 SA-Siam:用于实时目标跟踪的孪生网络A Twofold Siamese Network for Real-Time Object Tracking
SA-Siam:用于实时目标跟踪的孪生网络A Twofold Siamese Network for Real-Time Object Tracking
论文地址:https://openaccess.thecvf.com/content_cvpr_2018/papers/He_A_Twofold_Siamese_CVPR_2018_paper.pdf
摘要
1.本文核心一:将图像分类任务中的 语义特征 (Semantic features)与相似度匹配任务中的外观特征(Appearance features)互补结合,非常适合与目标跟踪任务,因此本文方法可以简单概括为:SA-Siam=语义分支+外观分支;
2.Motivation:目标跟踪的特点是,我们想从众多背景中区分出变化的目标物体,其中难点为:背景和变化。本文的思想是用一个语义分支过滤掉背景,同时用一个外观特征分支来泛化目标的变化,如果一个物体被语义分支判定为不是背景,并且被外观特征分支判断为该物体由目标物体变化而来,那么我们认为这个物体即需要被跟踪的物体;
3.本文的目的是提升SiamFC在目标跟踪任务中的判别力。在深度CNN训练目标分类的任务中,网络中深层的特征具有强的语义信息并且对目标的外观变化拥有不变性。这些语义特征是可以用于互补SiamFC在目标跟踪任务中使用的外观特征。基于此发现,我们提出了SA-Siam,这是一个双重孪生网络,由语义分支和外观分支组成。每一个分支都使用孪生网络结构计算候选图片和目标图片的相似度。为了保持两个分支的独立性,两个孪生网络在训练过程中没有任何关系,仅仅在测试过程中才会结合。
4.本文核心二:对于新引入的语义分支,本文进一步提出了通道注意力机制。在使用网络提取目标物体的特征时,不同的目标激活不同的特征通道,我们应该对被激活的通道赋予高的权值,本文通过目标物体在网络特定层中的响应计算这些不同层的权值。实验证实,通过此方法,可以进一步提升语义孪生网络的判别力。
其仍然沿用SiamFC在跟踪过程中所有帧都和第一帧对比,是该类方法的主要缺陷。
相关工作
RPN详细介绍:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC详细介绍:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN详细介绍:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
1.SiamFC:对于A,B,C三个图片,假设C图片和A图片是一个物体,但是外观发生了一些变化,B和A没有任何关系。SiamFC网络输入两张图片,那么经过SiamFC后会得到A和C相似度高,A和B相似度低。通过上述SiamFC的功能,自然地其可以用于目标跟踪算法中。SiamFC网络突出优点:无需在线fine-tune和end-to-end跟踪模式,使得其可以做到保证跟踪效果的前提下进行实时跟踪。
2.集成跟踪器:大多数跟踪是一个模型A,利用模型A对当前数据进行计算得到跟踪结果,集成跟踪器就是它有多个模型A,B,C,分别对当前数据进行分析,然后对结果融合得到最终的跟踪结果。本文的语义特征+外观特征正是借鉴了集成跟踪器的思路。在集成跟踪器,模型A,B,C相关度越低,跟踪效果越好,这个很好理解,如果他们三非常相关,那么用三个和用一个没啥区别,因为这个原因,本文的语义特征和外观特征网络在训练过程中是完全不相关的。
框架
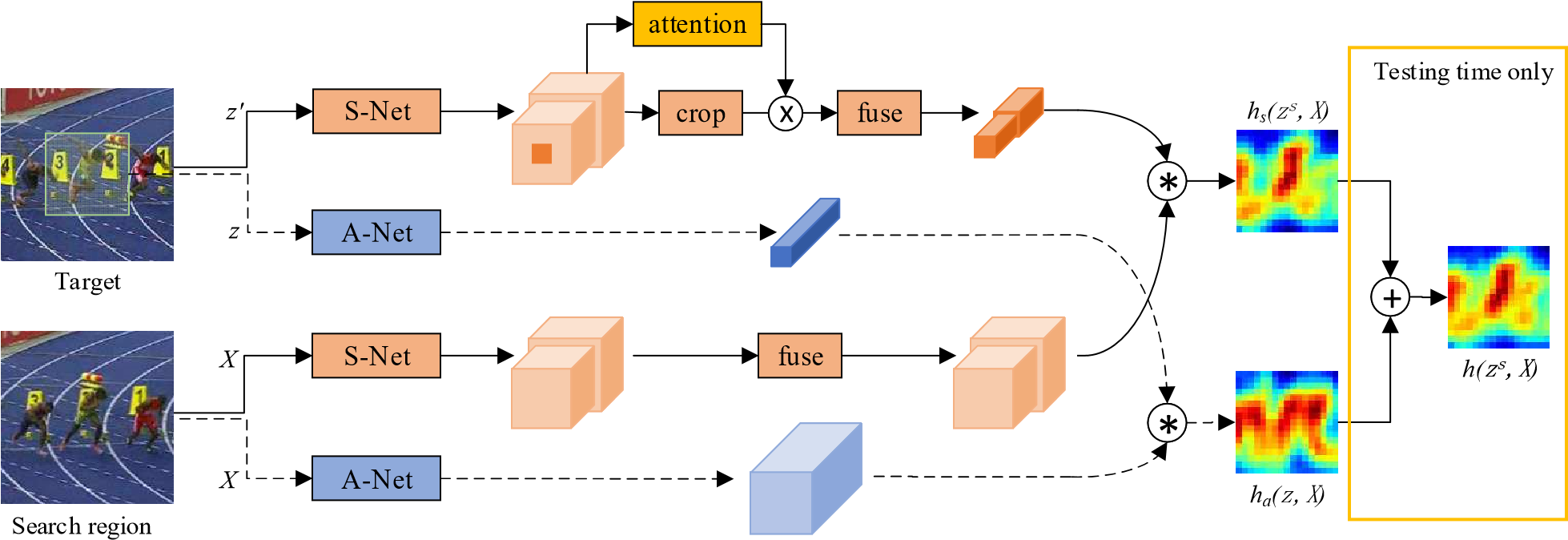
提议的双重SA-Siam网络的体系结构。A-Net表示外观网络。用虚线连接的网络和数据结构与SiamFC完全相同。S-Net表示语义网络。提取最后两个卷积层的特征。信道关注模块基于目标和上下文信息确定每个特征信道的权重。外观分支和语义分支是单独训练的,直到测试时间才结合。
1.外观分支(蓝色部分)
一个目标A送到网络P里,一个比目标大的搜索域S送到网络P里,A出来的特征图与S出来的特征图进行卷积操作得到相关系数图,相关系数越大,越可能是同一个目标,网络则采用和SiamFC中一样的网络。
外观分支以(z,X)为输入。它克隆了SiamFC网络。用于提取外观特征的卷积网络称为A-Net。来自外观分支的响应映射可以写为:
L(y,v)=\\frac{1}{D}\\sum_{u\\in D}l(y[u],v[u])
在相似性学习问题中,A-Net中的所有参数都是从头开始训练的。
通过最小化逻辑损失函数L(·)来优化A-Net,如下:
arg \\min_{\\theta_a}\\frac{1}{N} \\sum^N_{i=1}{(L(h_a(z_i,X_i,\\theta_a),Y_i))}
其中θa表示A-Net中的参数,N是训练样本的数量,Yi是ground truth的响应。
2.语义分支(橙色部分)
这篇文章的重点便是此。橙色的表示语义网络,用的是预训练好的AlexNet,在训练和测试时固定所有参数,只提取最后conv4和conv5的特征,目标模板变为zs,zs和X一样大,和z有一样的中心,但包含了上下文信息,因为支路上加了通道注意力模型,通过目标和周围的信息来决定权重,选择对特定跟踪目标影响更大的通道。另外,为了更好的进行后续的相关操作,作者将上下两支路加入融合模型,加入了1×1的卷积层,对提取的两层每层进行卷积操作,使目标模板支路和检测支路的特征通道相同,而且通道总数和外观网络的通道一样。
语义分支网络训练时只训练通道注意力模块和融合模块。
来自语义分支的响应映射可以写为:
h_s(z^s,X)=corr(g(\\xi ·f_s(z)),g(f_s(X)))
ξ是通道权重,g()是对特征进行融合,便于相关操作。
损失函数L(·)如下:
arg \\min_{\\theta_a}\\frac{1}{N} \\sum^N_{i=1}{(L(h_s(z_i^s,X_s,\\theta_a),Y_i))}
其中θs表示可训练参数,N是训练样本的数量。
3.结合
外观网络和语义网络分开训练,语义网络只训练通道注意力模块和融合模块。在测试时间内,最终的响应图计算为来自两个分支的图的加权平均值:
h(z^s,X)=\\lambda h_a(z,X)+(1-\\lambda)h_s(z^s,X)
其中 λ 是加权参数,以平衡两个分支的重要性。在实践中,λ可以从验证集估计。作者通过实验得出 λ=0.3 最好。
4.语义分支中的Channel Attention机制
为什么要这么做:高维语义特征对目标的外观(图片的形变、旋转等)变化是鲁棒的,导致判别力低。为了提升语义分支的判别力,我们设计了一个Channel Attention模块。直觉上,在跟踪不同的物体时,不同的通道扮演着不同的角色,某些通道对于一些物体来说是极其重要的,但是对于其他物体而言则可以被忽略,甚至可能引入噪声。如果我们能自适应的调整通道的重要性,那么我们将获得目标跟可靠地特征表达。为了达到这个目的,不仅目标对于我们来说是重要的,其周围一定范围内的背景对于我们来说同样重要,因此这里输入网络的模板要比外观分支大一圈。
下面讲具体怎么实现这个功能的。

通道注意力通过最大池化层和多层感知器(MLP)生成通道i的加权系数ξi。
上述图中,假设是conv5层的第i个通道特征图,维度为22×22,将该图分割成3×3份(其中中间的那份为6×6,是准确的目标),经过max-pooling操作后变成3×3的图,经过一个两层的MLP网络(Multi-Layer Perceptron多层感知机,含有9个神经元和一个隐层,隐层采用ReLU函数)后得到分数,在sigmoid一下(为了让得分系数在0~1之间)得到最终的得分系数。值得注意的是:这里的得分系数计算操作仅仅在第一帧进行计算,后续帧沿用第一帧的结果,所以其计算时间是可以忽略不计的。
实验
数据维度:在我们的实现中,目标图像块z的尺寸为127×127×3,并且zs和X都具有255×255×3的尺寸。对于z和X,A-Net的输出特征具有尺寸分别为6×6×256和22×22×256。来自S-Net的conv4和conv5功能具有尺寸为24×24×384和22×22×256通道的zs和X。这两组功能的1×1 ConvNet每个输出128个通道(最多可达256个通道) ),空间分辨率不变。响应图具有相同的17×17维度。

学习更多编程知识,请关注我的公众号:

-
神经网络
+关注
关注
42文章
4771浏览量
100704 -
图像处理
+关注
关注
27文章
1289浏览量
56720
发布评论请先 登录
相关推荐
LabVIEW 不适用于实时处理( Real-Time )的应用?
如何获得NI Linux Real-Time系统?
如何获得NI Linux Real-Time系统?
FPGA and Real-time技术
Real-Time DSP Implementation f
Improved Real-Time Quantitativ
BQ32002,pdf(Real-Time Clock (R
DS1346,DS1347(compatible real-time clocks RTCs)
MathWorks推出Simulink Real-Time,提供完整、集成的实时仿真和测试
基于信息熵的级联Siamese网络目标跟踪方法
SiamFC:用于目标跟踪的全卷积孪生网络 fully-convolutional siamese networks for object tracking
SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network 孪生网络
DW-Siam:Deeper and Wider Siamese Networks for Real-Time Visual Tracking 更宽更深的孪生网络
新版本Real-time Edge正式发布啦!高效的工业边缘实时应用开发,就用它!
恩智浦Real-time Edge v2.7正式发布!





 工商网监
工商网监
评论