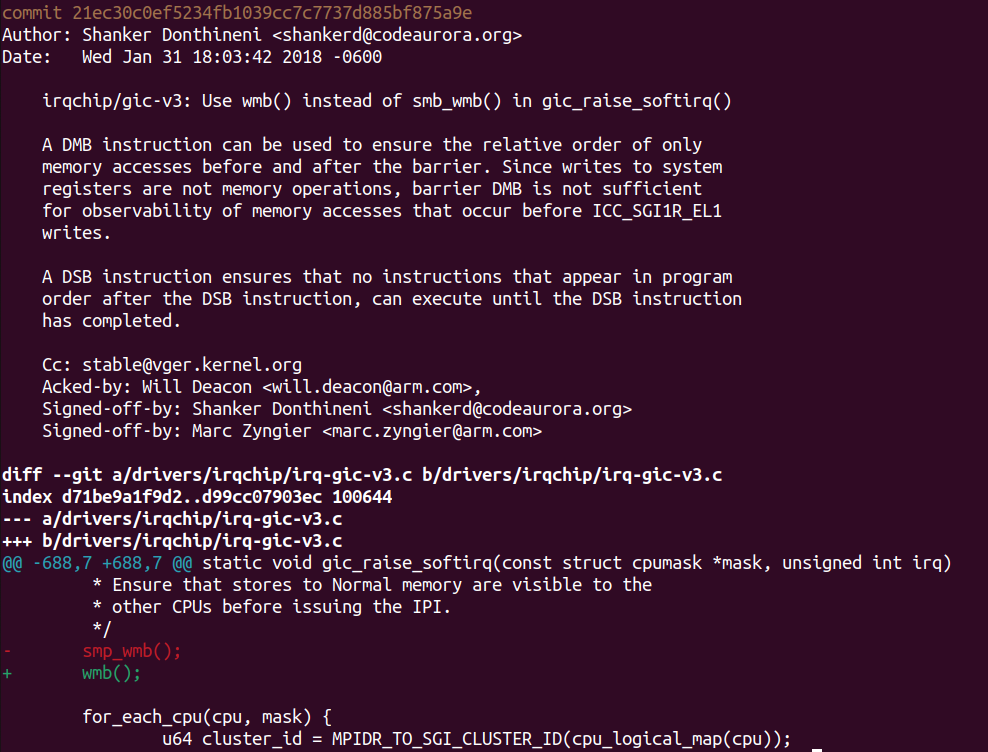
这个commit解释了我们不能用dmb搞定memory和sysreg之间的事情,于是这个patch替换为了更强力的wmb(),那么这个替换是正确的吗?
我们还是套一下三要素:
a. 谁和谁保序?-> CPU0和CPU1保序
b. 在哪里保序?-> 只需要CPU1看到CPU0写入DDR后,再看到它写sysreg
c. 朝哪个方向保序?-> CPU0写入一段数据,然后写入sysreg寄存器,只需要在st方向保序。
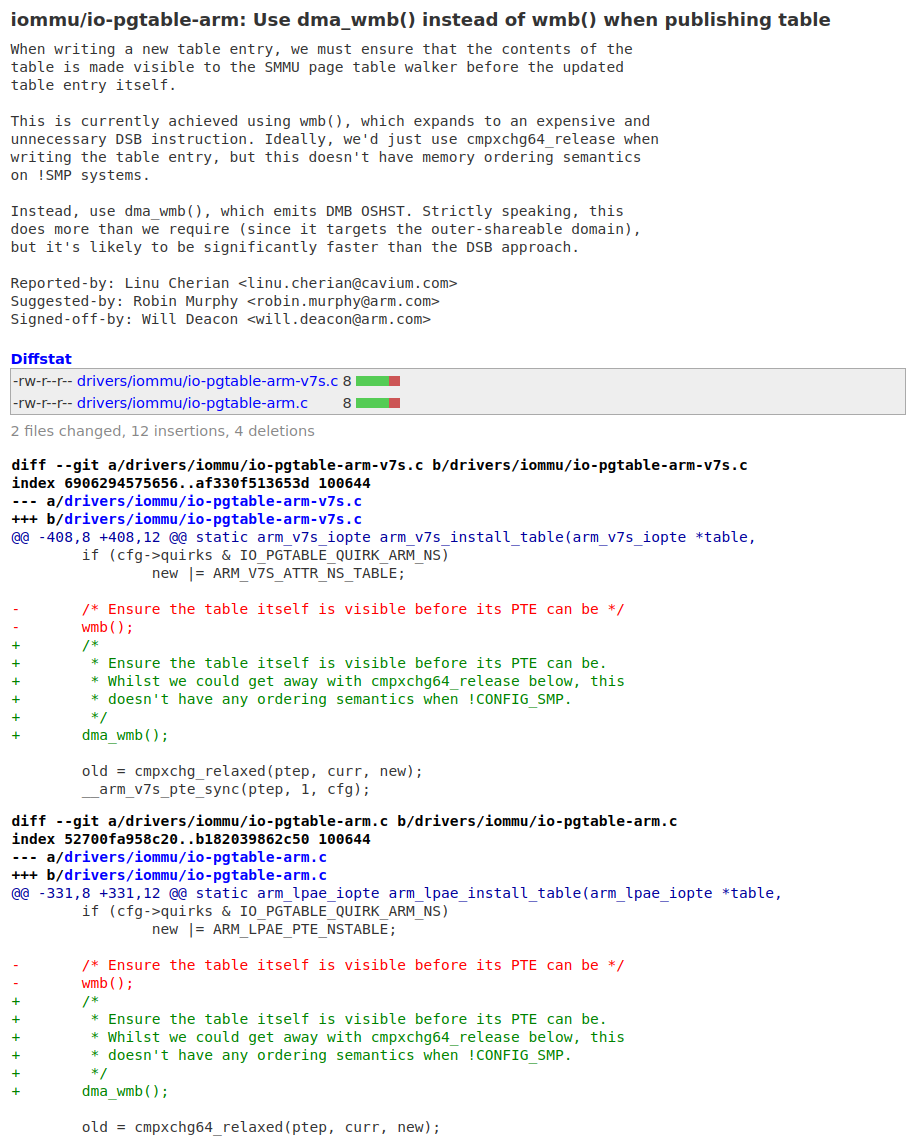
我们要进行保序的是CPU0和CPU1之间,显然他们属于inner。于是,我们得出正确的barrier应该是:dsb + ish + st,wmb()属于用力过猛了,因为wmb = dsb(st),保序范围是full system。基于此,笔者再次在主线内核对Shanker Donthineni童鞋的“修复”进行了“修复”,缩小屏障的范围,提升性能:
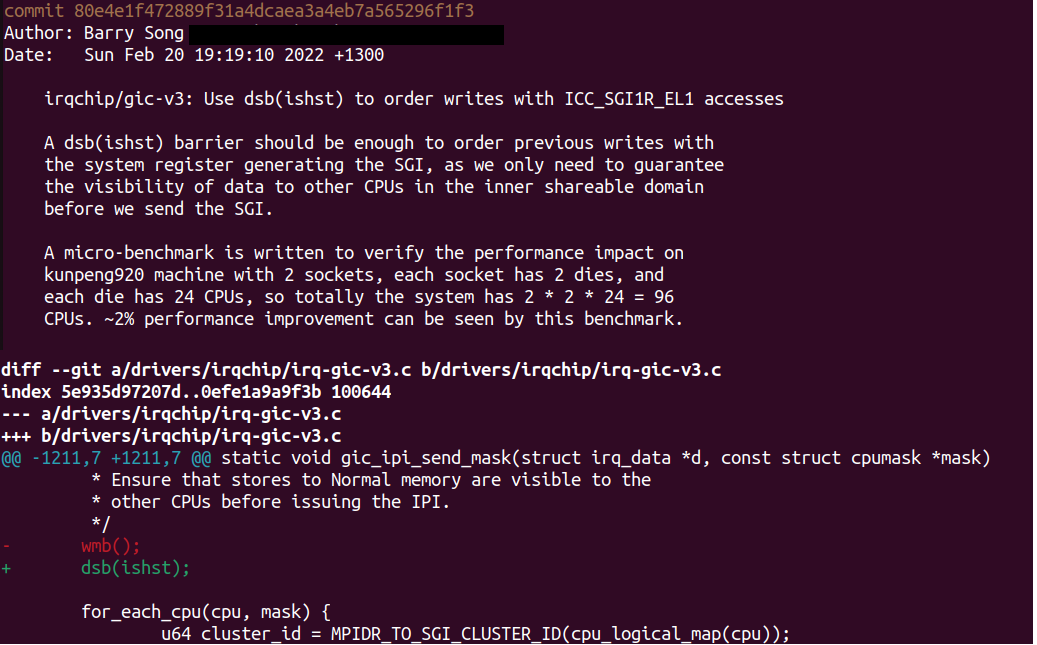
实战二:写入数据到内存后,发起DMA
下面我们把需求变更为,CPU写入一段数据后,写Ethernet控制器与CPU之间的doorbell,发起DMA操作发包。
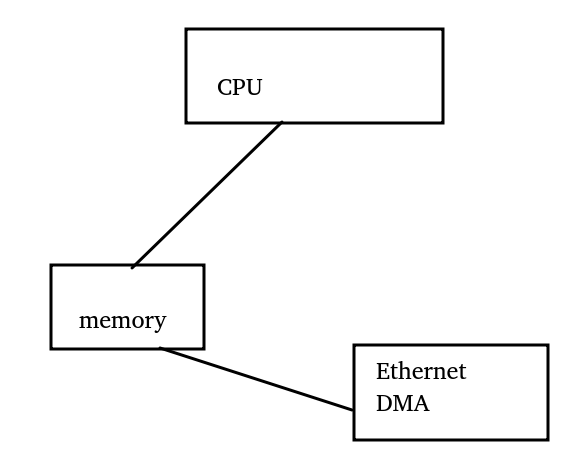
我们还是套一下三要素:
a. 谁和谁保序?-> CPU和EMAC的DMA保序,DMA和CPU显然不是inner
b. 在哪里保序?-> 只需要EMAC的DMA看到CPU写入发包数据后,再看到它写doorbell
c. 朝哪个方向保序?-> CPU写入一段数据,然后写入doorbell,只需要在st方向保序。
于是,我们得出正确的barrier应该是:dmb + osh + st,为什么是dmb呢,因为doorbell也是store写的。我们来看看Yunsheng Lin童鞋的这个commit,它把用力过猛的wmb(),替换成了用writel()来写doorbell:
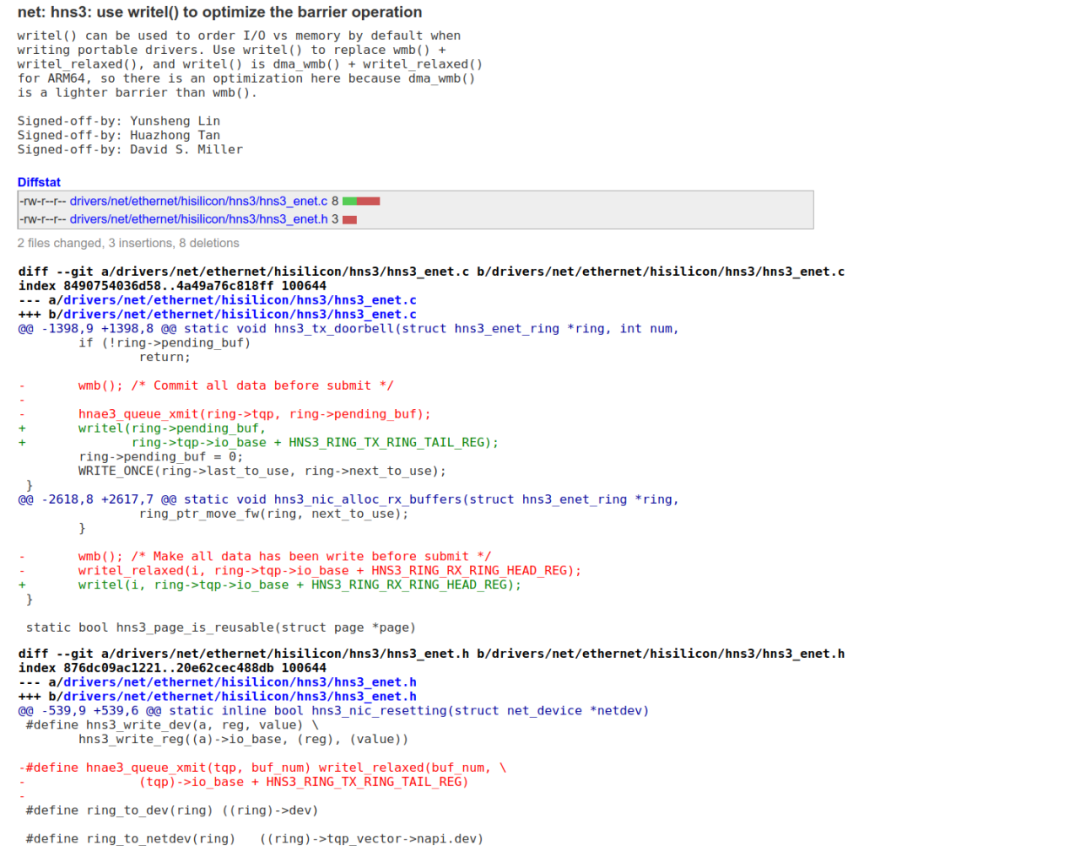
在ARM64平台下,writel内嵌了一个dmb + osh + st,这个从代码里面可以看出来:

同样的逻辑也可能发生在CPU与其他outer组件之间,比如CPU与ARM64的SMMU:
实战三:CPU与MCU通过共享内存和hwspinlock通信
下面我们把场景变更为主CPU和另外一个cortex-m的MCU通过一片共享内存通信,对这片共享内存的访问透过硬件里面自带的hwspinlock(hardware spinlock)来解决。
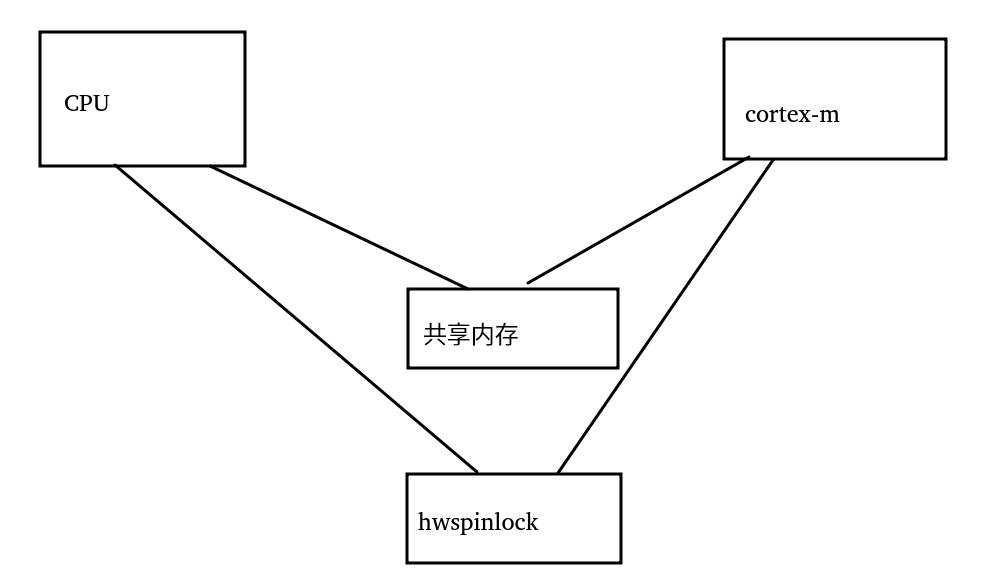
我们想象CPU持有了hwspinlock,然后读取对方cortex-m给它写入共享内存的数据,并写入一些数据到共享内存,然后解锁spinlock,通知cortex-m,这个时候cortex-m很快就可以持有锁。
我们还是套一下三要素:
a. 谁和谁保序?-> CPU和Cortex-M保序
b. 在哪里保序?-> CPU读写共享内存后,写入hwspinlock寄存器解锁,需要cortex-m看到同样的顺序
c. 朝哪个方向保序?-> CPU读写数据,然后释放hwspinlock,我们要保证,CPU的写入对cortex-m可见;我们同时要保证,CPU放锁前的共享内存读已经完成,如果我们不能保证解锁之前CPU的读已经完成,cortex-m很可能马上写入新数据,然后CPU读到新的数据。所以这个保序是双向的。
Talk is cheap, show me the code:

里面用的是mb(),这是一个dsb+full system+ld+st,读代码的注释也是一种享受。
实战四:SMMU与CPU通过一个queue通信
现在我们把场景切换为,SMMU与CPU之间,通过一片放入共享内存的queue来通信,比如SMMU要通知CPU一些什么event,它会把event放入queue,放完了SMMU会更新另外一个pointer内存,表示queue增长到哪里了。
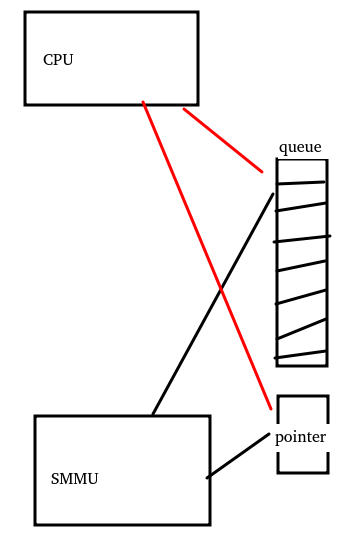
然后CPU通过这样的逻辑来工作

这是一种典型的控制依赖,而控制依赖并不能被硬件自动保序,CPU完全可以在if(pointer满足什么条件)满足之前,投机load了queue的内容,从而load到了错误的queue内容。
我们还是套一下三要素:
a.谁和谁保序?-> CPU和SMMU保序
b.在哪里保序?-> 要保证CPU先读取SMMU的pointer后,再读取SMMU写入的queue;
c.朝哪个方向保序?-> CPU读pointer,再读queue内容,在load方向保序
于是,我们得出正确的barrier应该是:dmb + osh + ld,我们来看看wangzhou童鞋的这个修复:

ARM64平台的readl()也内嵌了dmb + osh + ld屏障。显然这个修复的价值是非常大的,这是一个由弱变强的过程。前面我们说过,由强变弱是性能问题,而由弱变强则往往修复的是稳定性问题。也就是这种用错了弱barrier的场景,往往bug非常难再现,需要很长时间的测试才再现一次。
实战五:修改页表PTE后刷新tlb
现在我们的故事演变成了,CPU0修改了页表PTE,然后通知其他所有CPU,PTE应该被更新,其他CPU需要刷新TLB。
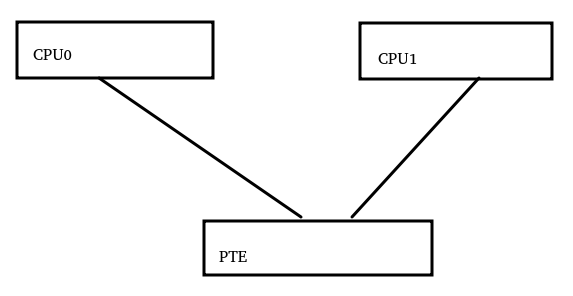
它的一般流程是CPU调用set_pte_at()修改了内存里面的PTE,然后进行tlbi等动作。这里就变地非常复杂了:

我们看看barrier1,它在屏障store和tlbi之间,由于二者一个是狗狗,一个是消杀烟雾,显然不能是dmb,只能是dsb;我们需要CPU1看到set_pte_at的动作先于tlbi的动作,所以这个屏障的范围应该是ISH;由于屏障需要保障的是set_pte_at的store,而不是load,所以方向是st,由此我们得出第一个barrier应该是:dsb + ish + st。
详细的流程我们可以参考下如下代码:

barrier2用的是dsb(ish),它保证了inner内的CPU都先看到了tlbi的完成;barrier3用的isb(),它保证了CPU fetch到PTE修正之后的指令。
结语
本文对Linux内核的内存屏障的原理和用法进行一些分析和实战,它并未覆盖内存屏障的全部知识,但是应该可应付工程里面90%以上的迷惘和困惑。由于作者水平有限,文中疏漏与错误在所难免,恳请读者朋友们海涵。本文完成之时,北半球正在告别烈日炙烤的夏季,南半球即将迎来姹紫嫣红的春天,愿所有人都有一个美好的未来。
- cpu
+关注
关注
68文章
10646浏览量
208785 - 内存
+关注
关注
8文章
2858浏览量
73378 - 软件
+关注
关注
69文章
4516浏览量
86551 - LINUX内核
+关注
关注
1文章
315浏览量
21548
原文标题:原理和实战解析Linux中如何正确地使用内存屏障
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
从硬件引申出内存屏障,带你深入了解Linux内核RCU
Linux的内存管理是什么,Linux的内存管理详解
Linux内核之内存映射原理分析
ARM体系结构之内存序与内存屏障
Linux内核内存管理架构解析

Linux内核地址映射模型与Linux内核高端内存详解
导致ARM内存屏障的原因究竟有哪些
内存屏障机制及内核相关源代码分析
高端内存的详解:linux用户空间与内核空间
可以了解并学习Linux内核的同步机制
干货:Linux内核中等待队列的四个用法
Linux内核源码分析-进程的哪些内存类型容易引起内存泄漏?






 工商网监
工商网监
评论