 如何使用DDPM提取特征并研究这些特征可能捕获的语义信息
如何使用DDPM提取特征并研究这些特征可能捕获的语义信息
摘要
背景介绍:去噪扩散概率模型DDPM最近受到了很多研究关注,因为它们优于其他方法,如GAN,并且目前提供了最先进的生成性能。差分融合模型的优异性能使其在修复、超分辨率和语义编辑等应用中成为一个很有吸引力的工具。
研究方法:作者为了证明扩散模型也可以作为语义分割的工具,特别是在标记数据稀缺的情况下。对于几个预先训练的扩散模型,作者研究了网络中执行逆扩散过程马尔可夫步骤的中间激活。结果表明这些激活有效地从输入图像中捕获语义信息,并且似乎是分割问题的出色像素级表示。基于这些观察结果,作者描述了一种简单的分割方法,即使只提供了少量的训练图像也可以使用。
实验结果:提出的算法在多个数据集上显著优于现有的替代方法。
算法
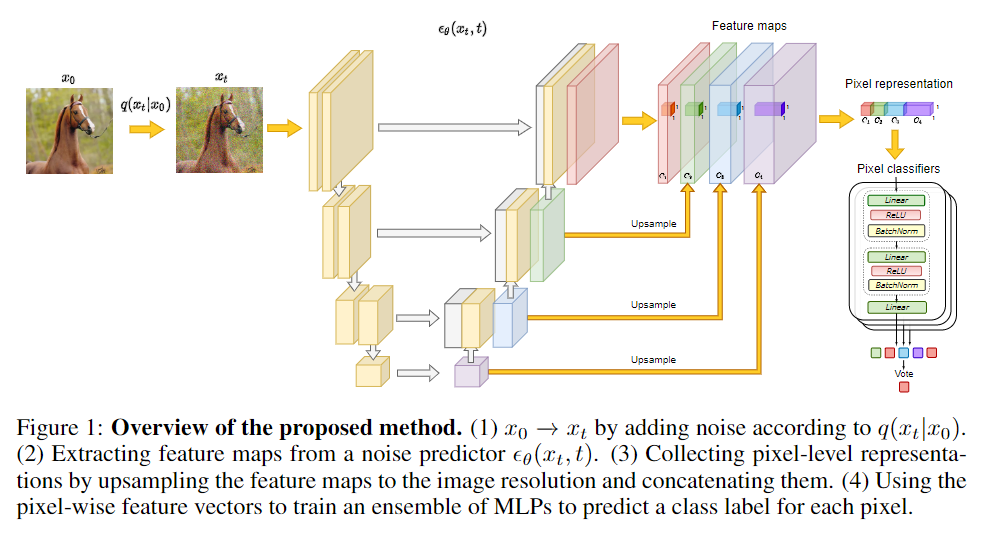
首先,简要概述DDPM框架。然后,我们描述了如何使用DDPM提取特征,并研究这些特征可能捕获的语义信息。

表征分析
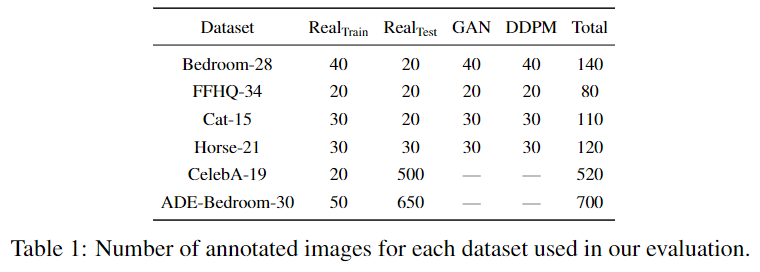
作者分析了噪声预测器θ(xt,t)对不同 t 产生的表示。考虑了在LSUN Horse和FFHQ-256数据集上训练的最先进的DDPM checkpoints。
来自噪声预测器的中间激活捕获语义信息:对于这个实验,从LSUN Horse和FFHQ数据集中获取了一些图像,并分别手动将每个像素分配给21和34个语义类中的一个。目标是了解DDPM生成的像素级表示是否有效地捕获了有关语义的信息。为此,训练多层感知器(MLP),以根据特定扩散步骤t上18个UNet解码器块中的一个生成的特征来预测像素语义标签。
请注意,只考虑解码器激活图,因为它们还通过跳跃连接聚合编码器激活图。MLP在20张图片上接受训练,并在20张图片上进行评估。预测性能以平均IoU衡量。
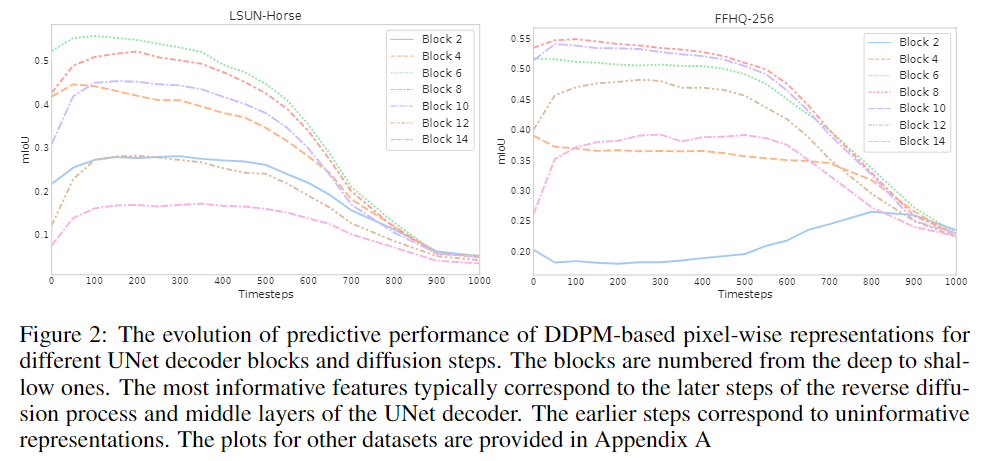
图2显示了不同解码块和扩散步骤t的预测性能演变。解码块从深到浅依次编号。图2显示了噪声预测器θ(xt,t)产生特征的IoU随不同的块和扩散步骤而变化。
特别是,对应于反向扩散过程后续步骤的特征通常更有效地捕获语义信息。相比之下,早期步骤相对应的特征通常没有什么信息。在不同的解码块中,UNet解码器中间层产生的特征似乎是所有扩散步骤中信息最丰富的。
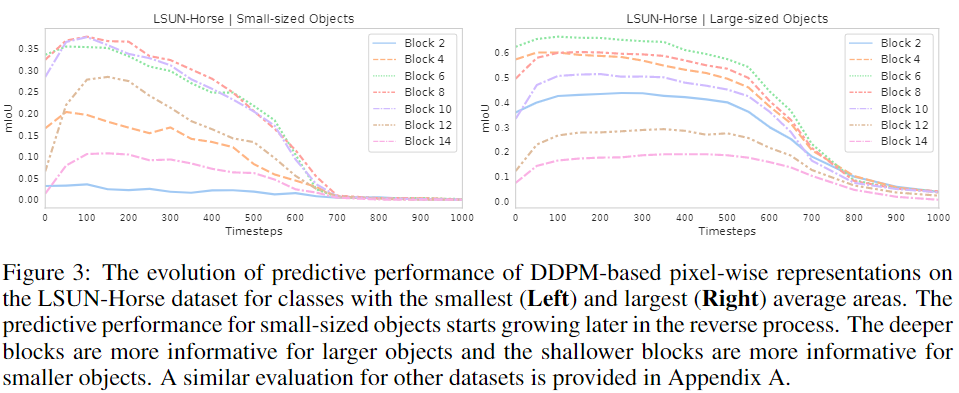
此外,根据标注数据集中的目标的平均面积分别考虑小型和大型语义类。然后,独立评估不同UNet解码块和扩散步骤中这些类的平均IoU。LSUN Horse的结果如图3所示。
正如预期的那样,在相反的过程中,大型对象的预测性能开始提前增长。对于较小的对象,浅层解码块的信息量更大,而对于较大的对象,深层解码块的信息更大。在这两种情况下,最有区别的特征仍然对应于中间块。
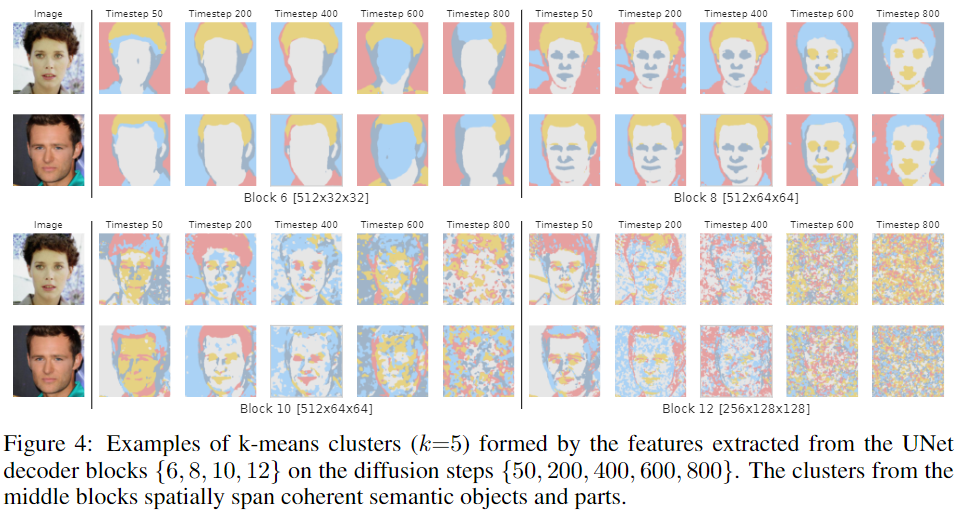
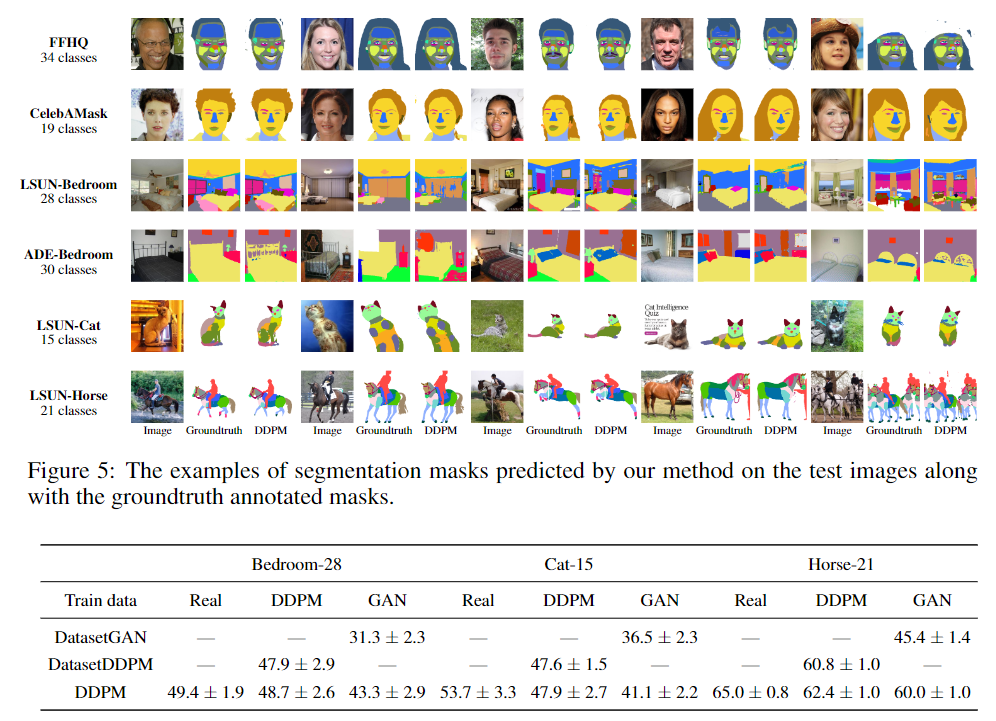
图4显示了由FFHQ checkpoint从扩散步骤{50,200,400,600,800}的解码块{6,8,10,12}中提取的特征形成的k-means聚类(k=5),并确认聚类可以跨越连贯的语义对象和对象部分。
在块B=6中,特征对应于粗糙的语义掩码。在另一个极端,B=12的特征可以区分细粒度的面部部位,但对于粗碎片来说,语义意义较小。在不同的扩散步骤中,最有意义的特征对应于后面的步骤。
将这种行为归因于这样一个事实,即在反向过程的早期步骤中,DDPM样本的全局结构尚未出现,因此,在这个阶段几乎不可能预测分段掩码。图4中的掩码定性地证实了这种直觉。对于t=800,掩码很难反映实际图像的内容,而对于较小的t值,掩码和图像在语义上是一致的。
基于DDPM的few-shot语义分割
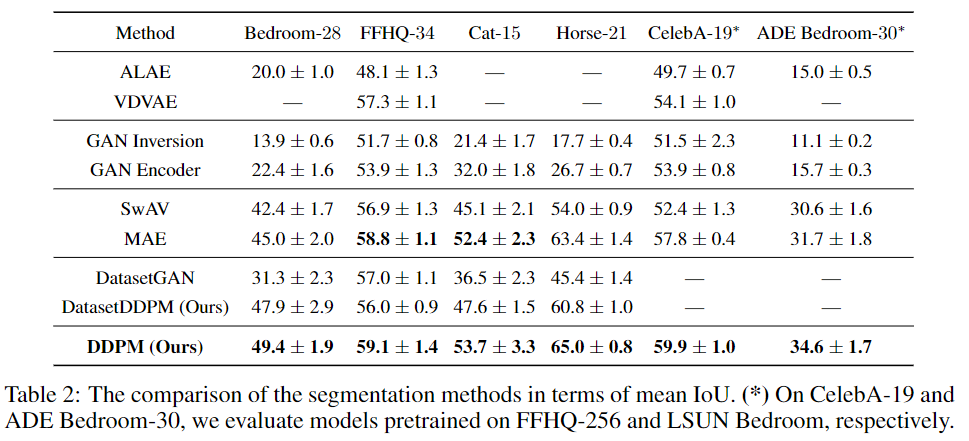
上述观察到的中间DDPM激活的潜在有效性表明,它们可以被用作密集预测任务的图像表示。图1展示了整体图像分割方法,该方法利用了这些代表的可辨别性。更详细地说,当存在大量未标记图像{X1,…,XN}⊂时,考虑了few-shot半监督设置。
第一步,以无监督的方式对整个{X1,…,XN}训练扩散模型。然后使用该扩散模型提取标记图像的像素级表示。在本工作中,使用UNet解码器中间块B={5,6,7,8,12}的表示,以及反向扩散过程的步骤t={50,150,250}。
实验
审核编辑:刘清
-
解码器
+关注
关注
9文章
1143浏览量
40716 -
感知器
+关注
关注
0文章
34浏览量
11841 -
MLP
+关注
关注
0文章
57浏览量
4241
原文标题:ICLR 2022 | 基于扩散模型(DDPM)的语义分割
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于OWL属性特征的语义检索研究
模拟电路故障诊断中的特征提取方法
基于已知特征项和环境相关量的特征提取算法
基于OWL属性特征的语义检索研究
故障特征提取的方法研究
特征量的选择和提取

颜色特征提取方法
结合双目图像的深度信息跨层次特征的语义分割模型

基于自编码特征的语音声学综合特征提取
结合词特征与语义特征的网络评价对象识别
将高级语义信息隐式地嵌入到检测和描述过程中来提取全局可靠的特征






 工商网监
工商网监
评论