 使用第三代NVIDIA NVSwitch升级多GPU互连
使用第三代NVIDIA NVSwitch升级多GPU互连
人工智能和 高性能计算 ( HPC )正在推动对每个 GPU 之间具有高速通信的更快、更可扩展互连的需求。
这个 第三代 NVIDIA NVSwitch 设计用于满足这种通信需求。最新的 NVSwitch 和 H100 张量核心 GPU 使用第四代 NVLink ,这是 NVIDIA 最新的高速点对点互连。
第三代 NVIDIA NVSwitch 旨在为 NVLink 交换机系统提供节点内或节点外部 GPU 的连接。它还将硬件加速与多播和 NVIDIA 可扩展分层聚合和缩减协议( SHARP ) 在网络缩减中。
NVIDIA NVSwitch 也是 NVLink 开关 网络设备 ,允许创建最多连接 256 个的群集 NVIDIA H100 Tensor Core GPUs 以及 57.6TB / s 的全对全带宽。与 NVIDIA 安培架构 GPU 上的 HDR InfiniBand 相比,该设备可提供 9 倍的二等分带宽。
高带宽和 GPU 兼容操作
AI 和 HPC 工作负载的性能需求继续快速增长,需要扩展到多节点、多 – GPU 系统。
大规模提供卓越性能需要每个 GPU 之间的高带宽通信, NVIDIA NVLink 规范旨在与 NVIDIA GPU 协同工作,以实现所需的性能和可扩展性。
例如, NVIDIA GPU 的线程块执行结构有效地为并行化 NVLink 架构提供了支持。 NVLink 端口接口也被设计为尽可能地匹配 GPU L2 缓存的数据交换语义。
比 PCIe 快
NVLink 的一个关键优势是它提供了比 PCIe 大得多的带宽。第四代 NVLink 每个通道的带宽为 100 Gbps ,是 PCIe Gen5 的 32 Gbps 带宽的三倍多。可以组合多个 NVLink 以提供更高的聚合通道数,从而产生更高的吞吐量。
比传统网络更低的开销
NVLink 被专门设计为高速点对点链路互连 GPU ,产生比传统网络更低的开销。
这使得传统网络中的许多复杂网络功能(如端到端重试、自适应路由和数据包重新排序)可以在增加端口数的情况下进行权衡。
网络接口更加简单,允许将应用程序层、表示层和会话层功能直接嵌入到 CUDA 本身中,从而进一步减少通信开销。
NVLink 世代
随着 NVIDIA P100 GPU 的首次推出, NVLink 继续与 NVIDIA GPU 体系结构同步发展,每一种新体系结构都伴随着新一代 NVLink 。
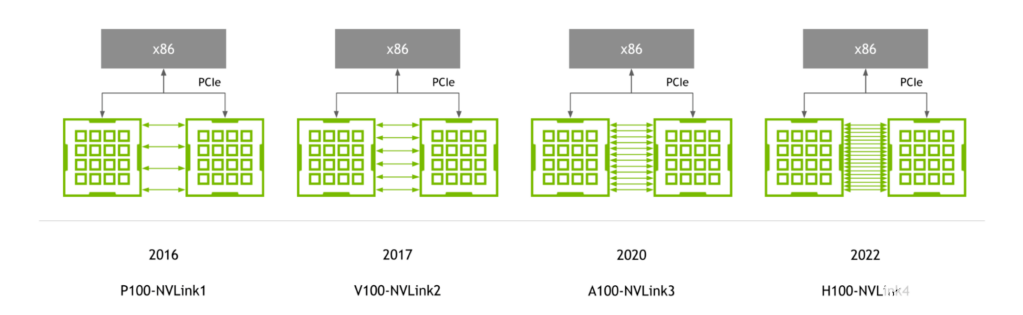
图 1.与 GPU 同步演进的 NVLink 生成
第四代 NVLink 为每个 GPU 提供 900 GB / s 的双向带宽,比上一代高 1.5 倍,比第一代 NVLink 高 5.6 倍。
支持 NVLink 的服务器代
NVIDIA NVSwitch 首先与 NVIDIA V100 Tensor Core GPU 和第二代 NVLink 一起推出,实现了服务器中所有 GPU 之间的高带宽、任意连接。
NVIDIA A100 Tensor Core GPU 引入了第三代 NVLink 和第二代 NVSwitch ,使每 CPU 带宽和减少带宽都增加了一倍。
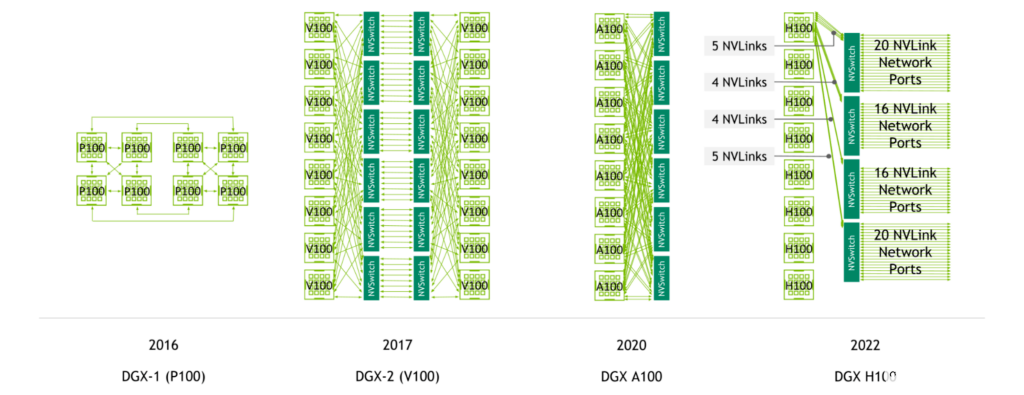
图 2.NVLink总而言之跨 DGX 服务器代的连接
使用第四代 NVLink 和第三代 NVSwitch ,具有八个 NVIDIA H100 Tensor Core GPU 的系统具有 3.6 TB / s 的二等分带宽和 450 GB / s 的缩减操作带宽。与上一代相比,这两个数字分别增加了 1.5 倍和 3 倍。
此外,使用第四代 NVLink 和第三代 NVSwitch 以及外部 NVIDIA NVLink 交换机,现在可以以 NVLink 速度跨多台服务器进行多 GPU 通信。
迄今为止最大、最快的交换机芯片
第三代 NVSwitch 是迄今为止最大的 NVSwitch 。它使用为 NVIDIA 定制的 TSMC 4N 工艺构建。该芯片包含 251 亿个晶体管,比 NVIDIA V100 Tensor Core GPU 的晶体管多,面积为 294 毫米2封装尺寸为 50 mm x 50 mm ,共有 2645 个焊球。
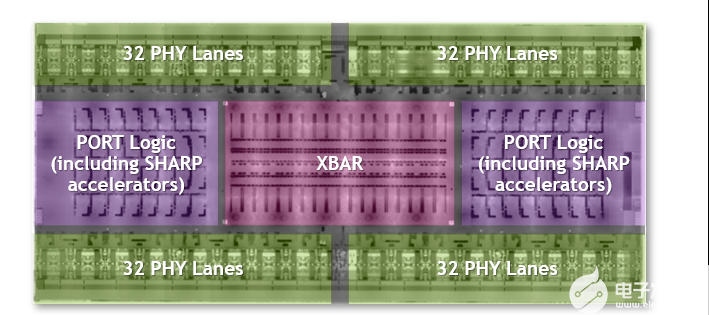
图 3.第三代 NVSwitch 芯片的特点包括它是最大的 NVSwitch ,具有最高的带宽和 400 GFlops 的 FP32 夏普
NVLink 网络支持
第三代 NVSwitch 是 NVLink 交换机系统的关键使能器,它能够以 NVLink 速度实现 GPU 跨节点的连接。
它包含与 400 Gbps 以太网和 InfiniBand 连接兼容的物理( PHY )电气接口。随附的管理控制器现在支持附加的八进制小尺寸可插拔( OSFP )模块,每个机架具有四个 NVLINK 。使用自定义固件,可以支持活动电缆。
还添加了其他前向纠错( FEC )模式,以增强 NVLink 网络性能和可靠性。
还添加了安全处理器,以保护数据和芯片配置免受攻击。该芯片提供了分区功能,可以将端口子集隔离到单独的 NVLink 网络中。扩展的遥测功能还支持 InfiniBand 风格的监控。
带宽加倍
第三代 NVSwitch 是我们迄今为止带宽最高的 NVSwitch 。
使用 50 Gbaud PAM4 信令,每个差分对的带宽为 100 Gbps ,第三代 NVSwitch 在 64 个 NVLink 端口上提供 3.2 TB / s 的全双工带宽(每个 NVLink x2 )。与前一代相比,它在系统中提供了更多带宽,同时还需要更少的 NVSwitch 芯片。第三代 NVSwitch 上的所有端口都支持 NVLink 网络。
SHARP 集合和多播支持
第三代 NVSwitch 包括一系列用于快速加速的新硬件模块:
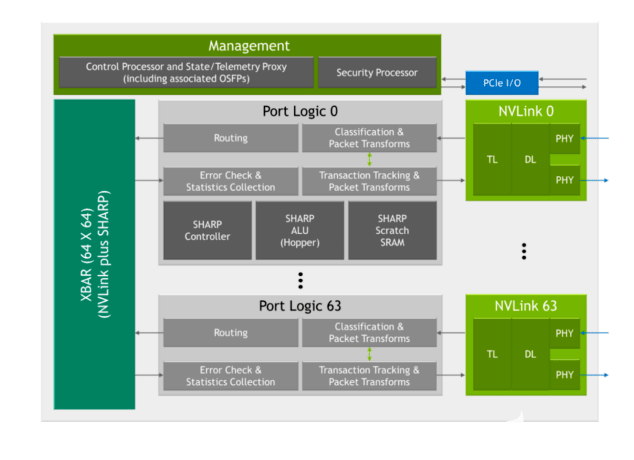
图 4.第三代 NVSwitch 框图
敏锐的控制器
夏普算术逻辑单元( ALU )与 NVIDIA Hopper 架构
嵌入式 ALU 提供高达 400 次的 FP32 吞吐量,并被添加为直接在 NVSwitch 中执行缩减操作,而不是通过系统中的 GPU 。
这些 ALU 支持多种运算符,如逻辑运算符、最小/最大运算符和加法运算符。它们还支持有符号/无符号整数、 FP16 、 FP32 、 FP64 和 BF16 等数据格式。
第三代 NVSwitch 还包括一个 SHARP 控制器,可并行管理多达 128 个 SHARP 组。芯片中的纵横带宽已经增加,以承载额外的夏普相关交换。
所有这些都降低了操作兼容性
NVIDIA 夏普的一个关键用例是 AI 培训中常见的所有 reduce 操作。当使用多个 GPU 训练网络时,批次被分成更小的子批次,然后分配给每个单独的 GPU 。
每个 GPU 通过网络参数处理各自的子批次,产生参数的可能变化,也称为局部梯度这些局部梯度被组合并协调以产生全局梯度,每个 GPU 应用于它们的参数表。该平均过程也称为全减操作。
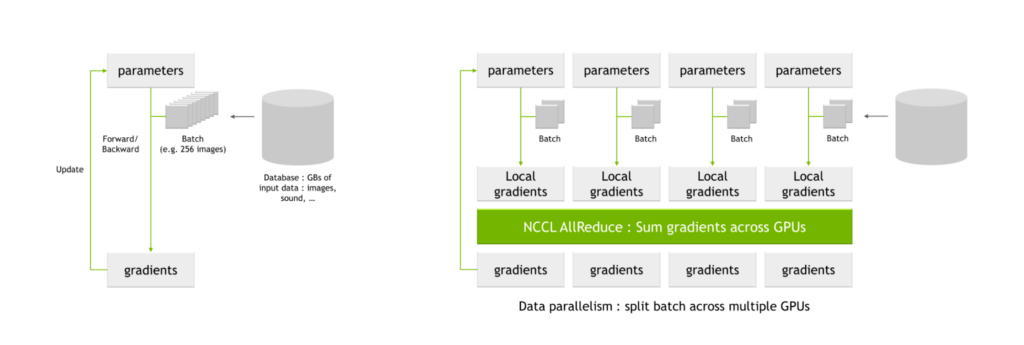
图 5. NCCL 人工智能培训中的 AllReduce 与关键通信密集型操作
NVIDIA Magnum IO 是数据中心 IO 加速多节点通信的架构。它使 HPC 、 AI 和科学应用程序能够在使用 NVLink 和 NVSwitch 扩展的新的大型 GPU 集群上扩展性能。
Magnum IO 包括 NVIDIA 集体通信库 ( NCCL ),它实现了丰富的多 – GPU 和多节点集合基元,包括所有 reduce 。
NCCL AllReduce 将局部梯度作为输入,将其划分为子集,收集特定级别的所有子集,并将其分配给单个 GPU 。 GPU 然后对该子集执行协调过程,例如对所有 GPU 的局部梯度值求和。
在此过程之后,生成一组全局梯度,然后将其分配给所有其他 GPU 。
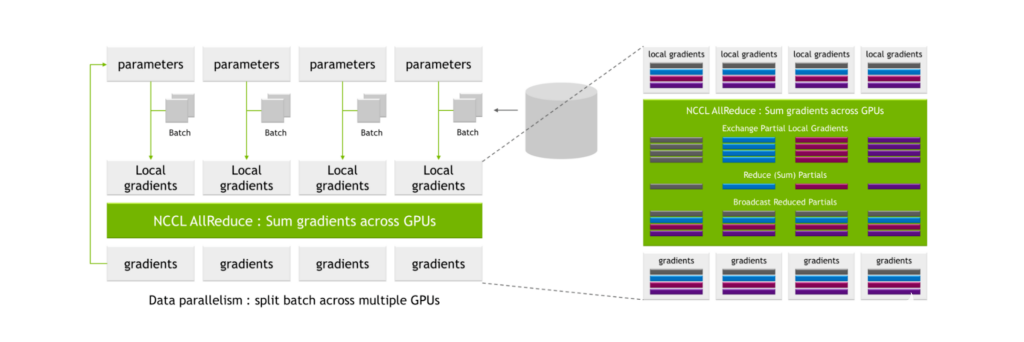
图 6.具有数据交换和并行计算的传统 all-reduce 计算
这些过程是高度通信密集型的,并且相关联的通信开销可以显著延长训练的总时间。
使用 NVIDIA A100 Tensor Core GPU 、第三代 NVLink 和第二代 NVSwitch ,发送和接收部分的过程将产生2N读到(在哪里N是 GPU 的编号)。广播结果的过程产生 2N为 2 写N阅读和 2N在每个 GPU 接口处写入,或 4N总操作数。
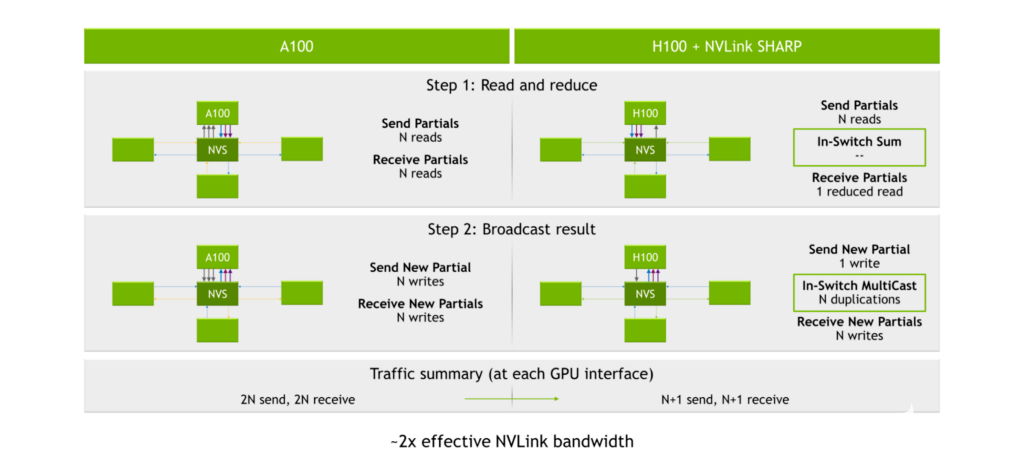
图 7.NVLink 急剧加速
夏普引擎位于第三代 NVSwitch 内部。 GPU 将数据发送到第三代 NVSwitch 芯片,而不是将数据分配给每个 GPU 并让[ZFK55]执行计算。芯片然后执行计算,然后将结果发送回。这导致总共 2N+ 2 个操作,或将执行全部减少计算所需的读/写操作的数量大约减半。
提高大型模型的性能
随着 NVLink 交换机系统提供的带宽是 InfiniBand 的 4.5 倍,大规模模型培训变得更加实用。
例如,当使用 14 TB 嵌入表训练推荐引擎时,与使用 InfiniBand 的 H100 相比,我们预计使用 NVLink 交换系统的 H100 在性能上会有显著提升。
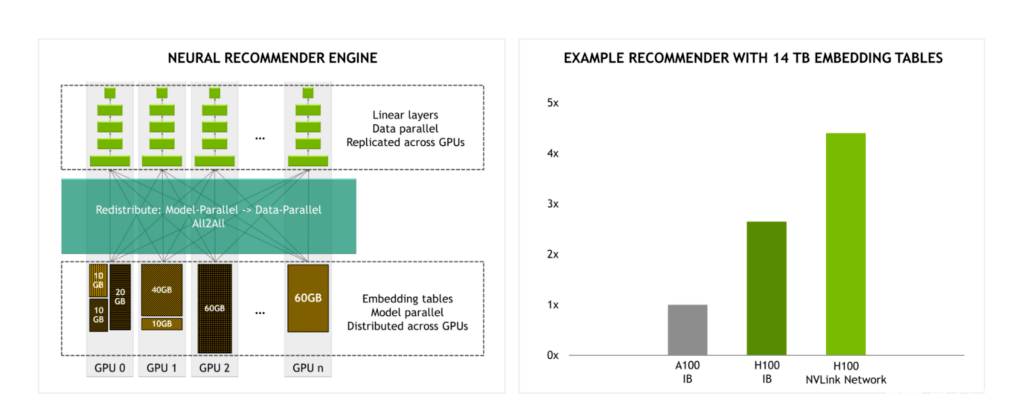
图 8.NVLink 交换机系统的带宽是最大 InfiniBand 带宽的 4.5 倍
NVLink 网络
在以前几代的 NVLink 中,当通过 NVLink 相互通信时,每个服务器都有自己的本地地址空间,由服务器内的 GPU 使用。通过 NVLink 网络,每台服务器都有自己的地址空间,当 GPU 通过网络发送数据时使用该地址空间,从而在共享数据时提供隔离并提高安全性。该功能利用了最新 NVIDIA Hopper GPU 架构中内置的功能。
当 NVLink 在系统引导过程中执行连接设置时, NVLink 网络连接设置是通过软件的运行时 API 调用执行的。这使得网络能够在不同服务器联机以及用户进出时进行动态重新配置。
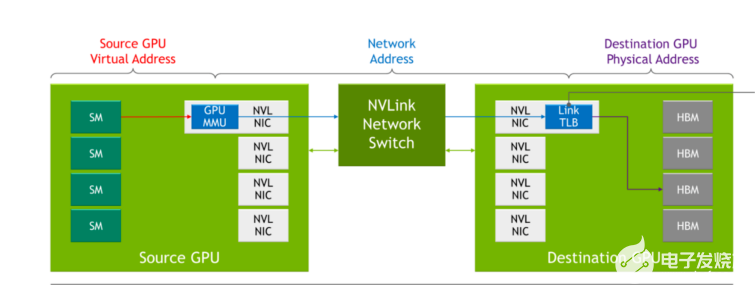
图 9.与 NVLink 相比, NVLink 交换机系统的变化
表 1 显示了传统网络概念如何映射到 NVLink 网络中的对应概念。
DGX H100
NVIDIA DGX H100 是基于最新 NVIDIA H100 张量核心 GPU 的 DGX 系列系统的最新版本,包含:
8x NVIDIA H100 Tensor Core GPU ,具有 640GB 的聚合 GPU 内存
4x 第三代 NVIDIA NVSwitch 芯片
18x NVLink 网络 OSFPs
72 个 NVLink 提供的 3.6 TB / s 全双工 NVLink 网络带宽
8x NVIDIA ConnectX-7 以太网/ InfiniBand 端口
2x 双端口 BlueField-3 DPU
双蓝宝石 RAPIDS CPU
支持 PCIe 第 5 代
全带宽服务器内 NVLink
在 DGX H100 中,系统内的八个 H100 张量核心 GPU 中的每一个都连接到所有四个第三代 NVSwitch 芯片。业务通过四个不同的交换平面发送,使得链路聚合能够实现系统中 GPU 之间的全部到全部带宽。
半带宽 NVLink 网络
通过 NVLink 网络,一台服务器中的所有八个 NVIDIA H100 Tensor Core GPU 可以向其他服务器中的 H100 Tessor Core [ZFK55]订阅 18 个 NVLink 。
或者,一台服务器中的四个 H100 Tensor Core GPU 可以向其他服务器中的 H100 Tensor Core [ZFK55]完全订阅 18 个 NVLINK 。这种 2 : 1 的锥度是为了平衡带宽、服务器复杂性和该技术实例的成本而做出的权衡。
使用夏普,交付的带宽相当于全带宽 AllReduce 。
多轨以太网
在一个服务器中,所有八个 GPU 都独立地支持来自其专用 400 GB NIC 的 RDMA 。对于非 NVLink 网络设备, 800 GB / s 的聚合全双工带宽是可能的。
DGX H100 叠加
DGX H100 是 DGX H1100 叠加的构建块。
由八个计算机架构建,每个机架具有四台 DGX H100 服务器。
共有 32 个 DGX H100 节点,包含 256 个 NVIDIA H100 张量核心 GPU 。
提供高达峰值 AI 计算的一个 exaflop 的峰值。
NVLink 网络在整个 256 GPU 范围内提供 57.6 TB / s 的二等分带宽。此外,跨所有 32 个 DGX 和相关 InfiniBand 交换机的 ConnectX-7 提供了 25.6 TB / s 的全双工带宽,可在 pod 内使用或扩展多个叠加。
NVLink 开关
DGX H100 SuperPOD 的一个关键使能器是基于第三代 NVSwitch 芯片的新型 NVLink 交换机。 DGX H100 SuperPOD 包括 18 个 NVLink 交换机。
NVLink 交换机采用标准的 1U 19 英寸外形,极大地利用了 InfiniBand 交换机设计,并包括 32 个 OSFP 机架。每个交换机包含两个第三代 NVSwitch 芯片,提供 128 个第四代 NVLink 端口,总带宽为 6.4 TB / s 。
NVLink 交换机支持带外管理通信和一系列布线选项,如无源铜缆。通过自定义固件,还支持有源铜缆和光纤 OSFP 电缆。
使用 NVLink 网络进行扩展
与具有 256 DGX A100 的 DGX A10 SuperPOD 相比,具有 NVLink 网络的 H100 SuperPOD 能够显著增加二等分并减少操作带宽
GPU 。
单个 DGX H100 可提供 1.5 倍于单个 DGX A100 的二等分和 3 倍于其缩减操作的带宽。在 32 种 DGX 系统配置中,这些加速比分别增长到 9 倍和 4.5 倍,每种配置总共 256 GPU 。
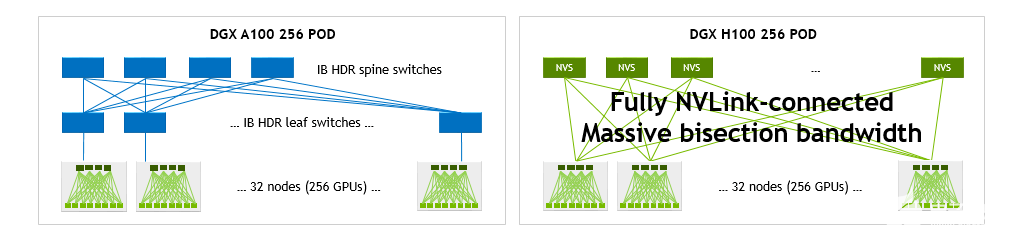
图 10.DGX A100 POD 和 DGX H100 POD 网络拓扑
通信密集型工作负载的性能优势
对于具有高通信强度的工作负载, NVLink 网络的性能优势非常显著。在 HPC 中,由于 HPC SDK 和 Magnum IO 中的通信库中已设计了多节点缩放,因此 Lattice QCD 和 8K 3D FFT 等工作负载可以带来巨大的好处。
当训练大型语言模型或具有大型嵌入表的推荐者时, NVLink 网络也可以提供显著的提升。
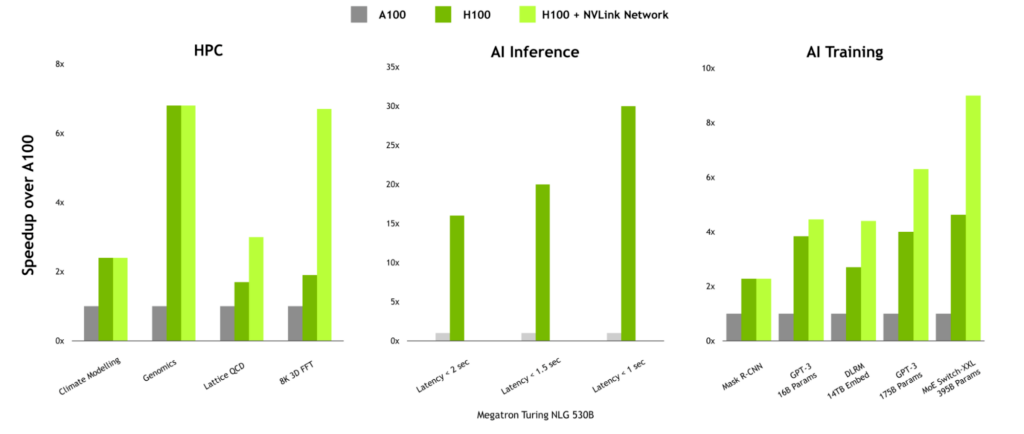
图 11.取决于通信强度的 NVLink 交换机系统优势
大规模交付性能
为 AI 和 HPC 提供最高性能需要全栈、数据中心规模的创新。高带宽、低延迟互连技术是实现大规模性能的关键因素。
第三代 NVSwitch 为服务器内 GPU 之间的高带宽、低延迟通信以及服务器节点之间的全 NVLink 速度的全对全 GPU 通信带来了下一次飞跃。
Magnum IO 与 CUDA 、 HPC SDK 和几乎所有深度学习框架集成工作。它使大型语言模型、推荐系统等人工智能软件和 3D FFT 等科学应用程序能够使用 NVLink 开关系统在多个 GPU 节点上进行扩展。
关于作者
Ashraf Eassa 是NVIDIA 加速计算集团内部的高级产品营销经理。
Alex Ishii 是 NVIDIA 的杰出架构师,在过去的 8 年中,他从 NVIDIA Research 获得了 NVSwitch 和 NVLink 网络概念,并将其引导到一些最先进的 NVIDIA 计算平台的基石中。
Ryan Wells 于 2018 年加入 NVIDIA ,目前是数据中心系统工程团队的架构总监。他和他的团队帮助为 AI 和 HPC 定义高端 NVIDIA 数据中心产品,包括 HGX 和 DGX 。在加入 NVIDIA 之前,他曾在前沿 CPU 和 SOC 领域担任过多种角色,包括电源/热管理、 FW 开发和软件架构。 Ryan 获得普林斯顿大学电气工程学士学位,并拥有 22 项专利。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4978浏览量
102979 -
gpu
+关注
关注
28文章
4729浏览量
128885 -
服务器
+关注
关注
12文章
9123浏览量
85318
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论