 走进多核编程
走进多核编程
一
走进多核编程
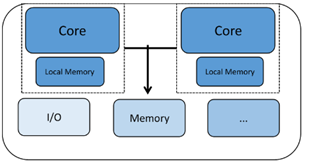
CPU 发展早期阶段,性能的提升主要来自于主频的提升和架构的优化,当这条优化途径出现瓶颈后,多核 CPU 开始流行起来。多核心同时执行任务极大地提高了系统整体性能,但也对硬件架构和软件编写提出了更大的挑战。各个核心都有自己的 Cache,以及不同层级的 Cache,彼此共享内存。一个典型的多核 CUP 架构如下图所示:
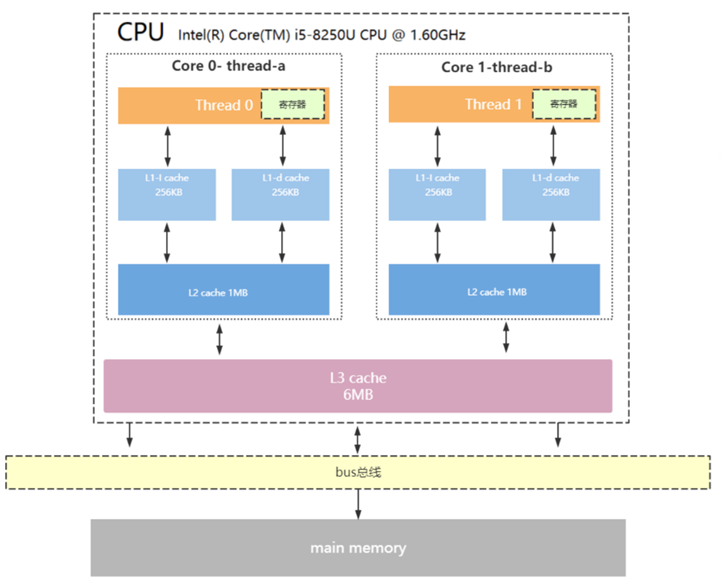
利用多核心的优势在各个核之间互相配合完成任务,如何进行各个核心间的数据同步(各个核心所属 L1 Cache/L2 Cache 数据的同步)是问题的关键所在。虽然发展出多种数据同步方式,以及流水线乱序执行的模式,但数据在各个核之间的一致性和可见性并不是那么理想;再加上编译器也会做优化,最终导致各个核的指令执行顺序和各个变量值的可见性变得不确定。
这种现象可以通称为重排,即原本应该有全序的内存读写操作被打乱。不过无论产生什么样的重排,都会保证对于单线程内部的执行结果不会有任何区别。下面是一个简单例子:
1. //Thread1
2. //readywasinitializedtofalse
3. p.init();
4. ready=true;
1. //thread2
2. if(ready){
3. p.bar();
4. }
对于 Thread 1 内部,p 和 ready 没有关联,完全可以被重排而不影响正确性,而 Thread 2 依赖 ready 做标识位,一旦重排,Thread 2 在看到 ready 为 true 的时候 p 都可能没有 init,显然这是有问题的。
二
多核编程中临界区保护
利用多线程做并发的任务中通常都会有公共的临界区,比如最常用的一种数据结构:并发队列,生产者和消费者需要访问队列的公共内存进行写入和读取。目前对于临界区的保护方式通常可以分为三个级别:互斥、Lock-free 和 Wait-free。
1、互斥
互斥,顾名思义每个线程访问临界区之前都需要获得互斥锁,如果被别的线程占用了就阻塞等待。当进入临界区的线程发生阻塞,或被操作系统换出时,会出现全局阻塞,因为获得锁的线程被换出无法执行操作,而未获得锁的线程也只能一同等待,出现了阻塞传播。如果另一个线程先进入临界区,有可能反而可以更快的顺利完成。因为存在全局阻塞的可能性,采用互斥技术进行临界区保护的算法有着最低的阻塞容忍能力。
2、Lock-free
Lock-free 允许单个线程阻塞,但是会保证系统整体层面上的吞吐。如果当程序线程运行足够长时间的情况下,至少有一个线程取得了进展,那么就可以说这个算法是 Lock-free 的。如果一个线程被挂起,那么 Lock-free 算法保证剩余的线程仍然可以进行。
使用锁的代码一定不是 Lock-free 的,因为一个线程加锁后如果被系统切出去了,其他所有线程都处于等待中。但是没用锁也不一定是 Lock-free,因为普通的代码逻辑也可能会导致一个线程夯住另一个线程。锁之所以在高并发的时候表现很差,主要原因是加锁的线程会夯住其他等待加锁的线程,Lock-free 可以很好地解决这一问题。
在实现上一般先假设临界区不存在竞争,各个线程直接开始在临界区的执行,执行过程中通过良好的程序设计,让这段预先的执行是无冲突并且是可回滚的。最终有一个需要同步的提交操作,一般基于原子变量 CAS 操作,或者版本校验等机制完成。在提交阶段如果发生冲突,那么被仲裁为失败的各方需要对临界区预执行进行回滚,并重新发起一轮尝试。
注意,并不是说 Lock-free 的算法就一定比加锁的算法好,Lock-free 需要处理更多更复杂的 race condition 移机 ABA 等问题,编写出合理的 Lock-free 代码也需要更深厚的技术功底,需要对底层有更多地了解,完成相同目的的代码会比用锁更复杂,执行时间可能更长,代码也更难理解。
很多场景下合理地使用锁就能很好的胜任,Lock-free 和锁之间在应用场景上更多的是一种互补的关系。Lock-free 算法的价值在于其保证了一个或所有线程始终在做有用的事,而不是绝对的高性能。但 Lock-free 相较于锁在并发度高(竞争激烈导致上下文切换开销变得突出)的某些场景下会有很大的性能优势,比如实现一个多线程的 Lock-free queue。总的来说,在多核环境下,Lock-free 是很有意义的。
3、Wait-free
Lock-free 技术主要解决了临界区内的阻塞传播问题,但是本质上,依然是多个线程排队顺序经过临界区。而 Wait-free 和 Lock-free 的主要区别也就体现在系统吞吐上。在无全局停顿的基础上,Wait-free 进一步保障了执行任意算法的线程,都应该在有限的步骤内完成。不只是整体算法时时刻刻都存在有效计算,每个线程依然是需要持续进行有效的计算。这就要求多线程在临界区内不能被细粒度地串行起来,而必须是同时都能进行有效计算。虽然理论角度存在不少有 Wait-free 的算法,但大多并不具备工业使用的价值。
4、相关技术
Lock-free 和 Wait-free 编程中最重要的两个相关技术就是原子操作和控制 Memory Order。
CPU 保证没有线程能观察到原子操作的中间态,也就是说一个原子操作对于所有的线程来说要么做了要么没做。原子操作主要包括赋值原子操作、Read-Modify-Write(比如C++ 11里的fetch_add)、Compare-And-Swap(比如 C++ 11 里的 Compare_exchange_strong)等操作。原子操作保证了各线程在进行共享内存的存取的时候能读到完整的值。
Memory Order 即内存排序,指 CPU 访问主存的顺序。可以是编译器在编译时产生,也可以是 CPU 在运行时产生。为了充分利用不用内存的总线带宽,现代处理器大多是乱序执行的。无锁算法没有显式的锁,将会直接观察到这些和代码顺序不一致的重排,C++ 11 引入的 Memory Order 给使用者提供了一种跨平台的通用方法来限制上述两种重排。
三
Memory Order
Memory Model 内存模型,定义了特定处理器上或者工具链上的重排情况。某个处理器或者工具链对代码的重排会严格遵循对应的 Memory Model。这里讨论的重排只是针对单个线程内部在单个核内的指令的执行顺序问题。可以理解为指定 Memory order,就是通过限制重排来保证共享数据的可见性和正确同步。
1、Reorder 类型和 Memory Order 的强弱
对内存的操作可以概括为读和写,可以表示为 Load 和 store 操作,因此 Reorder 也就可以整体上分为以下四种类型:
Load-load reorder:两个读操作之间重排;
Load-store reorder:原来在写操作之前的读操作重排到之后;
Store-load reorder:原来在读操作之前的写操作重排到之后;
Store-store reorder:两个写操作之间重排。
Memory Model 既有软件层面的 Software Memory Model,又有硬件平台的 Hardware Memory Model,下图中是几种 CPU 架构下的 Hardware Memory Model。
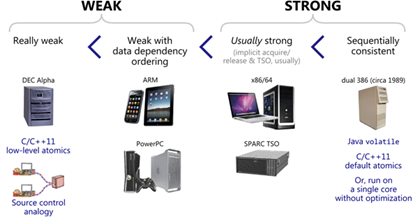
DEC Alpha 架构下,上述四种 Reorder 都有可能发生,只保证不改变单线程内部的执行正确性。
ARM 架构下的 CPU 也允许四种 Reorder 的发生,额外保证了数据依赖顺序。
X86/X64 平台属于强 Memory Model 的范畴,只可能发生 Store-load reorder。
C++ 11 中原子操作的内存序属于 Software Memory Model 的范畴,在软件层面进行相关限制,让 CPU 实现相应操作的效果。
2、Compiler Barrier 与 Runtime Memory Barrier
无论是哪种 Memory Model 中涉及的重排,都是指的在没有其他限制的情况。为了能够保证程序的正确性,CPU 和编译器(语言)的设计者都预留了手方法来改变这些重排,这类方法可以抽象成一个统一的概念 Barrier:屏障。需要使用者用代码来限制编译阶段和运行阶段的重排,因此可以分为 Compiler Barrier 和 Runtime Memory Barrier。
Compiler Barrier,编译器层面的屏障,可以防止编译器在将源码转换成机器码的过程中重排。简单的例子如下:
inta,b;
intmain()
{
a=b+1;
//asmvolatile("":::"memory");
b=0;
return0;
}
对于以上代码,使用 gcc 4.9.4 整体不开启优化进行编译,得到汇编代码如下:
$ gcc -S main.cpp $ cat main.s ... movl_b(%rip),%eax addl$1,%eax movl%eax,_a(%rip) movl$0,_b(%rip) movl$0,%eax popq%rbp ...
同样使用 gcc 4.9.4 整体开启优化进行编译,得到汇编代码如下:
$gcc–O2-Smain.cpp $catmain.s ... movl_b(%rip),%eax movl$0,_b(%rip) addl$1,%eax movl%eax,_a(%rip) xorl%eax,%eax ...
如果想要整体开启优化,但是对于部分代码不想要重排,那么就可以使用 Compiler Barrier,在 gcc 里,asm volatile("" ::: “memory”)就是这么一个 Compiler Barrier。在使用 Compiler Barrier 后,使用使用 gcc 4.9.4 整体开启优化进行编译,得到汇编代码如下:
$gcc-O2-Smain.cpp $catmain.s ... movl_b(%rip),%eax addl$1,%eax movl%eax,_a(%rip) movl$0,_b(%rip) xorl%eax,%eax ...
可以看到和未开启编译优化时的结果保持一致。
Compiler Barrier 只能保证编译阶段不重排。在多核系统里,光做到这一点还不够,因为它没法对 CPU 核心运行时的重排做出限制。因此,在多核编程中,通常需要同时对编译重排和运行时重排做出限制,需要使用到 Runtime Memory Barrier。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19259浏览量
229649 -
操作系统
+关注
关注
37文章
6801浏览量
123283 -
CAS
+关注
关注
0文章
34浏览量
15201 -
cache技术
+关注
关注
0文章
41浏览量
1062
发布评论请先 登录
相关推荐
TMS320C6678无法连接?看看多核通信方式TI-IPC和OpenMP多核编程
【中级】labview每日一教【11.14】labview多核编程篇
每日一教labview视频教程【1.10】labview多核并行运行编程
NI LabVIEW的多核编程技术指南
英特尔与微软揭示并行计算的未来,多核编程任重而道远
多核架构及编程技术
基于NI LabVIEW图形化编程对多核处理器和其他并行硬件进行编程
数据流编程以及LabVIEW多核编程
Arduino多核编程:简单例子

掌握多核编程和调试的挑战





 工商网监
工商网监
评论