 基于几何单目3D目标检测的密集几何约束深度估计器
基于几何单目3D目标检测的密集几何约束深度估计器
摘要
由于深度信息的缺失,从单目图像估计物体的准确3D位置是一个具有挑战性的问题。之前的工作表明,利用目标的关键点投影约束来估计多个候选深度可以提高检测性能。然而,现有方法只能利用垂直边缘作为深度估计的投影约束。所以这些方法只利用了少量的投影约束,产生的深度候选不足,导致深度估计不准确。论文提出了一种可以利用来自任何方向边缘的密集投影约束方法。通过这种方式,论文使用了更多的投影约束并输出了更多的候选深度。此外,论文提出了一个图匹配加权模块来合并候选深度。本文提出的方法名为DCD(Densely Constrained Detector),在 KITTI 和 WOD基准上实现了最先进的性能。
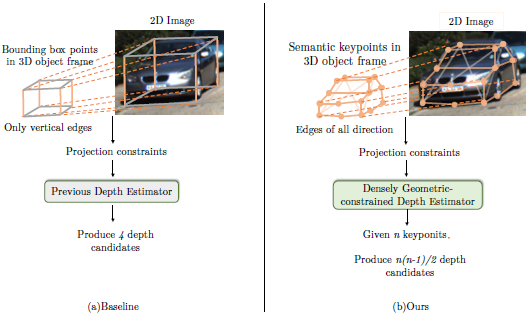
之前算法存在的问题在于它们的几何约束不足。具体来说,一些现有的方法估计2D边界框和3D边界框的高度,然后利用2D到3D高度投影约束生成目标的深度候选。最终的深度是通过对所有候选深度进行加权来生成的。如下图所示,该方法仅适用于垂直边缘,这意味着它们只使用少量约束和3D先验,导致深度估计的不准确。
方法
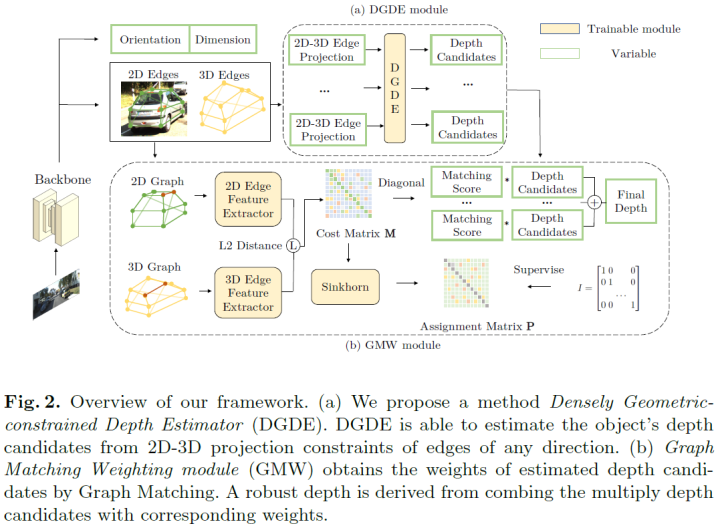
DCD的框架的如下图所示。DCD使用单阶段检测器从单目图像中检测目标。论文提出了密集几何约束深度估计器(DGDE,Densely Geometric-constrained Depth Estimator),它可以计算任何方向的2D-3D边缘的深度。DGDE可以有效地利用目标的语义关键点并产生更多的深度候选。此外,论文利用回归得到的2D边缘、3D边缘和方向作为2D-3D边缘图匹配网络的输入。所提出的图匹配加权模块 (GMW,Graph Matching Weighting module) 匹配每个2D-3D边缘并输出匹配分数。通过将多个深度与其相应的匹配分数相结合,论文最终可以为目标生成一个稳健的深度。
Geometric-based 3D Detection Definition
基于几何的单目3D目标检测通过2D-3D投影约束估计目标的位置。具体来说,网络预测目标的尺寸(),旋转角。假设一个目标有n个语义关键点,论文回归第i个关键点在图像坐标中的2D坐标和object frame中的3D坐标。object frame的坐标原点是目标的中心点。给定n个语义2D-3D关键点投影约束,解决3D目标位置是一个超定问题,它是用于将点云将从object frame转换到camera frame的平移向量。生成每个目标的语义关键点的方法改编自。论文通过PCA建立了一些汽车模型,并通过从点云和2D mask中分割出来的3D点云来细化模型。在获得关键点后,就可以使用DGDE从关键点投影约束中估计目标的深度。
Densely Geometric-constrained Depth Estimation
虽然以前的深度估计方法[51]只考虑了垂直边缘,但DGDE可以处理任意方向的边缘。因此,论文能够利用更多的约束来估计每个深度候选的深度。
该方法基于关键点从3D空间到2D图像的投影关系。第i个关键点的3D坐标在object frame中定义,并通过以下等式投影到2D图像平面上:
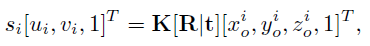
其中是第i个关键点的深度,K是相机内参,K,R,t 表示为:
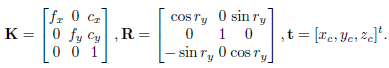
通过上述两式,第i个关键点的投影约束方程记为:
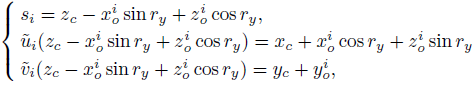
第j个关键点投影约束方程与上式类似,进一步可以从第i个、第 j 个关键点投影约束中得到深度估计:
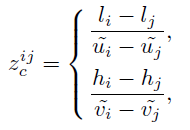
这个方程表明深度可以通过任意方向边缘的投影约束来计算。
给定n个关键点,论文生成m=n(n-1)/2 个深度候选。与此同时,不可避免地会遇到一些低质量的深度候选。因此,需要适当的加权方法来集成这些深度候选。
Depth Weighting by Graph Matching
利用DGDE估计目标的深度候选时,目标的最终深度可以根据根据估计质量进行加权:
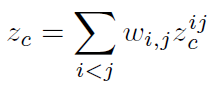
接下来介绍论文提出的新的加权方法——Graph Matching Weighting module (GMW)。
Graph Construction and Edge Feature extraction:论文构造了2D关键点图和3D关键点图。3D关键点图与2D关键点图基本一致,唯一的区别是顶点坐标是2D坐标还是3D坐标。2D和3D边缘特征提取器[47]如下所示:
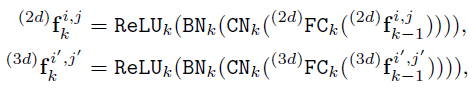
FC、CN、BN、ReLU 分别表示全连接层、Context Normalization [47]、Batch Normalization 和 ReLU。值得一提的是,Context Normalization 提取了所有边的全局信息。
Graph matching layer:给定提取的2D和3D边缘特征,根据在边缘s上的2D特征和边缘t上的3D特征之间的L2距离计算如下损失:
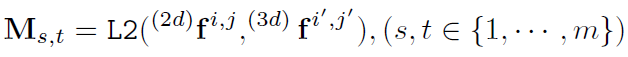
然后论文将M作为Sinkhorn layer[4]的输入来获得分配矩阵P。Sinkhorn layer通过最小化下述目标函数来迭代优化P:
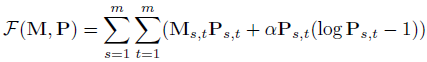
Loss function:设计如下所示的回归损失来监督最终的加权深度,并使用分类损失来监督图匹配:
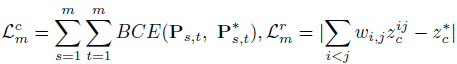
实验结果
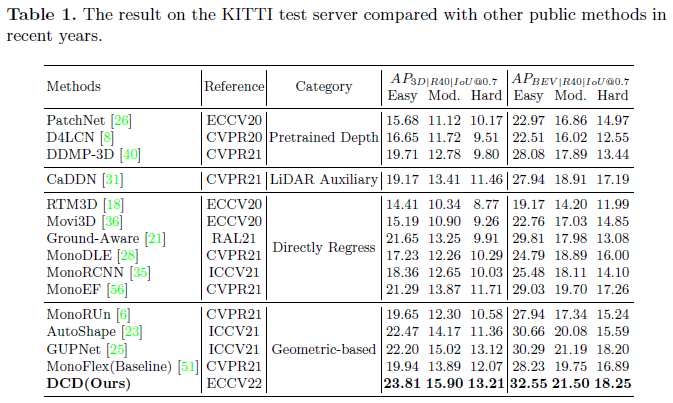
KITTI上的实验结果,优势比较明显。
可视化:

更多的实验结果如下表所示:
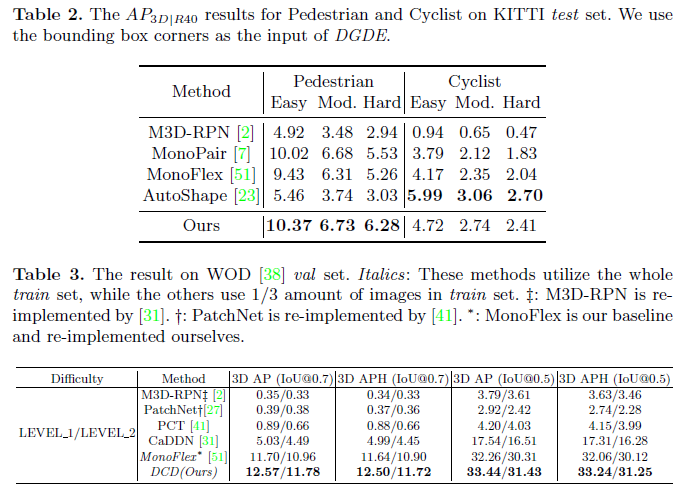
消融实验
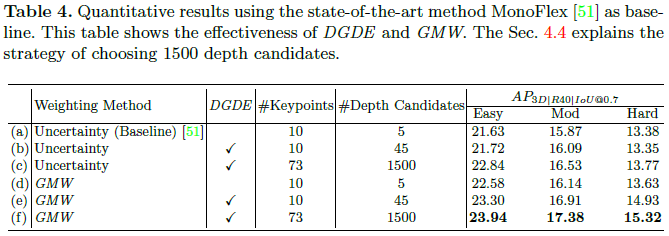
DCD可以比基线更准确地估计深度。
GMW和边数量的消融实验

关于DCD和AutoShape的讨论
尽管DCD和AutoShape都利用多个关键点来估计目标的位置,但存在如下关键差异:
AutoShape直接使用所有2D-3D关键点投影约束来求解对象目标深度。DCD则从每个边缘约束中求解一个深度候选。因此,DCD的边缘约束不仅数量多,而且比关键点约束的阶数更高;
审核编辑:郭婷
-
检测器
+关注
关注
1文章
863浏览量
47676 -
3D
+关注
关注
9文章
2875浏览量
107480
原文标题:ECCV 2022 | 用于单目3D目标检测的密集约束深度估计器
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度解析自动驾驶的双目3D感知视觉方案
如何通俗理解视觉定位?带你看懂对极几何与基本矩阵
最受欢迎的三种深度传感器
3D设计太耗时?赶紧试试浩辰3D软件中的几何约束关系命令!
实时3D艺术最佳实践-几何指南
基于几何约束的视频帧间线段特征匹配算法
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度

关于钢块3D几何测量的实用性说明
介绍第一个结合相对和绝对深度的多模态单目深度估计网络
公差分析VS尺寸链计算-DTAS 3D几何数据导入
一种利用几何信息的自监督单目深度估计框架

如何搞定自动驾驶3D目标检测!






 工商网监
工商网监
评论