 一文看懂 DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
一文看懂 DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
编辑推荐
在 9 月举行的 GTC 大会上,NVIDIA产品经理 Gautham Sholingar 以《合成数据生成:加速自动驾驶汽车的开发和验证》为题,完整地介绍了 NVIDIA 过去一年在长尾场景训练的最新进展和相关经验,特别是探讨开发者如何使用 DRIVE Replicator生成多样化的合成数据集,以及准确的真值数据标签,从而加速自动驾驶汽车的开发和验证。该讲座内容干货满满,引发了行业的广泛关注和讨论。本文对此次分享的精华内容进行汇总和整理,以帮助大家更好地了解 DRIVE Replicator,以及自动驾驶感知算法的合成数据生成。

图 1
在过去的一年中,NVIDIA 在使用DRIVE Replicator生成用于训练自动驾驶感知算法的合成数据集方面取得了积极的进展。图 1 展示了目前 NVIDIA 正在攻克的一些长尾场景挑战:
第一行左侧图,倒车摄像头附近的弱势道路使用者(VRU)。对于任意自动驾驶感知算法而言,VRU 都是一个重要的对象类别。在本例中,我们专注于检测倒车鱼眼摄像头附近的儿童。由于现实世界中的数据采集和数据标记相当具有挑战性,因此这是一个重要的安全用例。
第一行中间图,事故车辆检测。自动驾驶感知算法需要接触到罕见和不常见的场景,才有助于使对象检测算法变得可靠。现实世界数据集里的事故车辆少之又少。DRIVE Replicator 可帮助开发人员创建各种环境条件下的意外事件(例如翻车),从而帮助训练此类网络。
第一行右侧图,交通标志检测。在其他一些情况下,手动标注数据既耗时,又容易出错。DRIVE Replicator 可帮助开发人员生成各种环境条件下数百个交通标志和交通信号灯的数据集,并快速训练网络以解决现实世界的多样性问题。
最后,在城市环境中,有许多对象并不常见,例如特定的交通道具和某些类型的车辆。DRIVE Replicator 可帮助开发人员提高数据集里这些罕见对象的出现频率,并借助目标合成数据来帮助增强现实世界的数据采集。
以上的这些功能,正在通过 NVIDIA DRIVE Replicator 实现。
了解 DRIVE Replicator 及其关联生态
DRIVE Replicator 是DRIVESim工具套件的一部分,可用于自动驾驶仿真。
DRIVE Sim 是 NVIDIA 基于Omniverse构建的、非常领先的自动驾驶汽车模拟器,可大规模地进行物理精准的传感器仿真。开发人员可以在工作站上运行可重复的仿真,然后在数据中心或云端扩展为批量模式。DRIVE Sim 是基于USD等强大的开放标准构建的模块化平台,支持用户通过 Omniverse 扩展程序引入自己的功能。
DRIVE Sim 上包括 DRIVE Replicator 等多个应用。DRIVE Replicator 主要提供一系列专注于合成数据生成的功能,用于自动驾驶汽车的训练和算法验证。DRIVE Sim 和 DRIVE Constellation 还支持各个级别的自动驾驶全栈仿真,包括软件在环、硬件在环和其他在环仿真测试(模型、植物、人类,以及更多)。
DRIVE Sim 和传统自动驾驶仿真工具的不同之处是在创建合成数据集时,传统的自动驾驶仿真工具往往结合专业的游戏引擎来进行,来还原足够真实的场景。但是,对于自动驾驶仿真而言,这是远远不够的,还需要处理包括物理准确性、可重复性和规模性等核心诉求。

图 2
在进一步介绍 DRIVE Replicator 之前,先为大家介绍几个关联概念(如图 2),特别是 Omniverse,以帮助大家更好地理解与 DRIVE Replicator 相关的底层技术支撑。
了解 NVIDIA 用于大规模仿真的引擎 Omniverse。Omniverse 基于由Pixar公司开发的 USD(Universal Scene Description,一种用于描述虚拟世界的可扩展通用语言)而构建。USD 是整个仿真和仿真各个方面(包括传感器、3D 环境)的单一真值数据源,这些完全通过 USD 构建的场景允许开发人员对仿真中的每个元素进行分层式的访问,为后续生成多样化的合成数据集奠定基础。
Omniverse 提供实时性的光线追踪效果,可为 DRIVE Sim 中的传感器提供支持。RTX 是 NVIDIA 在计算图形领域重要的先进技术之一,利用优化的光线追踪 API ,该 API 专注于物理准确性,可确保对摄像头、激光雷达、毫米波雷达和超声传感器的复杂行为(例如多次反射、多路径效应、滚动快门和镜头失真)进行原生建模。
NVIDIA Omniverse 是一个易于扩展的开放式平台,专为虚拟协作和物理级准确的实时模拟打造,能够在云端或数据中心运行工作流,可实现多GPU和节点并行渲染和数据生成。
Omniverse 和 DRIVE Sim 采用开放式、模块化设计,围绕此平台已经形成了一个庞大的合作伙伴生态系统。这些合作伙伴可提供 3D 素材、传感器、车辆和交通模型、验证工具等
Omniverse 协作的核心是 Nucleus,Nucleus 具有数据存储和访问控制功能,它能够充当多个用户的集中式内容仓库,支持 DRIVE Sim 将 Runtime 与内容解耦,改善版本控制,并为所有素材、场景和元数据创建单个参考点。
DRIVE Sim 是一个平台,NVIDIA 采取生态合作方式来搭建该平台,让合作伙伴都能为这个通用平台贡献自己的力量。目前 DRIVE Sim 已经建立一个庞大的合作伙伴生态系统,涉及 3D 资产、环境传感器模型、验证等多个领域。借助 DRIVE SimSDK,合作伙伴可以轻松引入自己的传感器、交通和车辆动态模型,并扩展其核心仿真功能。开发者不仅能在 Omniverse 中编写扩展程序,轻松添加新功能,还能享受到在通用平台上进行开发的好处——Omniverse 已连接多个关键合作伙伴,他们提供了与自动驾驶开发相关的重要工作流。
如何用 DRIVE Replicator 生成合成数据集和真值数据
接下来,将为大家解释以上的这些内容如何组合起来,以及 DRIVE Replicator 生成合成数据的五个主要工作步骤(如图 3):Content(内容 )— DRIVE Sim Runtime — Sensing(感知)— Randomization(域随机化)— Data Writers(数据写入器)。
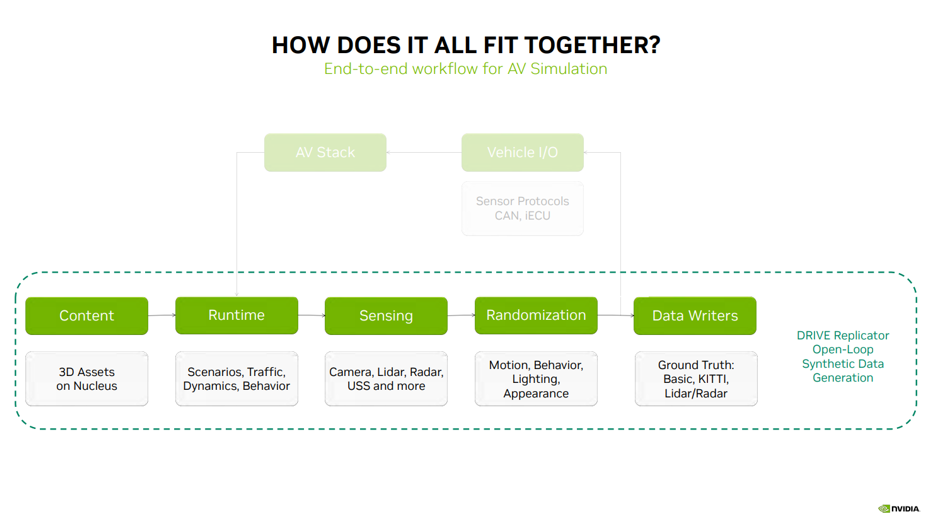
图 3
仿真流程的第一步是存储在 Nucleus 服务器上的 3D 内容和素材。这些素材会被传送至 DRIVE Sim Runtime,后者是执行场景、交通模型、车辆动态和行为的核心技术。DRIVE Sim Runtime 可与基于 RTX 光线追踪技术的摄像头、激光雷达、毫米波雷达和 USS 的感知技术结合使用。下一步是通过运动、行为、照明和外观的随机化,为数据引入多样性。对于闭环仿真,下一步通常由传感器协议、CAN消息和虚拟 ECU(向自动驾驶栈发送重要信息以闭环)组成的车辆 I/O 将仿真连接到自动驾驶栈。
对于合成数据生成,这则是一个开放的循环流程,这个流程会将随机化的传感器数据发送给数据写入器,而这些数据写入器可输出用于训练自动驾驶感知算法的真值标签。以上的这些步骤代表了合成数据生成的完整工作流。
1
Content(内容)
上文提到,仿真流程的第一步是存储在 Nucleus 服务器上的 3D 内容和素材。这些内容来源于哪里?如何获取?有什么标准或者要求?
过去几年,NVIDIA 与多个内容合作伙伴合作,建立了一个庞大的 3D 资产提供商生态系统,这些素材包括车辆、道具、行人、植被和 3D 环境,随时可在 DRIVE Sim 中使用。
有一点需要注意的是,即便您从市场上获得了这些资产,也不意味着就可以开始仿真工作,您还需要让这些资产为仿真做好准备,而这就是 SimReady 的用武之地。
扩展内容的一个重要部分是与 3D 资产提供商合作,并为他们提供所需的工具,以确保在将资产引入 DRIVE Sim 时遵循某些约定、命名、资产绑定(asset rigging)、语义标签(semantic labels)和物理特性。
SimReady Studio 帮助内容提供商将其现有的资产转换可以加载到 DRIVE Sim 上、仿真就绪的 USD 资产,包括 3D 环境、动态资产和静态道具。
那么,什么是 SimReady?您可以理解为它是一个转换器,有助于确保 DRIVE Sim 和 Replicator 中的 3D 资产准备好支持端到端的vwin 工作流程。SimReady 有几个关键要素,包括:
每项资产必须遵循一套关于方向、命名、几何形状等约定的规范,以确保一致性;
语义标签和定义明确的本体(ontology),用于注释资产的每个元素。这对于生成用于感知的真值标签至关重要;
支持刚体物理和动力学,使生成的数据集看起来逼真,并从运动学角度缩小仿真与现实之间的差距;
下一步是确保资产遵循特定的材料和命名约定,以确保资产为 RTX 光线追踪做好准备,并对激光雷达、毫米波雷达和超声波传感器等有源传感器产生真实的响应;
另一个常见方面是装配 3D 资产,从而实现照明变化、门驱动、行人步行操作等功能;
最后一部分是实时高保真传感器仿真的性能优化。
基于以上的理解,一起来看看如何使用 SimReady studio 获取可用于 DRIVE Sim 的资产的过程。
假设这个过程是从 3D 市场购入资产开始。第一步是将此资产导入到 SimReady Studio。这也可以批量完成,或者批量导入多个资产来完成这个步骤。
导入后,这些内容资产的材质名称会更新,它们的材质属性也会更新,拓展至包含反射率、粗糙度等方面的属性。
这对于确保渲染数据质量的物理真实性,以及确保材质系统与所有 RTX 传感器类型(而不仅仅是在可见光谱中运行的传感器类型)的交互非常重要。
下一步涉及更新语义标签和标记。为什么这一步很重要?拥有正确的标签意味着使用资产生成的数据可用于训练 AV 算法。此外,DRIVE Sim 和 Omniverse 使用 Nucleus 作为中央资产存储库。Nucleus 上有数以千计的内容资产,拥有可搜索的标签以及相关的缩略图将帮助新用户更容易找到某个资产。
接下来,开始定义对象的碰撞体积和几何形状,并从物理角度观察该内容资产的行为方式。然后修改对象的物理和质量属性,从而来创建预期的行为。
整个过程的最后一步是验证资产,以确保这些内容资产符合正确的约定。仿真就绪的 USD 资产现在可以保存并重新导入至 NVIDIA Omniverse 和 DRIVE Sim。通过 USD 构建场景的最大优点是,在前面的步骤中创建的所有元数据都与最终资产一起传输,并分层链接到主要对象的 USD,为后续生成多样化的合成数据集奠定基础。
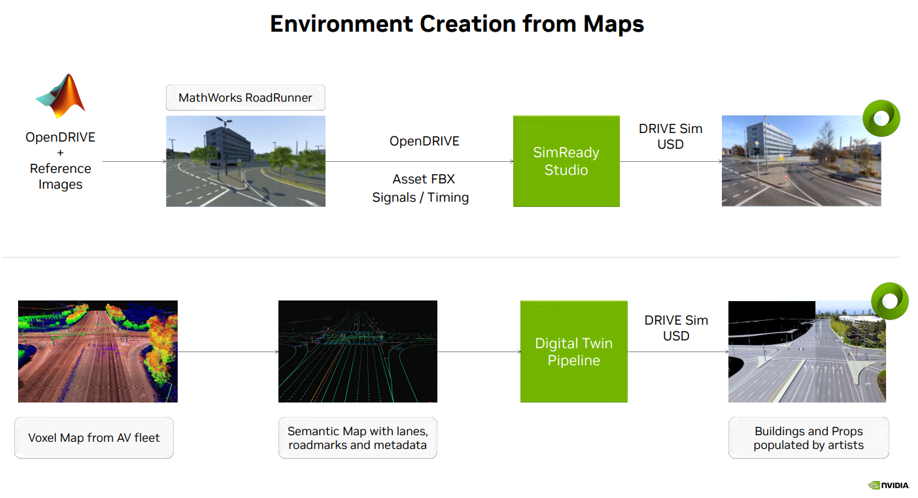
图 4
回到自动驾驶汽车仿真内容创建,从地图数据创建环境通常有几种方法(见图 4)。一种是选择使用MathWorks的 Roadrunner 工具在一个开放的 NVIDIA DRIVE map(多模式地图平台)上创建 3D 环境。然后将该步骤的输出结果,以及语义地图信息、信号时序等传输到 SimReady Studio ,该 3D 环境即可转换为可以加载到 DRIVE Sim 上的 USD 资产。
另一种选择,使用来自自动驾驶车队的体素地图数据并提取语义地图信息,例如车道、路标和其他元数据。这些信息通过数字孪生创建,生成可以加载到 DRIVE Sim 上的 USD 资产。
以上两类的 USD 环境,将被用于支持自动驾驶汽车端到端(E2E)仿真测试以及合成数据生成工作流。
2
DRIVE Sim Runtime
接下来为大家介绍仿真的第二步——DRIVE Sim Runtime,它奠定了我们在 DRIVE Replicator 中用于生成合成数据集的所有功能的基础。
DRIVE Sim Runtime 是开放式、模块化的可扩展组件。这在实践中意味着什么(见图 5)?
第一,它基于场景构建,在这些场景中开发者可定义场景中的对象的特定位置、运动和交互。这些场景可在Python中或使用场景编辑器 UI 进行定义,并可以保存以供日后使用。
第二,它支持通过 DRIVE Sim SDK 与自定义车辆动态包集成,既可以作为流程中的步骤,也可以作为与 DRIVE Sim 2.0 的共同仿真。
第三,交通模型。DRIVE Sim 拥有丰富的车辆模型界面,借助 Runtime,开发者可以引入自己的车辆动态或配置现有的基于规则的交通模型。
第四,动作系统,其中包含预定义的丰富动作库(例如车道变更)、可用于创建不同对象相互交互场景的时间触发器等。
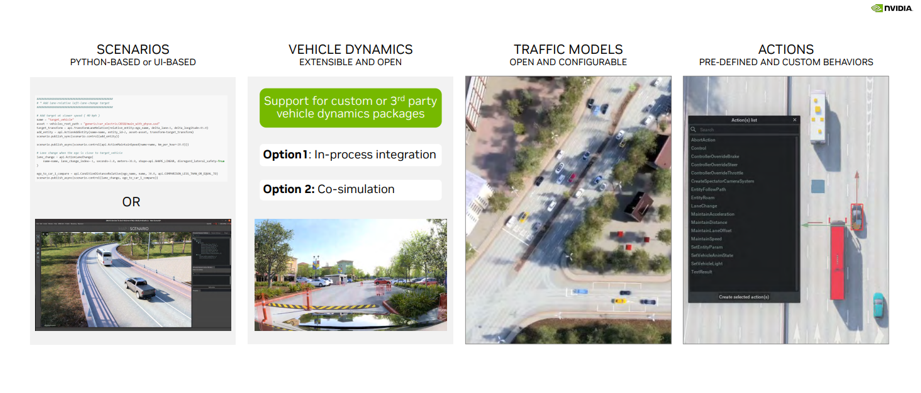
图 5
到这里简单回顾一下前面的内容:仿真流程第一步,经过 SimReady 转化的、仿真就绪的 3D 内容和素材,被存储在 Nucleus 服务器上。第二步,这些素材会被传送至 DRIVE Sim Runtime,后者是执行场景、交通模型、车辆动态和行为的核心技术,为后面生成合成数据集的所有功能奠定基础。
3
Sensing(感知)
在生成数据之前,需使用传感器来设置目标测试车辆。使用 Ego Configurator 工具,开发者可选择特定车辆并将其添加到场景中。
此外,开发者还可以在场景中移动车辆,并为车辆添加传感器。Ego 配置器工具支持通用和 Hyperion 8 传感器。
将传感器添加到车辆后,开发者还可以更改 FOV、分辨率、传感器名称等参数,并在车辆上直观地配置传感器位置。
用户还可以从传感器 POV 中查看预览,并在 3D 环境中实现视野可视化,然后再创建数据生成场景。
这个工具可以帮助开发者快速进行不同配置的原型设计,并将感知任务所能达到的覆盖范围可视化。
4
Randomization(域随机化)
现在简要介绍一下仿真流程的第四步,域随机化,如何通过运动、行为、照明和外观的随机化,为数据引入多样性。
这会涉及到创建场景的另一种方法,使用 Python。DRIVE Replicator 的 Python API 允许开发者查询开放的 NVIDIA DRIVE Map,并以可感知情景的方式放置一系列静态和动态资产。一些随机发生器将重点关注如何将自主车辆从某一点传送到下一点,如何在自主车辆周围产生对象,并由此生成不同的合成数据集。这些听起来很复杂的操作都能轻松实现,因为用户可以直接控制 USD 场景和该环境中的所有对象。
在创建用于训练的合成数据集时,另一个重要步骤是引入 3D 场景外观变化的能力。上文也提到过 USD 的强大功能,比如通过 USD 构建的场景允许开发人员对仿真中的每个元素进行分层式的访问。SimReady 的API 借助 USD 可以快速设置场景中的特征。
下面看一个示例(见图 6):路面有些湿,但在我们设置不同的参数时,路面潮湿程度会发生变化。我们可以对太阳方位角和太阳高度角等方面进行类似的更改,以在一系列环境条件下生成逼真的数据集。
另一个要点是开启照明和外观变化的能力,所有的这些变化都可以通过 SimReady API 和 USD 实现。

图 6
DRIVE Sim 的一个主要优势是 RTX 传感器工作流,它支持各种传感器(见图 7),包括用于摄像头、激光雷达、普通雷达和 USS 的通用和现成模型。此外,DRIVE Sim 还全面支持 NVIDIA DRIVE Hyperion 传感器套件,允许用户在虚拟环境中开始算法开发和验证工作。
此外,DRIVE Sim 拥有功能强大、用途多样的 SDK,支持合作伙伴使用 NVIDIA 的光线追踪 API 来实现复杂的传感器模型,同时保护其 IP 和专有算法。多年来,这个生态系统不断发展壮大,而且 NVIDIA 正与合作伙伴合作,将成像雷达、FMCW 激光雷达等新形态的传感器引入到 DRIVE Sim 中。

图 7
5
Data Writers(数据写入器)
现在,把重点转移到生成真值数据,以及如何实现这些信息的可视化。这涉及到仿真流程的最后一个步骤,数据写入器。在这个流程中,会将随机化的传感器数据发送给数据写入器,而这些数据写入器可输出用于训练自动驾驶感知算法的真值标签。
数据写入器是一个 Python 脚本,用于生成训练自动驾驶感知算法所需的真值标签。
NVIDIA DRIVE Replicator 配有模板写入器,例如基础写入器和 KITTI 写入器。
其中,基础写入器涵盖了广泛的真实数据标签,包括对象类、2D 和 3D 中的紧密和松散边界框、语义和实例掩码、深度输出、遮挡、法线等。
类似地,也有激光雷达/普通雷达写入器,可用于将激光点云数据导出为 numpy 数组,或将随边界框、语义和对象标签一起导出为任何相关的自定义格式。
这些写入器可为开发者提供示例,可根据自定义标记格式配置自己的写入器,并扩展数据生成工作。
最后,为大家介绍一款令人兴奋的软件,Omniverse 团队倾力打造的 Replicator Insight。
Replicator Insight 是一款基于 Omniverse Kit 构建的独立应用程序,可用于检查渲染的合成数据集,并叠加用于训练的各种真值标签。
Replicator Insight 可支持所有合成数据的生成用例,包括 DRIVE、Isaac和 Omniverse Replicator。
下面来看一个示例(见图 8):用户可以在这个可视化工具中加载 DRIVE Replicator 生成的数据,并为场景中的不同对象类别开启和关闭不同的真值标签。
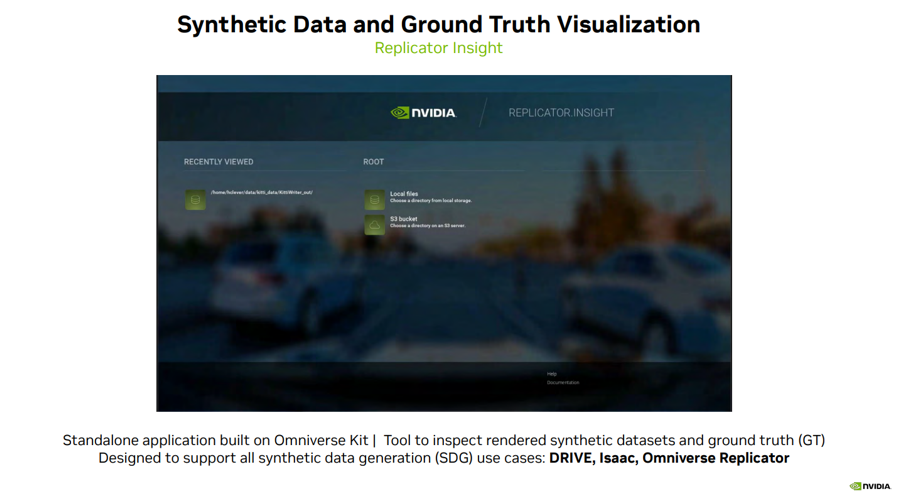
图 8
借助这个可视化工具,用户可以播放视频、梳理数据集,甚至可以在深度和 RGB 数据等不同视图之间进行比较。
用户还可以更改播放帧率和深度范围等参数,或者在自动驾驶汽车训练前快速将数据集可视化。
这将帮助开发者轻松理解新的真值标签类型和解析复杂的数据集。
总的来说,这是一款功能强大的工具,让用户在每次查看数据时都能获得新的见解,不管这些数据是真实的还是合成的。
小结
以上,总结了 DRIVE Replicator 过去一年的最新发展,并分享了开发者可以如何借助 DRIVE Replicator 生成多样化的合成数据集,以及准确的真值数据标签,从而加速自动驾驶汽车的开发和验证。NVIDIA 在为各种现实世界用例生成高质量的传感器数据集方面取得了令人欣喜的进展,期待后续与大家进一步交流!
原文标题:一文看懂 DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
- 英伟达
+关注
关注
22文章
3597浏览量
89585
原文标题:一文看懂 DRIVE Replicator:合成数据生成加速自动驾驶汽车的开发和验证
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
Waabi使用生成式AI大规模地交付自动驾驶汽车
极氪与Mobileye携手加速自动驾驶技术中国本地化
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
自动驾驶汽车传感器有哪些
吉利与Foretellix合作开发自动驾驶汽车
未来已来,多传感器融合感知是自动驾驶破局的关键
边缘计算与自动驾驶系统如何结合
自动驾驶发展问题及解决方案浅析
自动驾驶数据集的生成模型之WoVoGen框架原理

康谋方案 |加速自动驾驶系统开发的技术解决方案
语音数据集在自动驾驶中的应用与挑战
LabVIEW开发自动驾驶的双目测距系统
使用合成数据处理自动驾驶新视角感知

自动驾驶标准与认证研究:标准化体系助力高阶自动驾驶落地和汽车出海






 工商网监
工商网监
评论