 实现无晶体管CIM架构的器件物理特性
实现无晶体管CIM架构的器件物理特性
宾夕法尼亚大学(UPenn)研究人员最近使用新材料展示了vwin 内存计算电路如何为人工智能计算提供可编程解决方案。
为了推进人工智能,宾夕法尼亚大学的研究人员最近开发了一种用于数据密集型计算的新型内存计算 (CIM) 架构。CIM 在大数据应用方面具有诸多优势,UPenn研究小组在生产小型、强大的 CIM 电路方面迈出了第一步。
在本文中,我们将更深入地了解 CIM 的原理以及使研究人员能够实现无晶体管 CIM 架构的器件物理特性。
为什么要内存中计算?
传统上,计算主要依赖于基于冯诺依曼架构的互连设备。在此架构的简化版本中,存在三个计算构建:内存、输入/输出 (I/O) 接口和中央处理单元 (CPU)。
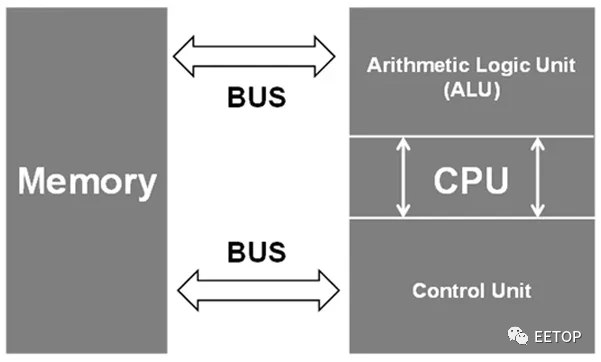
冯诺依曼架构,其中内存与CPU不位于同一位置。图片由Nature提供
每个构建块都可以根据 CPU 给出的指令与其他构建块交互。然而,随着 CPU 速度的提高,内存访问速度会大大降低整个系统的性能。这在需要大量数据的人工智能等数据密集型用例中更为复杂。此外,如果内存未与处理器位于同一位置,则由于光速限制会进一步降低性能。
所有这些问题都可以通过 CIM 系统来解决。在 CIM 系统中,内存块和处理器之间的距离大大缩短,内存传输速度可能会更高,从而可以实现更快的计算。
氮化钪铝:内置高效内存
UPenn 的 CIM 系统利用氮化钪铝(AlScN) 的独特材料特性来生产小型高效的内存块。AlScN 是一种铁电材料,这意味着它可能在外部电场的响应下产生极化。通过改变施加的电场超过一定的阈值,铁电二极管(FeD)可以被编程到低电阻或高电阻状态(分别为LRS或HRS)。
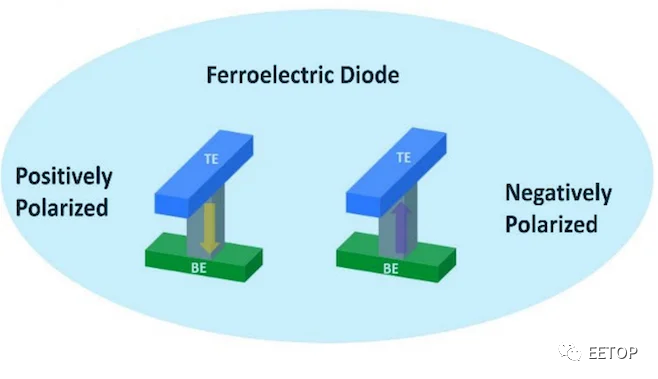
显示两种极化状态的 AlScN 铁电二极管插图。每个状态都表现出低电阻或高电阻状态,使其成为一种有效的记忆形式。图片由UPenn ESE提供
除了作为存储单元的可操作性之外,AlScN 还可用于创建没有晶体管的三元内容可寻址存储 (TCAM) 单元。TCAM 单元对于大数据应用非常重要,因为使用冯诺依曼架构搜索数据可能非常耗时。使用 LRS 和 HRS 状态的组合,研究人员实现了一个有效的三态并联,所有这些都没有使用晶体管。
使用无晶体管 CIM 阵列的神经网络
为了展示 AlScN 执行 CIM 操作的能力,UPenn 小组开发了一个使用 FeD 阵列的卷积神经网络 (CNN)。该阵列通过对输入电压产生的输出电流求和来有效地完成矩阵乘法。权重矩阵(即输出电流和输入电压之间的关系)可以通过修改单元的电导率来调整到离散水平。这种调谐是通过偏置 AlScN 薄膜以表现出所需的电导来实现的。
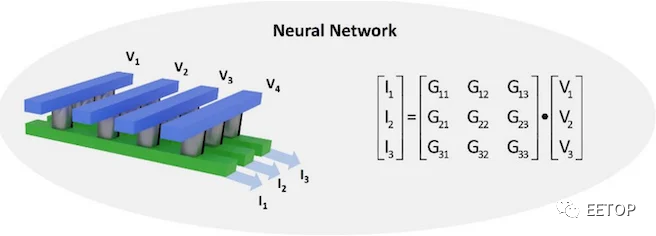
由 AlScN FeD 阵列组成的神经网络。通过调整每个 FeD 的电导率,可以修改权重/电导矩阵以实现矩阵乘法。图片由UPenn ESE提供
AlScN CNN 仅使用 4 位电导率分辨率就成功地从MNIST 数据集中识别出手写数字,与 32 位浮点软件相比,性能仅下降约为 2%。此外,由于没有晶体管,架构简单且可扩展,使其成为未来需要高性能矩阵代数的人工智能应用的优秀计算技术。
打破冯诺依曼瓶颈
在其存在的大部分时间里,人工智能计算主要是一个软件领域。然而,随着数据变得更加密集,冯诺依曼瓶颈对系统有效计算的能力产生了更深的影响,使得非常规架构变得更加有价值。
基于AlScN FeDs的模拟CIM系统消除了训练和评估神经网络的一个主要延迟原因,使其更容易在现场部署。AlScN器件与现有硅硬件集成的多功能性可能会提供一种突破性的方法,将人工智能集成到更多的领域。
审核编辑:刘清
-
晶体管
+关注
关注
77文章
9682浏览量
138078 -
TCAM
+关注
关注
0文章
19浏览量
14061 -
CIM
+关注
关注
1文章
87浏览量
14848
原文标题:无晶体管的存内计算架构
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
晶体管反相器的原理及应用
单结晶体管的工作原理和伏安特性

晶体管的基本工作模式
GaN晶体管的应用场景有哪些
GaN晶体管和SiC晶体管有什么不同
晶体管处于放大状态的条件是什么
晶体管电流的关系有哪些类型 晶体管的类型





 工商网监
工商网监
评论