 MAXQ竞争分析研究
MAXQ竞争分析研究
为了演示MAXQ微控制器的功能,我们采用了为竞争对手的微控制器编写的基准代码,并在MAXQ2000上运行。结果表明,MAXQ是目前最好的16位微控制器内核之一。
介绍
MAXQ独特的转换触发架构使其成为16位微控制器市场中的佼佼者。MAXQ指令集具有单时钟和指令周期运算,用于跳转、调用、返回、环路控制和算术运算。因此,MAXQ使应用能够在比其他微控制器更短的时间内处理更多的数据。因此,设计人员可以在其应用中添加更多功能,或者通过快速完成所需任务并在低功耗停止模式下花费更多时间来降低功耗。
为了演示MAXQ的竞争分析能力,我们采用了为展示MSP430而编写的基准代码,在MAXQ上运行,并监测MAXQ的性能。竞争对手的代码最初使MAXQ函数相对较慢且效率低下。后来,当Rowley高度优化的MAXQ编译器向市场发布时,我们重新运行了基准测试代码。我们发现Rowley的编译器更有效地使用了MAXQ架构特性,并且MAXQ的性能优于德州仪器(TI)MSP430和Atmel AVR。MAXQ在更少的时钟周期内执行相同的代码。此外,这种加速的性能并没有因为额外的代码大小而对用户造成不利影响——MAXQ的代码大小在竞争代码大小的2%以内。
本应用笔记详细介绍了我们对MAXQ、Atmel AVR和TI MSP430架构的研究。这项研究是透明的——没有编译器优化的技巧或专门的代码来迫使一个微控制器比另一个微控制器表现得更好。vwin 网站上提供了项目文件和源代码,以便可以复制结果。
关于方法的注意事项
在本次研究的两个编译器IAR Embedded Workbench和Rowley CrossWorks中,我们使用Rowley的编译器来生成MAXQ的基准数据,因为它充分利用了MAXQ功能。IAR 和 Rowley 编译器结果均用于 MSP430 和 AVR 微控制器测试。
执行时间数据是使用IAR的嵌入式工作台和Rowley的CrossWorks工具集附带的模拟器收集的。计算的执行周期不包括启动时间;计数从 main() 函数的入口点开始,以 main() 函数的 return 语句结束。
代码大小以字节为单位,包括常量和代码段。这是因为某些工具在 CODE 段中包含应用程序常量,这会使设备的代码密度错误地显示为高。组合 CODE 和 CONSTANT 段的大小可确保等效比较。
通常,我们将编译器配置为对所有设备使用其最高代码优化级别。这通常意味着在面向最小代码大小时启用所有优化,在面向最快代码时启用几乎所有优化(因为某些编译器优化会牺牲速度来换取代码大小)。在某些情况下,高优化设置会导致问题 - 生成的代码无法正确模拟,从未到达 return 语句。通常,当优化级别更改时,代码开始工作。我们将指出何时需要降低优化级别。本应用笔记随附的项目文件包含用于生成基准数据的优化设置。
TI 基准测试
该基准测试是德州仪器发布的一套测试,用于展示 MSP430。该套件包含 10 个单独的基准测试:
8 位数学例程
8 位矩阵(阵列)访问
8 位开关语句
16 位数学例程
16 位矩阵(阵列)访问
16 位开关语句
32 位数学例程
浮点数学例程
有限脉冲响应算法
矩阵乘法
按照TI测试参数,MAXQ表现不佳。它生成的代码比大多数其他微控制器更大、更慢。当然,TI 研究表明 MSP430 是比较中的赢家。然而,透明国际的方法存在缺陷,需要进一步分析。因此,我们研究了MAXQ在Rowley CrossWorks编译器上的表现。
TI 结果
TI 研究提供了执行速度(以时钟周期为单位)和代码密度(以字节为单位)的结果,如表 1 和表 2 所示。请注意,某些器件名称(直接取自TI应用笔记)不清楚。例如,8051 是指 12 时钟、6 时钟、4 时钟甚至 1 时钟 8051 架构吗?
| 应用 | MSP430F135 | ATmega8 | 图18F242 | 8051 | H8/300L | MC68HC11 | 最大Q20 | ARM7-TDMI (拇指) |
| 8 位数学 | 299 | 157 | 318 | 112 | 680 | 387 | 421 | 185 |
| 8 位矩阵 | 2899 | 5300 | 20045 | 17744 | 9098 | 15412 | 31691 | 2227 |
| 8 位交换机 | 50 | 131 | 109 | 84 | 388 | 214 | 58 | 146 |
| 16 位数学 | 343 | 319 | 625 | 426 | 802 | 508 | 815 | 259 |
| 16 位矩阵 | 5784 | 24426 | 27021 | 29468 | 15280 | 23164 | 60214 | 2998 |
| 16 位交换机 | 49 | 144 | 163 | 120 | 398 | 230 | 51 | 146 |
| 32 位数学 | 792 | 782 | 1818 | 2937 | 1756 | 1446 | 1034 | 115 |
| 浮点 | 1207 | 1601 | 1599 | 2487 | 2458 | 4664 | 1943 | 108 |
| 远红外滤波器 | 152193 | 164793 | 248655 | 206806 | 245588 | 567139 | 464558 | 43191 |
| 矩阵乘法 | 6633 | 16027 | 36190 | 9454 | 26750 | 26874 | 66534 | 2918 |
| 总数 | 170249 | 213680 | 336543 | 269638 | 303198 | 640038 | 627319 | 52293 |
| 应用 | MSP430F135 | ATmega8 | 图18F242 | 8051 | H8/300L | MC68HC11 | 最大Q20 | ARM7-TDMI (拇指) |
| 8 位数学 | 172 | 116 | 386 | 141 | 354 | 285 | 352 | 660 |
| 8 位矩阵 | 118 | 364 | 676 | 615 | 356 | 380 | 378 | 408 |
| 8 位交换机 | 180 | 342 | 404 | 209 | 362 | 387 | 202 | 504 |
| 16 位数学 | 172 | 174 | 598 | 361 | 564 | 315 | 286 | 676 |
| 16 位矩阵 | 156 | 570 | 846 | 825 | 450 | 490 | 526 | 428 |
| 16 位交换机 | 178 | 388 | 572 | 326 | 404 | 405 | 188 | 504 |
| 32 位数学 | 250 | 316 | 960 | 723 | 876 | 962 | 338 | 620 |
| 浮点 | 662 | 1042 | 1778 | 1420 | 1450 | 1429 | 1596 | 1556 |
| 远红外滤波器 | 668 | 1292 | 2146 | 1915 | 1588 | 1470 | 1828 | 1420 |
| 矩阵乘法 | 252 | 510 | 936 | 345 | 462 | 499 | 494 | 432 |
| 总数 | 2808 | 5114 | 9302 | 6880 | 6866 | 6622 | 6188 | 7208 |
根据这些数据,MSP430 产生的代码密度最高,比 Atmel AVR 微控制器小 45%。MSP430 似乎也表现最佳,但 32 位 ARM 处理器除外。这些结果还表明,MAXQ相对较慢且效率低下。
TI 基准研究的缺陷
透明国际制定基准的方式提出了一些问题。
第一个问题是TI在他们的研究中没有使用任何优化。TI反对编译器优化,以便将编译器从考虑范围中移除,并使微控制器自行执行。这个论点的问题在于工程师仍然使用编译器来生成机器代码。如果编译器在未启用优化时未利用微控制器的架构功能,则无法实际了解微控制器的性能。此外,基准测试只有在模拟实际应用程序时才有价值。工程师可能会在实际应用中优化尺寸或速度,因此这些应作为基准研究的一部分。
TI 基准测试研究中的第二个缺陷是他们只考虑了一个编译器。诚然,当时 TI 无法使用 Rowley 编译器。现在可用,Rowley 编译器极大地更新了早期的 TI 结果。
马克西姆的方法
如上所述,我们对 TI 基准测试的重新评估主要集中在 MSP430、Atmel AVR 和 MAXQ 架构上。我们考虑了IAR Embedded Workbench和Rowley CrossWorks工具集的执行和代码大小数据。所有执行速度的结果均通过仿真得到。
本研究中的MAXQ器件是MAXQ2000微控制器。除了包括LCD控制器在内的一系列外设外,MAXQ2000还具有16个16位累加器和一个16 x 16硬件乘法加速器。在这项研究中,我们在所有三个被测器件上都启用了硬件乘法器——我们假设如果数学计算(如FIR滤波器)的性能很重要,设计人员会选择带有乘法加速器的微控制器。
对于 MSP430 器件,我们以 MSP430F149 为目标,这与他们研究中针对的 TI 器件 (MSP430F135) 不同。我们之所以选择F149,是因为它有一个硬件乘法单元,使得与MAXQ2000的比较更加公平。
之所以选择ATmega8进行研究,是因为当前的IAR编译器可以使用该微控制器的硬件乘法器生成代码。IAR 编译器无法对其他 AVR 设备(如 ATmega64 或 ATmega128)执行此操作。
从这两个工具集中收集基准测试结果非常简单。在 IAR 中,代码大小数据位于映射文件(确保它是在“项目选项”→“链接器→列表”下生成的)。向下滚动到地图文件的底部,将显示以下三行:
184字节代码存储器 80字节数据存储器
66字节CONST存储器
如前所述,我们将 CODE 和 CONST 内存部分都计入总代码大小,因为编译器在放置常量程序数据的位置上有所不同。对于测试,比较代码大小的唯一合法方法是包含常量大小。
若要在 IAR 中查找执行周期,请选择模拟器作为调试工具并开始调试。在“查看→分析”下启动代码分析器。单击“激活”按钮和“自动刷新”按钮(请参阅图 1)。调试器应自动运行到 C 代码的第一行。按 Run 键,(如果未设置断点)IAR 调试器在程序退出时终止。查看代码探查器,并在 main() 的“累积时间”下报告 周期数 - 这是在主例程和 main 调用的所有子例程中花费的周期数。
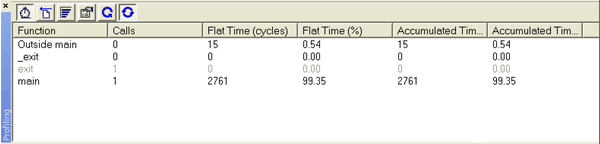
图1.IAR 代码探查器:累计时间(周期)是指在该例程及其调用的所有子例程中花费的周期数。
在 Rowley 工具集中查找生成的代码大小也非常容易。生成项目时,项目资源管理器会随项目一起列出代码大小。图 2 显示,对于 MSP430F149,16 位数学基准测试代码大小为 238 字节。
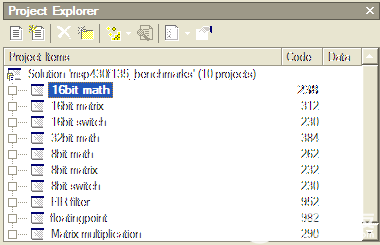
图2.Rowley 项目资源管理器显示每个项目的代码大小详细信息。
在 Rowley 工具中确定执行周期数并不像使用 IAR 那么容易 - Rowley 不会在程序结束时自动停止,也不会分离周期的花费位置。您必须在进入主程序时重置循环计数器。为此,请首先开始调试程序。当编译器在 main 的入口点停止时,双击它来重置循环计数器。
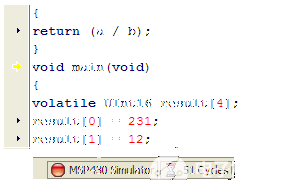
图3.当 Rowley 模拟器在 main() 处停止时,双击它来重置循环计数器(带有沙漏的图片)。
接下来,在应用程序末尾设置断点。(请注意,边距中带有蓝色三角形的线条指示可以设置断点的位置。运行到断点并记录报告的周期数。
使用罗利模拟器还有其他可能的并发症。
根据优化的不同,您可能只能在程序集级别进行模拟,在这种情况下,很难找到应用程序的末尾。最好的方法是扫描代码并在程序集代码中找到下一个 RETURN 语句,在那里设置断点,然后运行到该语句。
模拟器可能并不总是在主入口点停止。发生这种情况时,请尝试按“重新启动调试”按钮。您可能还需要手动查找主入口点并在那里设置断点。
编译器设置
使用 IAR 工具集时,项目选项中的编译器选项窗口配置为启用所有优化的最高优化级别(请参阅图 4)。若要在目标最小代码和最快执行之间切换,请将所选单选按钮从“大小”切换到“速度”。
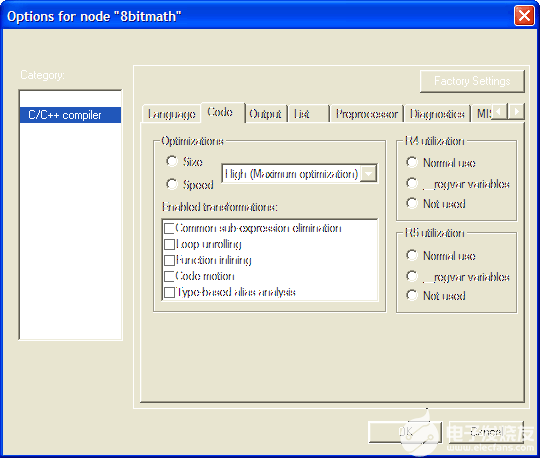
图4.IAR 编译器的选项:启用所有优化。单选按钮在优化速度和大小之间切换编译器。
Rowley的CrossWorks允许用户创建除了默认的调试和发布配置之外的构建配置。因此,本研究的基准项目还包括最快(见图 5)和最小(图 6)配置选项。最快配置删除了以牺牲指令周期为代价来评估代码大小的任何优化。
图5.Rowley的CrossWorks中使用的项目选项可实现最快的配置。
最小配置的设置如图 6 所示。启用了以牺牲周期为代价的有利于代码大小的选项,总体优化策略是最小化大小。
图6.Rowley的CrossWorks中用于最小配置的项目选项。
Analog 运行的每个基准测试的项目和源文件可在 /en/product-category/ultra-low-power-microcontrollers.html 中找到。这些项目文件中的配置与用于基准测试的配置相同。Maxim网站上的其他第三方工具提供了IAR和Rowley工具试用版的链接,因此您可以轻松重现这些基准测试结果。
MAXQ基准测试结果
表3和表4显示了MAXQ基准测试结果。执行速度再次以时钟周期的形式给出,代码大小以字节为单位给出。
| 应用 | MSP430F149 IAR | MSP430F149 罗利 | ATmega8 IAR | ATmega8 罗利 | MAXQ2000 罗利 | |||||
| 配置 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 |
| 8 位数学 | 243 | 243 | 276 | 272 | 110 | 110 | 279 | 278 | 278 | 245 |
| 8 位矩阵 | 1629 | 963 | 6243 | 2659 | 1508 | 1074 | 7348 | 3763 | 3461 | 2947 |
| 8 位交换机 | 31 | 31 | 24 | 24 | 84 | 36 | 45 | 45 | 39 | 39 |
| 16 位数学 | 219 | 219 | 250 | 250 | 275 | 266 | 348 | 330 | 194 | 191 |
| 16 位矩阵 | 1906 | 899 | 6755 | 3171 | 1147 | 697 | 5251 | 5250 | 3205 | 2691 |
| 16 位交换机 | 30 | 30 | 24 | 24 | 111 | 44 | 50 | 50 | 39 | 39 |
| 32 位数学 | 575 | 575 | 790 | 716 | 746 | 731 | 995 | 885 | 545 | 521 |
| 浮点 | 784 | 784 | 1097 | 921 | 1614 | 1565 | 1491 | 919 | 763 | 744 |
| 远红外滤波器 | 86042 | 82748 | 90812 | 82592 | 82779 | 82779 | 73598 | 66249 | 62280 | 59470 |
| 矩阵乘法 | 4254 | 2761 | 6036 | 5436 | 7799 | 2396 | 11081 | 9231 | 3704 | 3027 |
| 总数 | 95713 | 89253 | 112307 | 96065 | 96173 | 89698 | 100486 | 87000 | 74508 | 69914 |
图 7 绘制了执行速度的数据图表。仅显示最快的结果。速度以执行周期来衡量 - 条越小意味着性能越好。
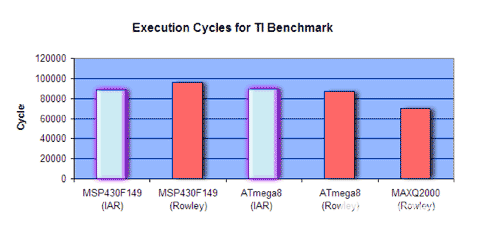
图7.最快配置设置的执行速度结果。较小的MAXQ2000棒显示出更好的性能。
| 应用 | MSP430F149 IAR | MSP430F149 罗利 | ATmega8 IAR | ATmega8 罗利 | MAXQ2000 罗利 | |||||
| 配置 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 | 小 | 快 |
| 8 位数学 | 192 | 192 | 258 | 262 | 98 | 98 | 212 | 212 | 248 | 284 |
| 8 位矩阵 | 152 | 180 | 240 | 232 | 318 | 304 | 220 | 250 | 202 | 222 |
| 8 位交换机 | 180 | 180 | 230 | 230 | 312 | 164 | 202 | 200 | 152 | 152 |
| 16 位数学 | 140 | 140 | 220 | 220 | 162 | 154 | 222 | 238 | 162 | 164 |
| 16 位矩阵 | 240 | 240 | 312 | 312 | 398 | 374 | 294 | 350 | 260 | 378 |
| 16 位交换机 | 178 | 178 | 230 | 230 | 346 | 178 | 212 | 240 | 152 | 152 |
| 32 位数学 | 236 | 236 | 284 | 388 | 306 | 296 | 380 | 460 | 274 | 324 |
| 浮点 | 1100 | 1100 | 966 | 1004 | 1026 | 1046 | 816 | 936 | 1018 | 1090 |
| 远红外滤波器 | 1178 | 1174 | 924 | 966 | 1258 | 1258 | 860 | 896 | 1024 | 1044 |
| 矩阵乘法 | 266 | 250 | 312 | 316 | 476 | 324 | 294 | 348 | 254 | 264 |
| 总数 | 3862 | 3870 | 4076 | 4160 | 4700 | 4196 | 3712 | 4130 | 3746 | 4074 |
下图(图 8)显示了最小配置结果的代码大小数据。代码大小以字节数来衡量 - 条形越小意味着代码密度越高。
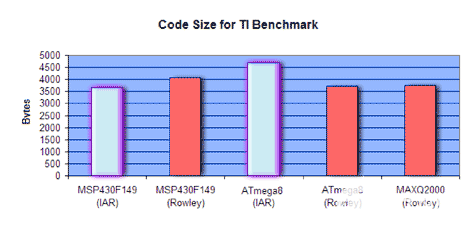
图8.最小配置设置的代码大小结果。MAXQ2000的条形越小,代码密度越好。
| 微控制器 | 编译器 | 版本 |
| 最大Q2000 | 罗利 | MAXQ 交叉工作,1.0 版,Build 2 |
| MSP430F149 | 罗利 | 适用于 MSP430 的 CrossWorks 版本,版本 1.3,内部版本 3 |
| MSP430F149 | IAR | IAR C/C++ 编译器,适用于 MSP430,V3.30A/W32 (3.30.1.1) |
| ATmega8 | 罗利 | AVR 的 CrossWorks 版本,版本 1.1,内部版本 1 |
| ATmega8 | IAR | IAR C/C++ AVR 编译器,4.10B/W32 (4.10.2.3) |
| 装置 | 工具 | 配置 | 基准 | 问题 |
| ATmega8 | 罗利 | 最小 | 16 位矩阵 | 除非将代码分解优化设置为 NONE,否则模拟不会终止。 |
| ATmega8 | IAR | 快 | 8 位矩阵、16 位矩阵 | 除非将优化级别设置为中而不是高,否则模拟不会终止。 |
| ATmega8 | IAR | 最小 | 远红外滤波器 | 即使在最低优化级别,仿真也不会终止。表3和表4中包含的数字适用于配置最快的FIR滤波器。 |
| ATmega8 | IAR | 双 | 矩阵乘法 | 模拟不会在ATmega8,ATmega16或ATmega32目标上终止。该项目的目标是ATmega64。 |
分析和总结
在不同的编译器和启用优化的情况下,上述结果表明,即使运行 TI 特制的基准代码,MSP430 也不是性能最佳的微控制器。
考虑到运行整个基准测试套件所需的总执行周期数,MAXQ2000的性能优于MSP430F149和ATmega8。MAXQ2000的周期为69,914次,而MSP430F149 (IAR)和ATmega8 (Rowley)的周期分别为89,253次和87,000次。在考虑基准代码的总大小时,三个微控制器的最佳情况结果仅相差2%,因此代码大小的任何差异都无关紧要。
由于代码密度不是此基准测试的一个因素,因此我们将更深入地研究执行速度结果。总执行周期结果由FIR滤波器结果加权,其中MAXQ2000明显优于竞争产品。MAXQ2000是数学基准测试中表现最好的,8位数学基准测试中除了ATmega8之外。MAXQ2000的性能最差的是8位和16位矩阵基准,它们将项目从一个多维数组复制到另一个多维阵列。
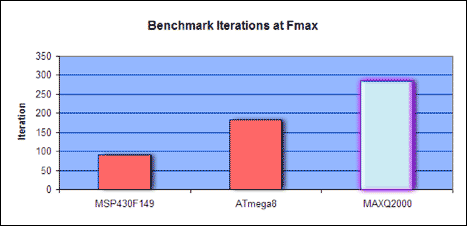
到目前为止,我们只考虑测试微控制器在时钟周期方面的性能。我们没有考虑设备的运行速度。为了进行绝对比较,我们使用每秒基准测试迭代次数,即整个 TI 基准测试套件在一秒钟内可以运行的次数。表7显示,当所有器件以相同的时钟速度运行时,MAXQ2000比MSP28F430快149%,比ATmega24快8%。当器件以最大时钟速率运行时,MAXQ2000比ATmega56快8%,比MSP218F430快149%。
| 装置 | 周期 | F.max | 1MHz 时的迭代/秒 | F 处的迭代/秒.max |
| MSP430F149 | 89,253 | 8 | 11.20 | 89.60 |
| ATmega8 | 87,000 | 16 | 11.49 | 183.84 |
| 最大Q2000 | 69,914 | 20 | 14.30 | 286.00 |
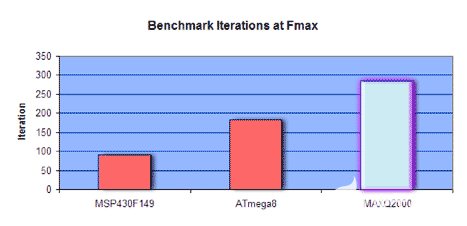
图9.以最大时钟速率运行时每秒的基准迭代次数。更高的MAXQ2000杆显示出更好的性能。
我们应该如何总结Maxim基准研究的结果?至少,它与TI基准研究的结果相悖,后者表明MAXQ微控制器架构并不引人注目。这项更新的研究表明,MAXQ2000是一款代码高效、快速的微控制器,对于任何受益于更高性能微控制器的新设计和重新设计,都应考虑使用MAXQ<>。
审核编辑:郭婷
-
微控制器
+关注
关注
48文章
7542浏览量
151307 -
控制器
+关注
关注
112文章
16332浏览量
177798 -
编译器
+关注
关注
1文章
1623浏览量
49107
发布评论请先 登录
相关推荐
继电器结构原理分析研究
耦合电感式的Boost电路分析研究
Bluetooth跳频网络Piconet闻干扰分析研究
基于MATLAB的实时数据采集与分析研究
EMI抑制方法分析研究
基于多媒体社会事件的分析研究综述







 工商网监
工商网监
评论