 OLLVM和LLVM功能介绍
OLLVM和LLVM功能介绍
基础知识
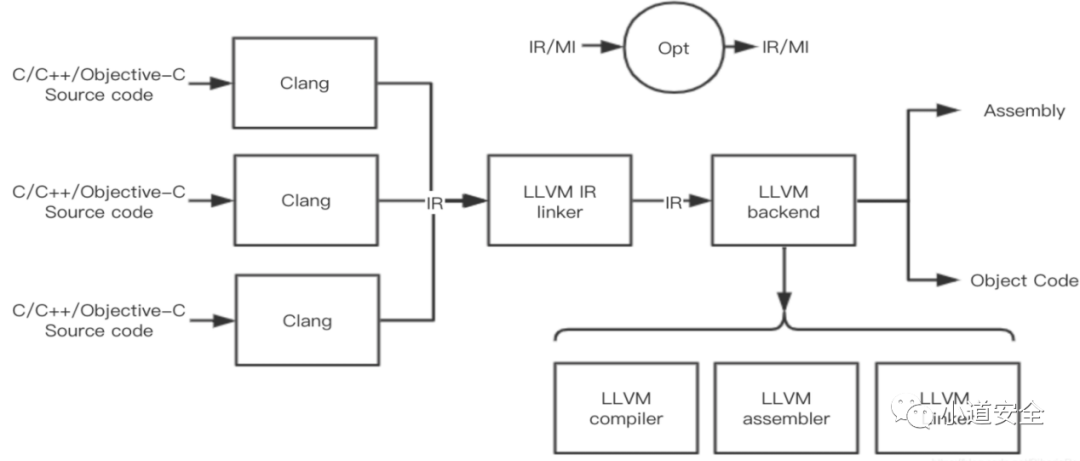
LLVM是lowlevel virtual machine的简称,它诞生于2003.10伊利诺伊大学香槟分校,创始人是ChrisLattner,它是一个完整的编译器框架,它兼容大部分主流开发语言例如:C, C++, Objective-C等等,它也兼容大部分主流的平台:x86, x86-64, PowerPC, PowerPC-64,ARM,Thumb等等。
(图片来源网络)
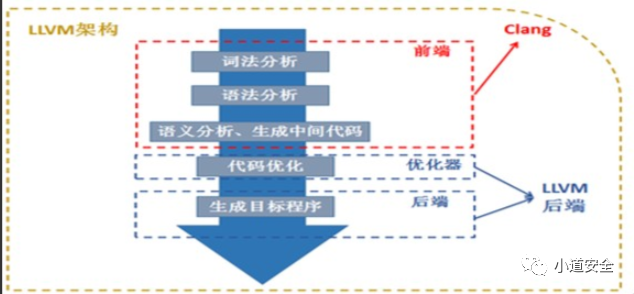
LLVM会先将源码生成为与目标机器无关的LLVMIR代码,然后把LLVMIR代码先优化,再向目标机器的汇编语言而转换。LLVM编译器主要细分为前端、中层优化和后端的3部分构成。
(图片来源网络)
OLLVM就是在LLVM的基础上增加了obfuscator(混淆), Obfuscator-LLVM (OLLVM) 是2010 年 6 月由 Yverdon-les-Bains 的瑞士西北应用科技大学安全实验室针对LLVM编译组件开发的代码混淆工具,该工具完全开源,这个OLLVM主要为了增加逆向工程的难度,保证代码的安全性。
Obfuscator-LLVM (OLLVM)集成了LLVM编译器,并且兼容LLVM支持的所有语言(C,C++, Objective-C, Ada and Fortran)和平台(x86, x86-64, PowerPC,PowerPC-64,ARM,Thumb,SPARC,Alpha,CellSPU,MIPS, MSP430, SystemZ,XCore)。
OLLVM的混淆原理,就是在不改变源代码功能前提下,将C或C++代码中的控制语句if、while、for、do等转换成switch分支语句。这样实现的优势是,它可以模糊switch中case代码块之间的关系,从而增加逆向分析代码难度。
混淆的具体实现思路,首先将要实现代码平坦化的函数分成多个基本块(就是case代码块)和一个入口块,并为每个基本块设置编号,并让这些基本块都有共同的前驱模块和后继模块。前驱模块主要是进行基本块的分发,后继模块的分发通过改变switch变量来实现。
OLLVM和LLVM主要的功能的代码差异点如下图所示
OLLVM功能介绍
OLLVM全面模式支持以下四种代码包含模式
1、-mllvm -fla: 控制流化扁平化
2、-mllvm -sub:指令替换
3、-mllvm -bcf: 控制流程
4、-mllvm -sobf: 字符串加密
以OLLVM保护后的功能效果都在文章的后部分进行展示。
-mllvm -fla中fla的全称:Control Flow Flattening,它也称为控制流扁平化,这个功能模式主要原理就是把一些if-else语句,嵌套成do-while语句。
它支持以下3种保护功能模式:
-mllvm -fla: 激活控制流扁平化
-mllvm -split:激活基本块分裂。一起使用时提高平整度。
-mllvm -split_num=3:如果激活通行证,则在每个基本块上应用 3 次。默认值:1
-mllvm -sub,它的全称Instructions Substitution,它又称为指令替换,这个的原理可以理解为就是不改变功能的前提下,将简单的指令替换成更复杂的指令,当有多个等效指令序列可用时候,会随机选择一个指令进行替换。这个混淆它并不会增强过多的安全性,因为它可以通过重新优化生成的代码轻松删除,如果选择使用随机生成器以不同数值作为种子,指令替换会在生成的二进制文件中带来多样性。
它支持以下的2种模式功能:
-mllvm -sub:激活指令替换
-mllvm -sub_loop=3:如果激活了传递,则在函数上应用3次。默认值:1
-mllvm -bcf,它的全称Bogus Control Flow,也称为虚假控制流。这个主要原理就是在当前基本块之前添加一个新的基本块用来修改函数调用图,这个新的基本块包含一个不透明的谓词,通过有条件地跳转到原来的基本块。原始的基本块也会被克隆并填充随机的垃圾指令。
这虚假控制流代码保护模式主要通过在不改变代码功能前提下往代码里面嵌套几层的判断逻辑,这种模式下会大大影响程序的性能,因为它在代码下混杂着真真假假的代码。
这个模式下它支持3种功能选项:
-mllvm -bcf: 激活伪造的控制流通道
-mllvm -bcf_loop=3: 如果 pass 被激活,在一个函数应用 3 次。默认值:1
-mllvm -bcf_prob=40:如果激活通行证,一个基本块将以 40% 的概率被混淆。默认值:30
-mllvm -sobf也称为字符串混淆,主要实现将代码中的字符串做加密,使得无法通过静态逆向方式直接看到字符串信息。
它主要支持2种功能模式选项:
-mllvm -sobf:编译时候添加选项开启字符串加密
-mllvm -seed=0xdeadbeaf:指定随机数生成器种子流程
OLLVM编译
编译OLLVM前需要以下的工具和代码:
1、OLLVM源码(基础之源)
https://releases.llvm.org/download.html
2、cmake工具(将OLLVM转换为sln项目)
https://cmake.org/download/
3、Visual studio工具(编译OLLVM源码)
https://visualstudio.microsoft.com/zh-hans/
在window环境下编译OLLVM的源码主要需要经历2个步骤
1、通过利用cmake将OLLVM的源码转换为sln的项目
可以通过利用cmake工具或者用命令行方式转换,下面以命令行方式转换的
cmake -Thost=x64 -G "Visual Studio 16" E:ollvm9obfuscator-llvm-9.0.1obfuscator-llvm-9.0.1
上面要主要的是Visual Studio 16这个代表你环境中安装的vs版本,我安装2019版本的,所以用它。
通过执行以上命令后就会出现下图的效果
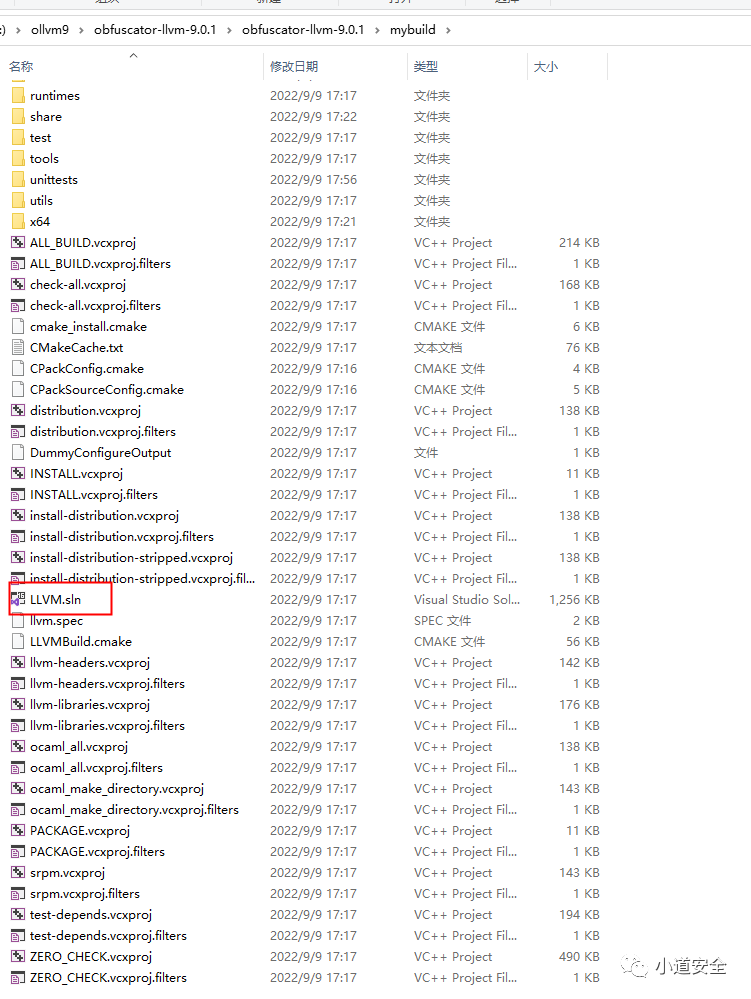
2、用Visual studio 2019 直接编译前面生成的OLLVM项目,主要编译Release版本。编译后正确情况下会生成bin和lib两个文件夹。
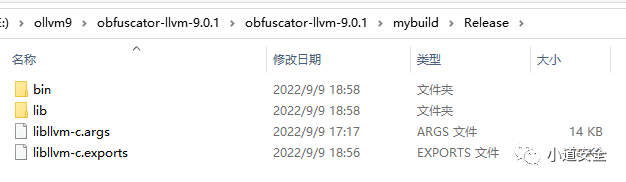
OLLVM集成
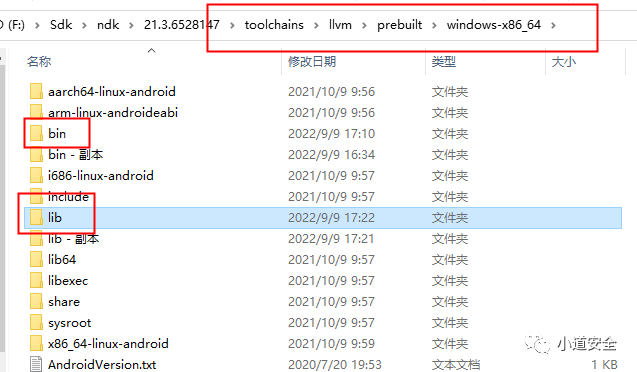
通过前面的编译后生成的bin和lib文件夹,集成到NDK中,并通过android studio编译器进行so代码保护的应用。
将vs编译生成后的bin和lib文件夹,替换到NDK中的llvm文件夹下面toolchainsllvmprebuiltwindows-x86_64(替换之前切记做下备份,万一出问题了还能回滚)
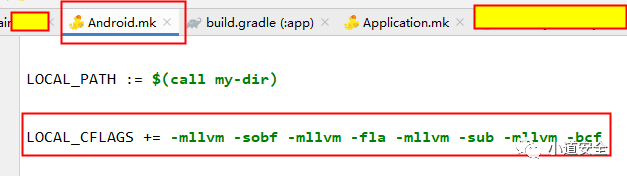
通过配置Android.mk文件进行设定需要对so文件采用什么方式的全局代码保护。
可能大家会觉得保护强度越强越好,代码虚拟化、字符串混淆、指令替换等等都给用下去,那样就安全了,其实不是这样的,这些强度虽然上去了但是会给项目带来非常大的负担。往往会带来负面性能影响。
个人建议:可以针对字符串做个混淆(-mllvm -sobf),外加指定核心函数进行做代码保护。这样强度也有了,对应用的性能影响方面也相对较小。
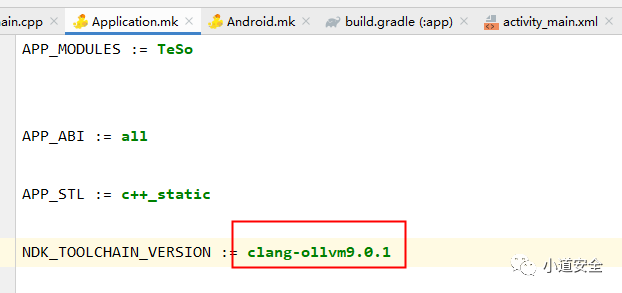
上图中Android.mk设置的保护方式属于全局的保护,设置后整个so就都会基于设置的保护。
通过配置Application.mk文件,进行指定ollvm的clang具体版本数据(这个具体版本数据也可以lib文件夹下clang文件夹下查看)。
OLLVM保护效果
为了更好展示分析ollvm保护后的效果,主要通过基于__attribute((__annotate__(("sub"))))这种方式,对指定函数进行做保护,而没有进行配置全局的保护。
下图的代码功能效果仅是为了测试OLLVM的虚假指令保护后的实现效果
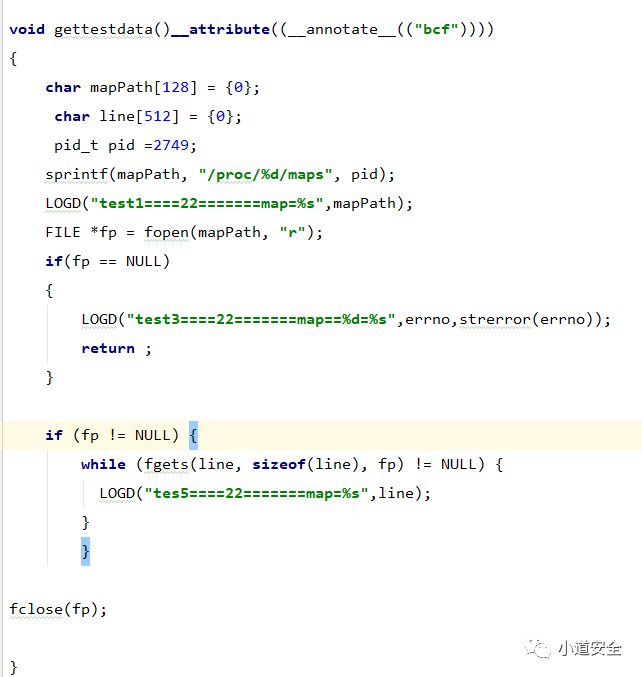
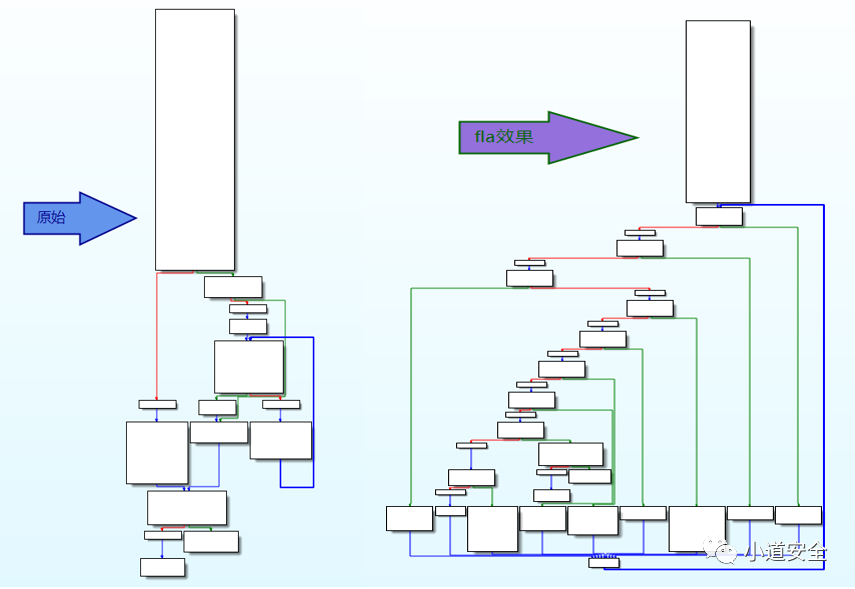
下图是基于IDA工具的原始和虚假控制流的代码保护流程图,可以看到代码的执行流程已被调整变得相对复杂化,这样就大大强化了代码的安全强度,这种逆向分析其代码至少静态分析起来就费劲了。
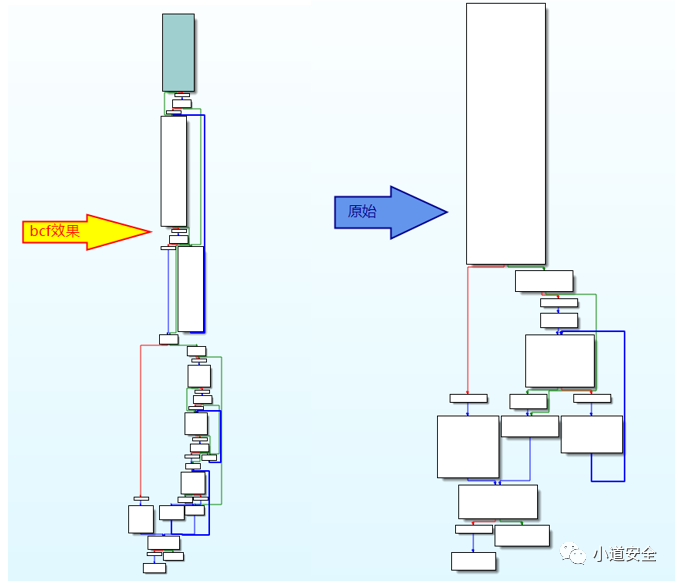
下图是通过指定函数进行设置指令替换的功能的代码展示

通过下图IDA静态的代码流程图可以很清晰分析到,它实际上代码流程是没有任何变化的,所以这种保护模式下的代码保护功能时没有很明显的效果的。
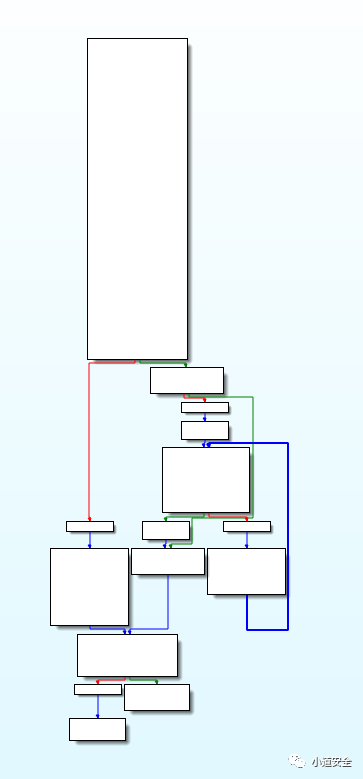
下图的代码是通过调用ollvm的控制流扁平化功能进行对函数保护的代码展示
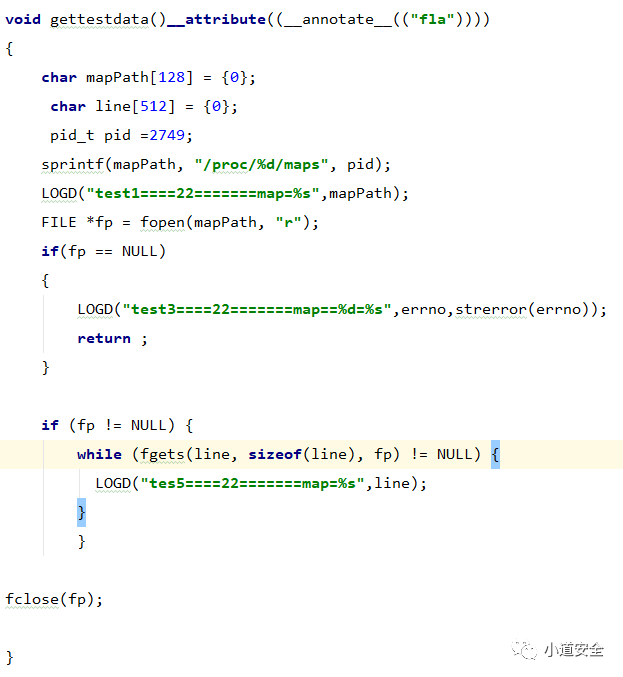
通过下图IDA的代码流程图,可以看到代码控制流扁平化保护后,整个流程就变得复杂化了。这就让代码的安全性上升一个层次了,这样逆向分析还原代码功能的成本就大大提高了。
小结
通过上文OLLVM的一系列的原理集成、编译、配置、集成、代码生成、效果展示,主要为了给SO代码的防破解防逆向增加点门槛,提高点安全性。这系列的代码保护对于专业搞逆向的人员来说,它们可以通过基于Trace、unicron、frida这些方式去还原和去除OLLVM的混淆保护。
对于代码的安全性思考,不过在安全攻防对抗的过程中防御一直属于被动状态的也是相对滞后的。安全防护也是随着对抗去不断去提高变强。
代码安全防护方面可以借助于OLLVM然后进行做定制魔改,现有的逆向工具更多是基于标准化进行做反汇编,那么我们可以对这些逆向工具做些防护(可以多个方案结合),然后调整成为一些非标准化的,这样会大大增加逆向分析的成本。
只要逆向分析成本超过所破解后所获取的收益,那么你的代码就相对安全了。
-
代码
+关注
关注
30文章
4779浏览量
68516 -
编译器
+关注
关注
1文章
1623浏览量
49107
原文标题:一种高端的APP代码保护方案
文章出处:【微信号:哆啦安全,微信公众号:哆啦安全】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问ubuntu 14.04 编译am57xx SDK , 发生nativesdk-ti-llvm3.6异常是为什么?
LLVM clang 公开 -std=c++23
在Swift中使用LLVM的四个要点

四个不同的系统上进行LLVM/Clang 6.0 和 5.0 的编译器Benchmark测试
LLVM终身程序分析与转换的编译框架的详细资料说明
微软与LLVM、Rust达成合作,将CFG支持添加到编译器

LLVM源码浅析-1

LLVM国际开源软件社区发布正式支持LoongArch架构的版本

什么是LLVM?LLVM的优势和特点有哪些?
使用LLVM-embedded-toolchain-for-Arm-17.0.1开发STM32





 工商网监
工商网监
评论