 基于谷歌中长尾item或user预测效果的迁移学习框架
基于谷歌中长尾item或user预测效果的迁移学习框架
推荐系统经常面临长尾问题,例如商品的分布服从幂率分布导致非常多的长尾样本只出现过很少的次数,模型在这部分样本上的效果比较差。对长尾样本增加权重,或者通过采样的方法增加长尾样本,又会影响数据分布,进而造成头部样本效果下降。针对这类问题,谷歌提出了一种可以实现头部样本知识迁移到尾部样本的迁移学习框架,使推荐系统中长尾预测问题效果得到显著提升,并且头部的预测效果也没有受到损失,实现了头部尾部双赢。
文中提出的迁移学习框架主要包括model-level transfer和item-level transfer。其中model-level transfer通过学习一个多样本模型和一个少样本模型,并学习一个二者参数的映射函数,实现模型参数上的迁移;item-level transfer通过对模型训练流程的优化,让映射函数同时能够学到头部item和尾部item之间的特征联系。
1
Model-level Transfer
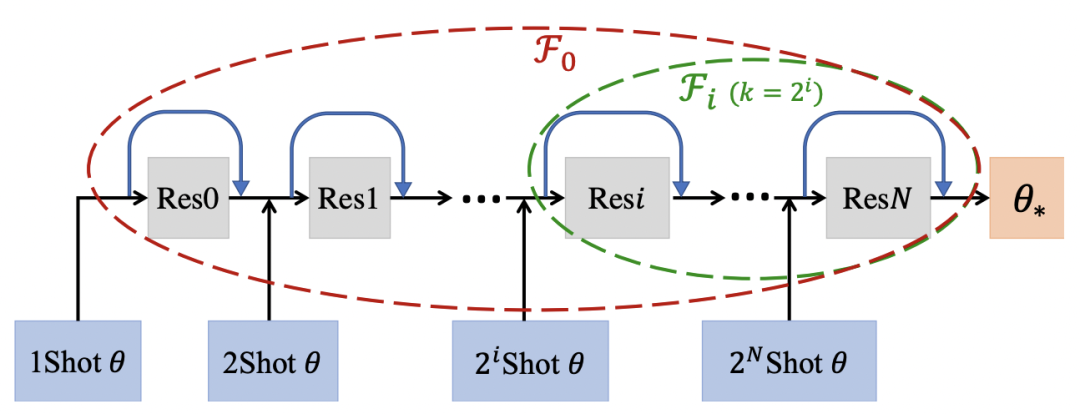
Model-level Transfer的核心思路是学习many-shot model和few-shot model的参数映射关系,这个思路最早来源于2017年NIPS上的一篇文章Learning to Model the Tail(NIPS 2017)。比如下面的例子中,living room是头部实体,可以利用living room结合不同的样本量,学到模型参数是如何从one-shot(theta1)变换到two-shot(theta2)一直到many-shot(theta*)。那么对于一个tail实体library,模型只能通过few-shot学到一个模型参数,但是可以利用在many-shot上学到的参数变化经验推导出library上的参数变化。通过不断增加数据,模型参数发生变化,模型学习的是数据增强的过程如何影响了模型参数变化。
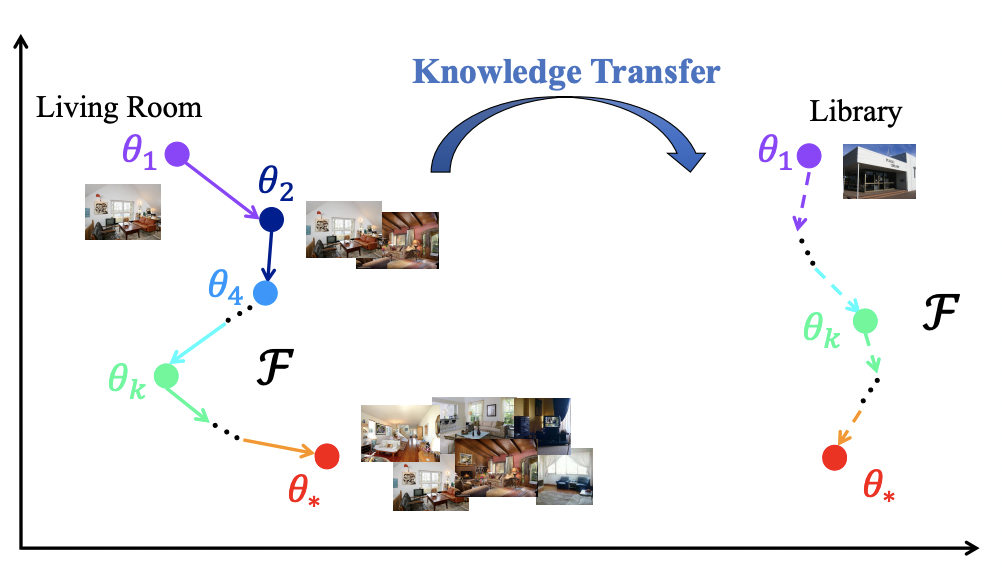
在推荐系统中也是同理,给定一个item和user的反馈信息,模型隐式的学习如何增加更多user的反馈信息帮助这个item的学习,也就是从少数据到多数据的模型参数变化过程。
基于上述思路,本文通过一个meta-learner学习这种参数随着shot增加的映射关系。首先构造两种类型的数据集,第一种数据是利用头部商品构造的many-shot训练数据,用来训练一个base-learner;第二种数据是在头部数据中进行下采样,vwin 得到的few-shot训练数据。Meta-learner是一个函数,输入few-shot模型的参数,预测出many-shot模型的参数,即学习这个映射关系,损失函数如下,第一项是预测many-shot参数的损失,第二项是在few-shot数据上模型的预测效果:
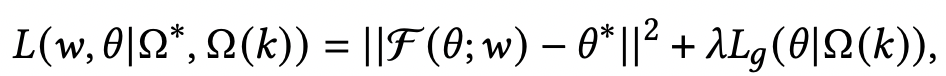
其中,本文主要优化的部分是base-learner在user和item网络中的最后一层参数,因为如果学习全局参数的映射关系,计算复杂度太高。
2
量Item-level Transfer
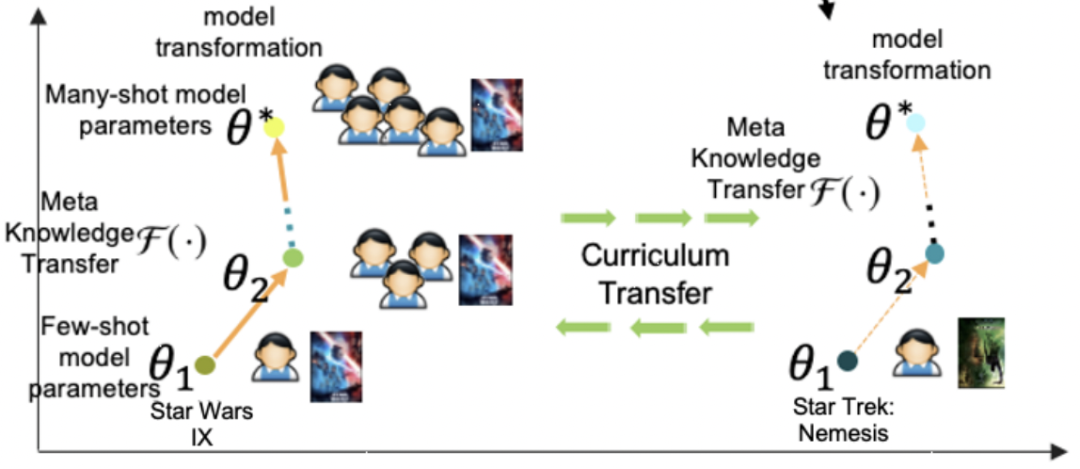
在model-level transfer中我们提到,需要构造一个many-shot数据集和few-shot数据集。一种常用的方法是根据头部数据(例如样本数量大于一定阈值的)构造many-shot数据,同时利用头部数据做下采样构造few-shot数据。但是在推荐系统中,尾部item的数量众多,只根据头部item这个参数的映射关系可能在尾部item上效果不好。因此本文提出了一种curriculum transfer的方法。
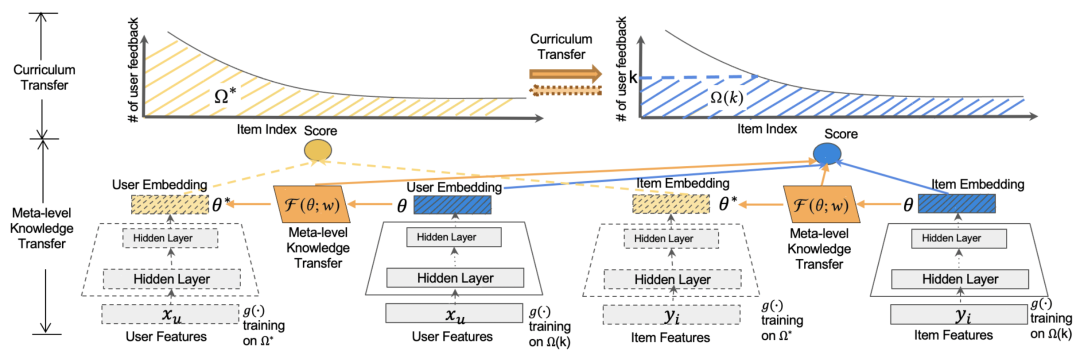
具体的,在数据集的构造上,many-shot使用了包括头部和尾部所有item的数据构成(如上图中的黄色区域),few-shot使用了头部item下采样加所有尾部item构成(如上图中的蓝色区域)。这种方式保证了many-shot和few-shot模型在训练过程中都能充分见到长尾样本,提升item表示的学习效果,同时也能在few-shot训练时,保证尾部数据的分布仍然是接近初始的长尾分布,缓解分布变化带来的bias。同时在损失函数中,引入了logQ correction,根据样本量平衡头部样本和尾部样本对模型的影响,曾经在Sampling-Bias-Corrected Neural Modeling for Large Corpus ItemRecommendations(2017)等论文中应用过。
3
模型预测
在预测过程中,会融合base-learner得到的user表示,以及经过meta-learner根据few-shot学到的参数融合到一起进行预测,通过一个权重平衡两个表示,公式如下:
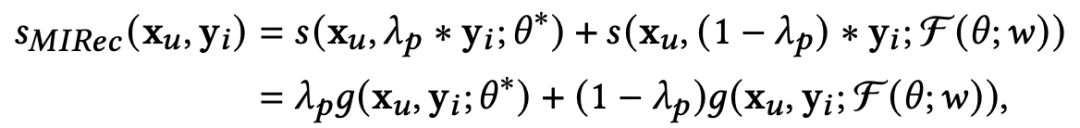
对于长尾user,也可以利用相似的方法解决。此外,文中也提出可以采用多阶段的meta-learner学习方法,例如从1-shot到2-shot再到many-shot,串行学习多个meta-learner,这与Learning to Model the Tail(NIPS 2017)提供的方法比较相似。
4
实验结果
作者在多个数据集上对比了一些解决长尾问题的方法效果,实验结果如下表。可以看到,本文提出的MIRec方法效果要明显好于其他方法。作者的实验基础模型是一个user侧和item侧的双塔模型,具体的长尾优化对比模型包括re-sampling类型方法(如上采样和下采样)、损失函数方法(如logQ校准、classbalance方法,二者思路都是在损失函数中引入不同样本频率加权样本)、课程学习方法(Head2Tail,即先在全量样本上预训练,再在尾部样本上finetune,Tail2Head是反过来的操作)、基于Meta-learning的方法(MeLU)。
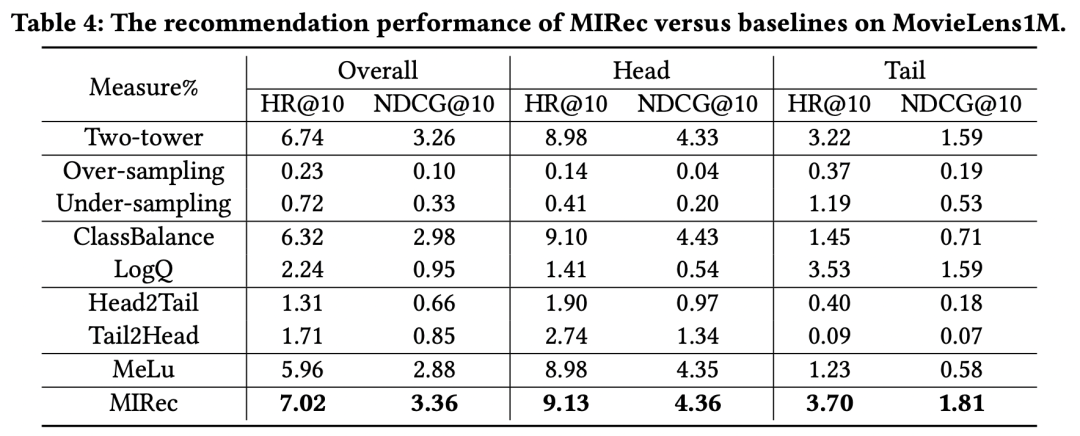
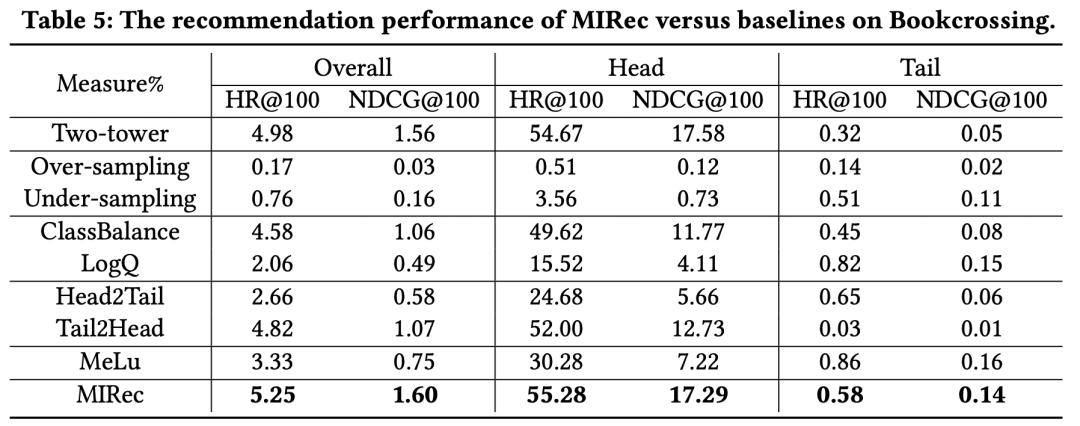
从上面的实验结果可以看出几个关键点。首先,sampling-based方法效果非常差,这主要是由于sampling改变了数据本身的分布,而推荐系统中,模型的效果对于数据分布是非常敏感的,使用真实分布的数据训练效果会更好。其次,基于loss加权的方法如ClassBalance和LogQ,对于长尾的效果提升非常明显,但是对于头部item有明显的负向影响。最后,MIRec在头部和长尾都实现了效果提升,这是其他模型很难做到的。
5
总结
本文介绍了谷歌提出的解决推荐系统中长尾item或user预测效果的迁移学习框架,通过many-shot到few-shot的参数规律变化学习,结合对数据分布的刻画,实现了头部、尾部双赢的推荐模型。
- 谷歌
+关注
关注
27文章
6067浏览量
104026 - 数据
+关注
关注
8文章
6670浏览量
88168 - 函数
+关注
关注
3文章
4214浏览量
61845
原文标题:谷歌MIRec:头部尾部双赢的迁移学习框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
迁移学习
卷积神经网络长尾数据集识别的技巧包介绍
谷歌FHIR标准协议利用深度学习预测医疗事件发生

谷歌发布机器学习框架:一个名叫NSL的神经结构学习框架
迁移学习Finetune的四种类型招式
解决长尾和冷启动问题的基本方法
一个基于参数更新的迁移学习的统一框架
一个通用的时空预测学习框架

谷歌使用机器学习模型来预测哪条路线最省油或最节能
深度学习框架连接技术
视觉深度学习迁移学习训练框架Torchvision介绍






 工商网监
工商网监
评论