 百度智算峰会精彩回顾:视觉大模型训练与推理优化
百度智算峰会精彩回顾:视觉大模型训练与推理优化
在昨日举行的 “2022 百度云智峰会·智算峰会” 上,百度智能云发布国内首个全栈自研的AI基础设施 “百度 AI 大底座”,引发行业的广泛关注。其中,百度百舸·AI 异构计算平台作为 AI IaaS 层的重要构成,是 AI 大底座坚实的基础设施。百度百舸·AI 异构计算平台整合了百度自研的 AI芯片“昆仑芯”,在 AI 计算、存储、加速、容器方面进行系统优化,发挥算力的最佳性能和效率。
在本次峰会上,NVIDIAGPU计算专家陈庾分享了以“视觉大模型训练与推理优化”为题的演讲,以 Swin Transformer 模型为例,介绍了 NVIDIA 在视觉大模型训练与推理优化上的探索和实践经验,包括在 Swin Transformer 的训练和推理上采用到的加速技巧以及对应的加速效果。这些加速方法目前已经应用到百度百舸·AI 异构计算平台的 AIAK 加速功能中,助力各行业客户的 AI 业务加速落地。
以下为演讲内容概要。
视觉大模型简介:Swim Transformer
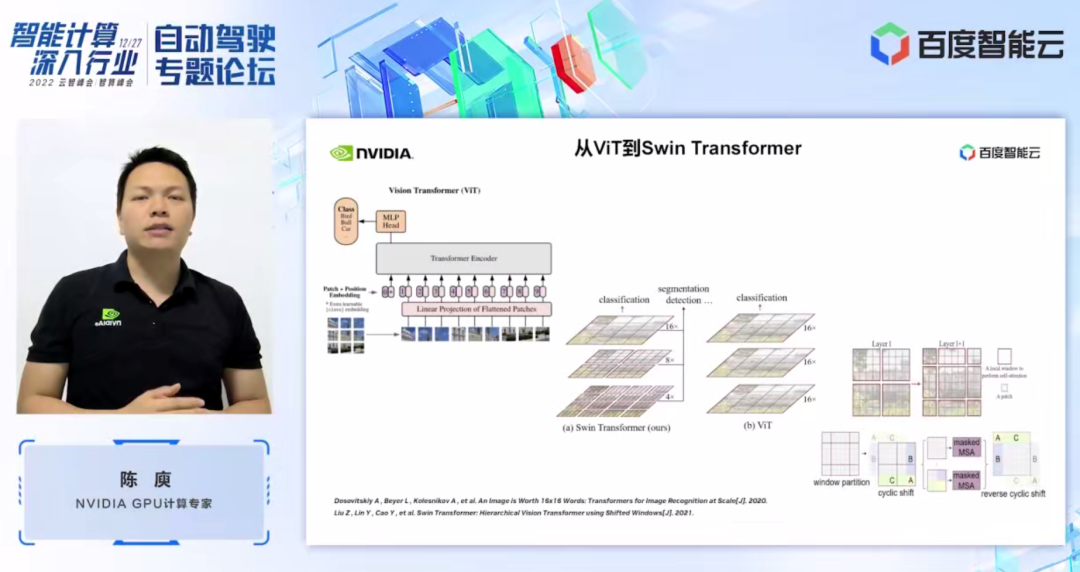
在介绍 Swin Transformer 之前,我们可以先回顾一下 Vision Transformer (ViT) 的模型结构。如左图所示,ViT 会将一个图像分割成一系列的图像块(patch),然后通过基于 Transformer 的编码器对这一系列图像块进行编码,最后得到可用于分类等任务的特征。
而 Swin Transformer,它引入了 window attention 的概念,不同于 ViT 对整个图像进行注意力计算(attention)。Swin Transformer 会先将图像划分成若干个窗口(window),然后仅对窗口内部的图像块进行对应的注意力计算,从而减少计算量。为了弥补窗口带来的边界问题,Swin Transformer 进一步引入 window shift 的操作。同时为了使得模型有更丰富的位置信息,Swin Transformer 还在注意力计算时引入了 relative position bias。
在 Swin Transformer 的网络结构中,我们也可以看到, Swin Transformer 被划分为多个阶段(stage),其中每个阶段的分辨率是不一样的,从而形成了一个分辨率金字塔,这样也使得每个阶段的计算复杂程度也逐渐降低。每个阶段中对应若干个 transformer block。
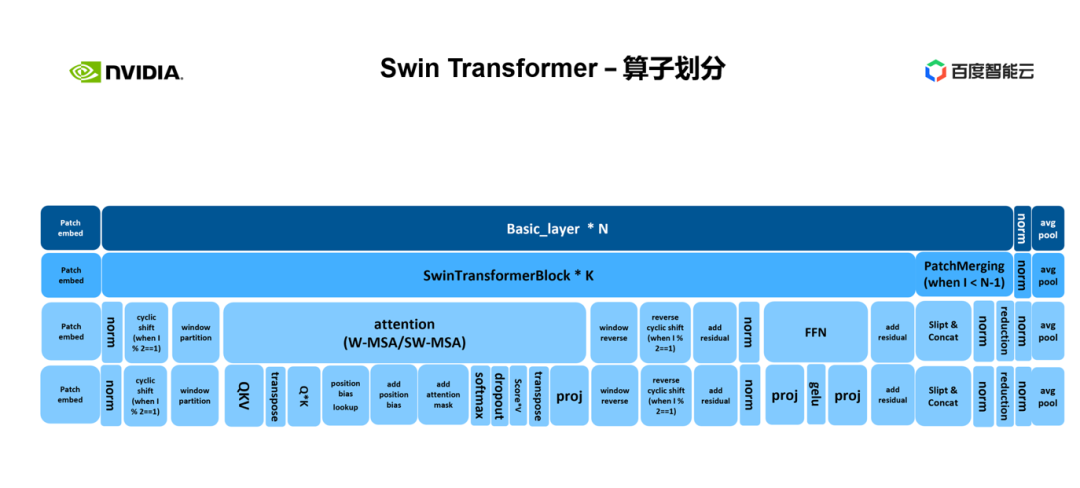
接下来,我们从具体操作的角度来对 Swin Transformer 进行算子的划分。可以看到,一个 transformer block 中涉及到三大部分,第一部分是如 window shift、partition、reverse 的一些窗口相关的操作,第二部分是注意力计算,第三部分是 FFN 计算。而 attention 和 FFN 部分又可以进一步细分为若个算子,最终如图所示,我们可以将整个模型细分为几十个算子的组合。这样的算子划分,对于我们进行性能分析,定位性能瓶颈以及开展加速优化而言,都是非常重要的。
视觉大模型 Swim Transformer 的训练加速
接下来,介绍 NVIDIA 在 Swim Transformer 模型训练加速上进行的优化工作。对于 Swin Transformer 而言,我们一般采用数据并行的方式进行多 GPU 训练,我们发现卡间通讯的开销占比会相对较少,所以在这里,我们优先对单 GPU 上的计算瓶颈进行优化。

首先,我们通过 nsight system 性能分析工具来看一下整个 baseline 的性能表现。左图所示的是 FP32 的 baseline,可以看到它的 GPU 利用率是很高的,而其中占比最高的是矩阵乘法相关的 kernel。
那么对于矩阵乘法而言,我们的一个优化手段,就是充分利用 tensor core 进行加速,可以考虑直接采用tf32 tensor core 或者在混合精度下采用 fp16 tensor core。在这里,我们采用了混合精度的方案,可以看到右图中,矩阵乘法的 kernel 由于采用了 fp16 tensor core,其耗时占比有了明显下降。此外,采用混合精度的方式,我们也可以在 kernel io 上取得一定的收益。整体而言,在 Swin-Large 模型上,通过混合精度的方式,我们可以取得了 1.63 倍的吞吐提升。
下一个优化方案是算子融合。算子融合一般而言可以为我们带来两个好处:一个是减少 kernel launch 的开销。如左图所示,两个 cuda kernel 的执行需要两次 launch,那样可能会导致 kernel 之间存在一定的空隙,使得 GPU 空闲。
如果我们将两个 cuda kernel 融合成一个 cuda kernel,一方面节省了一次 launch,同时也可以避免 gap 的产生。另外一个好处是减少了 global memory 的访问,因为 global memory 的访问是非常耗时的。而两个独立的 cuda kernel 之间要进行结果传递,都需要通过 global memory,将两个 cuda kernel 融合成一个 kernel,我们就可以在寄存器或者 shared memory 上进行结果传递,从而避免了一次 global memory 写和读,从而提升性能。
对于算子融合,我们第一步,是采用现成的 apex 庫来进行 Layernorm 和Adam 中操作的融合。可以看通过简单的指令替换,我们可以使能 apex 的 fused layernorm 和 fused Adam,从而使得加速效果从 1.63 倍提升至 2.11 倍。
除了利用现有的 apex 库,NVIDIA 也进行了手工的融合算子开发。这里展示的是,我们针对 Swin Transformer 特有的 window 相关操作,如 window partition、shift、merge 等进行的融合算子开发。可以看到,通过引入我们的定制化融合算子,可以将加速比进一步提升至 2.19 倍。
接下来展示的是,NVIDIA 对 mha 部分的融合工作。Mha 部分是 transformer 模型中一个占比很大的模块,因此对它的优化往往可以带来较大的加速效果。从图中可以看到,在没有进行算子融合之前,mha 部分的操作占比为 37.69%,其中包括了不少 elementwise 的 kernel。我们通过将相关操作融合成一个独立的 fmha kernel,从而将加速比进一步提升 2.85 倍。
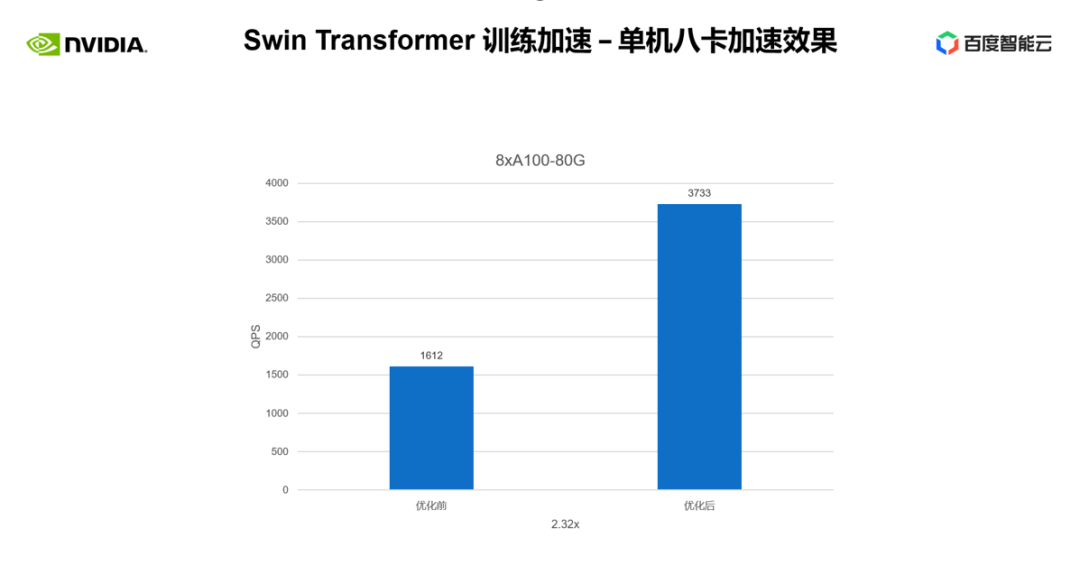
上述是我们在单卡上取得的训练加速效果。我们再来看一下单机 8 卡的训练情况,可以看到,通过上述优化,我们可以将训练吞吐从 1,612 提升至 3,733,取得 2.32 倍的加速。
视觉大模型 Swim Transformer 的推理加速
接下来,介绍 NVIDIA 在 Swim Transformer 模型推理加速上进行的优化工作。
跟训练一样,推理的加速离不开算子融合这一方案。不过相对于训练而言,在推理上进行算子融合有两个好处:一,推理上的算子融合不需要考虑反向,所以 kernel 开发过程中不需要考虑保存计算梯度所需要的中间结果;二,推理过程允许预处理,我们可以对一些只需要一次计算便可重复使用的操作,提前算好,保留结果,每次推理时直接调用从而避免重复计算。
在推理侧,NVIDIA 进行了不少算子融合,在这里挑选了两个加速效果比较明显的算子进行介绍。
首先是mha 部分的算子融合,我们将 position bias lookup 这一操作提前到预处理部分,从而避免每次推理时都进行 lookup,然后将 batch gemm、softmax、batch gemm 融合成一个独立的 fmha kernel。可以看到,融合后,该部分取得了 10 倍的加速,而端到端也取得了 1.58 倍的加速。
另一个算子融合是QKV gemm + bias 的融合,gemm 和 bias 的融合是一个十分常见的融合手段。在这里为了配合我们前面提到的 fmha kernel,我们需要对 weight 和 bias 提前进行格式上的变换,这种提前变换也体现了上文提到的,推理上进行算子融合的灵活性。最后,通过 QKV gemm+bias 的融合,我们可以进一步取得 1.1 倍的端到端加速。
除算子融合以外,我们使用了矩阵乘法 padding 的优化手段。在 Swin Transformer 的计算中,有时候我们会遇到主维为奇数的矩阵乘法,这时候并不利于我们的矩阵乘法 kernel 进行向量化读写,从而使得 kernel 的运行效率变低。这时候我们可以考虑对参与运算的矩阵主维进行 padding 操作,使其变为 8 的倍数,这样一来,矩阵乘法 kernel 就可以以 alignment=8,一次读写 8 个元素的方式来进行向量化读写,提升性能。
如下表所示,我们将 n 从 49 padding 到 56 后,矩阵乘法的 latency 从 60.54us(微秒) 下降为 40.38us,取得了 1.5 倍的加速比。

下一个优化手段,是巧用 half2 或者 char4 这样的数据类型。
以 half2 为例,可以带来以下三个好处:
一,向量化读写可以提升显存的带宽利用率并降低访存指令数。如右图所示,通过 half2 的使用,访存指令减少了一半,同时 memory 的 SOL 也有显著提升。
二, 结合 half2 专有的高吞吐的数学指令,可以减低 kernel 的时延。
三,在进行 reduction 时,采用 half2 数据类型意味着一个 cuda 线程同时处理两个元素,可以有效减少空闲的线程数。最终通过使用 half2,我们可以观察到图示的 addBiasResidual 这一个 kernel,latency 从 20.96us 下降为 10.78us,加速 1.94 倍。
下一个优化手段,是巧用寄存器数组。在我们进行 layernorm 或者 softmax 等 Transformer 模型常见的算子优化时,我们经常需要在一个 kernel 中多次使用同一个输入数据,那么相对于每次都从 global memory 读取,我们可以采用寄存器数组来缓存数据,从而避免重复读取 global memory。
由于寄存器是每个 cuda 线程独占的,所以在进行 kernel 设计时,我们需要提前设定好每个 cuda 线程所需要缓存的元素个数,从而开辟对应大小的寄存器数组,并且在分配每个 cuda 线程所负责元素时,需要确保我们可以做到合并访问。
如右图所示,当我们有 8 个线程时,0 号线程可以处理 0 号元素,当我们有 4 个线程是,0 号线程则处理 0 号和 4 号元素,如此类推。我们一般建议可以采用模板函数的方式,通过模板参数来控制每个 cuda 线程的寄存器数组大小。
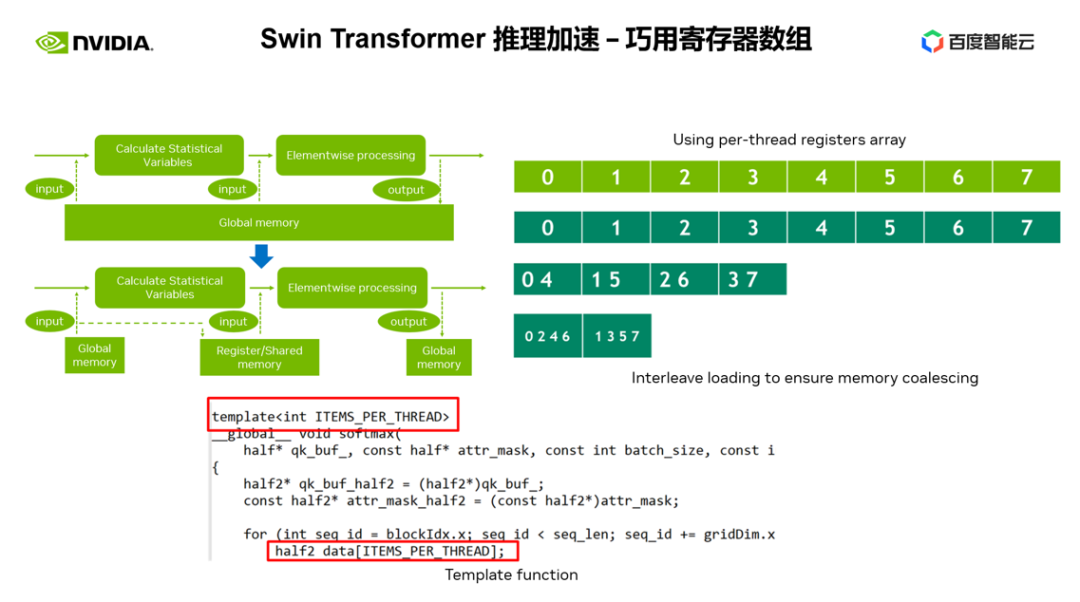
此外,在使用寄存器数组时,需要保证我们的下标是常量,如果是循环变量作为下标,我们应该尽量保证可以进行循环展开,这样可以避免编译器将数据放到了时延很高的 local memory 中,如图所示,我们在循环条件中添加限制,通过 ncu 报告可以看到,避免了 local memory 的使用。
最后一个我想介绍优化手段是 INT8 量化。INT8 量化是推理加速非常重要的加速手段,对于 Transformer based 的模型而言,INT8 量化往往可以带来不错的加速效果。
而对于 Swin Transformer 来说,通过结合合适的 PTQ 或 QAT 量化方案,可以在取得良好加速效果的同时,保证量化精度。通过 QAT,我们可以保证精度损失在千分之 5 以内。
而在 PTQ 那一列,我们可以看到 swin large 的掉点比较严重。我们可以通过禁用 FC2 和 PatchMerge 中的部分量化结点,来进一步提升量化精度,这其实就是一个性能和精度的 tr 平衡了。
接下来介绍 NVIDIA 在推理侧取得的加速效果。

左上图优化后 跟 pytorch 的时延对比,右下图为优化后 FP16 下跟 pytorch 以及 INT8 优化跟 FP16 优化的加速比。可以看到,通过优化,在 FP16 精度上,我们可以取得,相对于 pytorch 2.82x~7.34x 的加速,结合 INT8 量化,我们可以在此基础上进一步取得 1.2x~1.5x 的加速。
总结:视觉大模型 Swim Transformer 训练与推理加速技巧
本次分享中我们介绍了一系列训练与推理加速技巧,其中包括 :
一,混合精度训练、低精度推理,使用更高性能的 Tensor Core 进行计算矩阵乘法或卷积计算;
二、算子融合;
三、cuda kernel 优化技巧 :如矩阵补零,向量化读写,巧用寄存器数组等。
结合上述优化技巧,加速效果:
在训练上,以 Swin-Large 模型为例,取得了单卡 ~2.85x 的加速比,8 卡 2.32x 的加速比;
在推理上,以 Swin-tiny 模型为例,在 FP16 精度下取得了 2.82x - 7.34x 的加速比,结合 INT8 量化,进一步取得 1.2x - 1.5x 的加速比。
上述介绍的视觉大模型训练与推理的加速方法,已经在百度百舸·AI 异构计算平台的 AIAK 加速功能中实现。
原文标题:百度智算峰会精彩回顾:视觉大模型训练与推理优化
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
- 英伟达
+关注
关注
22文章
3602浏览量
89634 - 大模型
+关注
关注
2文章
2070浏览量
1825
原文标题:百度智算峰会精彩回顾:视觉大模型训练与推理优化
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
摩尔线程和滴普科技完成大模型训练与推理适配
摩尔线程千卡智算集群与滴普企业大模型已完成训练及推理适配

百度文心大模型扩展合作领域
李彦宏:开源模型将逐渐滞后,文心大模型提升训练与推理效率
【机器视觉】欢创播报 |百度智能云发布千帆大模型一体机
百度智能云正式发布了《百度智能云水业大模型白皮书》

APUS入驻百度灵境矩阵,普惠AI大模型插件能力

百度世界大会2023:大模型“重构”智能汽车,百度Apollo发布多个高阶智驾解决方案

大模型“重构”智能汽车,百度Apollo发布多个高阶智驾解决方案

百度世界2023看点 大模型改变世界

百度世界2023看点 文心大模型4.0正式发布百度文库变身生产力工具






 工商网监
工商网监
评论