 什么是大数据采集和预处理
什么是大数据采集和预处理
大数据导论
理顺大数据的演进路线
数据湖是个啥?
一般情况下,大数据处理的流程为:数据采集和预处理、数据存储、数据分析和数据可视化。
数据采集与预处理便是大数据流程的第一步。
首先来看, 数据是如何产生的 ?
(1)为满足企业业务目标的达成,企业通常会建设IT系统,IT系统承载企业业务处理的同时,必然会产生交易记录、付款记录等等,这些都会保存在数据库中;
(2)为了更好地预测消费者的需求,购物网站通常也会记录消费者的网页浏览时长、点赞、收藏、购买喜好等,这些都会记录在日志文件中;
(3)为了满足消费者获取信息的便捷性,各大门户网站、短视频网站等都提供了大量的Web网页供用户浏览,Web网页中呈现大量的文本、音视频等;
那么,这些数据产生后,都 以什么形式存在 ?
(1)以文件的形式存在,如csv文件、图像文件、视频文件、日志文件;
(2)以数据库的形式存在,如关系型数据库MySql\\oracle、非关系型数据库MongoDB;
(3)以Web网页的形式存在,如新浪、搜狐、知乎等;
(4)以实时数据的形式存在,如物联网络中各种传感器监测到的数据;
这样,具象化的数据采集就变成从数据库、Web网页、文件、物联传感器等地方获取。因数据存在形式的差异,采用的获取方法也不尽相同:
(1)文件、Web网页的抓取,通常采用直接编程的方式获取,如网页爬虫;
(2)实时消息的获取,则采用相应的协议,如MQTT、Coap、HTTPS;
(3)对数据库数据的获取,则更多采用SQL的形式提取出来;
获取的数据,还存在什么问题 ?
获取的原生数据,可能会存在数据缺失、数据重复、数据类型和值都不对等问题,需要对数据进行加工处理,这一过程被称为“数据清洗”;
如果数据源是多个,并且要装入到同一数据仓库时,则需要进行“数据集成”;
数据集成后,往往需要更高粒度的抽象,擦除一些细节数据,如原有按交易时间记录的数据,现在需要按天进行统计,此时需要进行聚类处理,称之为“数据转换”;
同时,注意到大数据可能涉及到隐私问题,也需要去除隐私数据,这一过程称为“数据脱敏”;
而数据清洗、数据集成、数据转换、数据脱敏这一系列的过程,称为 数据预处理 。
经过预处理后的数据放在哪?
可以将其放入数据仓库中,如Hive\\HDFS;
也可以将其放入数据湖中,不但可以存储原始数据,也可以存储结构化、半结构化、非结构 化的数据,并且还能支撑数据的分析。具体可参考《数据湖是个啥?》
数据的采集与处理是繁琐的,也是有迹可循的,聪明的研究人员实现了一系列 工具或框架 :
(1)网页爬虫系统:Apache Nutch、Crawler4j、Scrapy;
(2)日志收集工具:Flume、Logstash、Filebeat、Fluentd;
(3)多源异构数据采集工具:Sqoop、Datax。
同时,也形成大数据采集的方法论,如ETL。
ETL也就是Extract-Transform-Load,对应为提取-转换-加载,充当了数据源与数据仓库之间的数据流转管道。其基本思想是:从日志、数据库、Web页面中提取数据,并数据进行转换,按照预先规划的Schema,将数据加载到数据仓库中去。
Kettle(水壶)、Sqoop(SQL-to-Hadoop)、DataX是ETL工具的代表。
-
数据采集
+关注
关注
38文章
6052浏览量
113617 -
数据存储
+关注
关注
5文章
970浏览量
50892 -
大数据
+关注
关注
64文章
8882浏览量
137391
发布评论请先 登录
相关推荐
如何使实时数据采集处理系统保持数据的高速传输
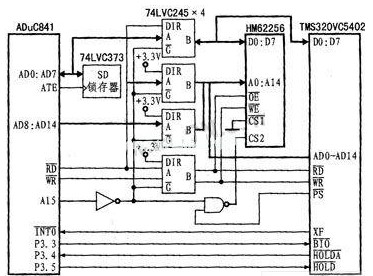
基于串行通信的虚拟仪器数据采集器
一种基于FPGA和DSP的高速数据采集设计方案介绍
基于SOPC的数据采集与处理系统设计
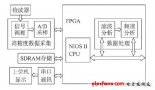
大数据技术及应用介绍1
每日一课 | 智慧灯杆之大数据采集技术简介

大数据采集系统分为几类
数控机床数据采集如何实现?






 工商网监
工商网监
评论