 大数据相关介绍:Hadoop的生态系统构成
大数据相关介绍:Hadoop的生态系统构成
(1)可靠性高。Hadoop具有多个工作数据副本,确保可针对失败的节点(个人理解:一个节点可理解为一台计算机或服务器)进行重新分布处理。
(2)扩展性高。Hadoop可扩展至数干节点。
(3)效率高。Hadoop以并行方式工作,处理数据速度快。
(4)成本低。与一体机、商用数据仓库等对比,Hadoop是开源的,项目的软件成本因此降低。
二、Hadoop的生态系统构成
(1)HDFS是一种分布式文件系统,运行于大型商用机集群,HDFS为Hadoop提供高可靠性的底层存储支撑。
(2)MapReduce是一种分布式数据处理模式和执行环境,为Hadoop提供高性能计算能力。
(3)HBase位于结构化存储层(根据网络资料理解:HBase位于类似windows系统中多层级文件夹的结构中),是一个分布式的列存储数据库。
(4)Zookecper是一个分布式的、高可用性的协调服务,提供分布式锁(根据百度百科:分布式锁是控制分布式系统间同步访问共享资源的方式)等基本服务,用于构建分布式应用,为Hadoop提供了稳定服务和failover机制(根据网络资料理解:failover机制是失效转移机制,当主要组件由于失效或预定关机时间原因而无法工作时,该机制将系统组件的功能转移至二级系统组件)。
(5)Hive是一个建立于Hadoop基础之上的数据仓库,它提供在Hadoop文件中用于数据整理、特殊查询、分析存储的数据集工具。
(6)Pig是一种数据流语言和运行环境,用于检索大的数据集,可简化Hadoop常见工作任务。
(7)Sqoop为HBasc提供了方便的RDBMS(根据百度百科:关系数据库管理系统)数据导入功能,可较为方便地将传统数据库数据迁移至HBase中。
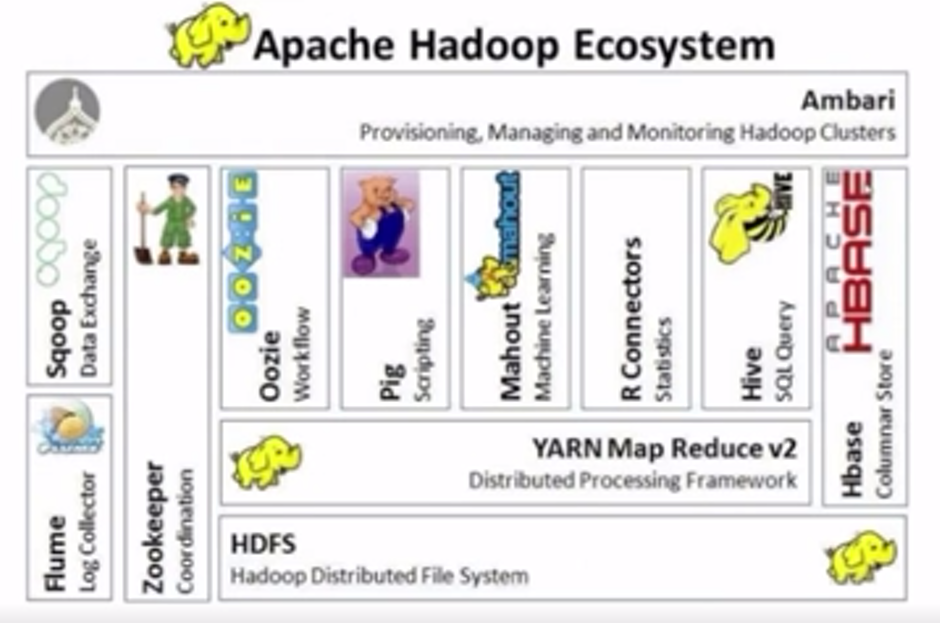 图片来源:学堂在线《大数据导论》
图片来源:学堂在线《大数据导论》
三、Spark介绍
Spark是另一种大数据系统,由一系列解决不同种类问题的系统和编程库构成。下文以APACHE Spark为例,介绍Spark。
APACHE Spark由Spark SQL、Spark Streaming、MLlib、GraphX组成。
Spark SQL可以通过编写SQL程序的方式处理数据。因为Spark所有计算依赖于内存,中途计算结果不会被存储,所以Spark的一个优势是数据处理速度快,但同时,Spark对内存的要求较高。
Spark Streaming可实现数据流计算(根据百度百科理解:因为数据的价值随着时间的流逝而降低,传统的数据库管理系统无法快速且无法持续的处理大量且不断更新的大数据,所以产生了可实现数据一出现就处理的数据流计算)。
GraphX是图计算框架(根据网路资料理解:图计算框架是在大数据中高效计算、存储、管理图数据的框架)。
四、Spark的优点
(1)Spark基于内存的迭代计算,计算速度快。
(2)Spark引入RDD(弹性分布式数据集:可将RDD视为一个对象,所有的数据处理均封装于此对象中),容错性高。
(3)Spark可提供更多的数据集操作类型,数据处理能力更强。数据集操作类型可分为Transformations和Actions两类(根据网络资料:Transformations可提供包括Map函数等操作,Actions可提供包括Reduce函数等操作)。
(4)Spark可支持更多编程语言,包括:Scala(根据网络资料:类似java的编程语言)、Java、Python、R。
编辑:黄飞
-
Hadoop
+关注
关注
1文章
90浏览量
15971 -
HDFS
+关注
关注
1文章
30浏览量
9588 -
大数据
+关注
关注
64文章
8882浏览量
137391
原文标题:大数据相关介绍(10)——大数据系统(下)
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐


大数据hadoop入门之hadoop家族产品详解
STM32单片机基础01——初识 STM32Cube 生态系统 精选资料分享
STM32Cube生态系统更新
IT的生态系统概述
基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能





 工商网监
工商网监
评论