 cache背后的软思考
cache背后的软思考
1.前言
Cache在体系架构中占据半边山,读者又多为软件从业者、学者,个人在碰到项目瓶颈时,研读一些ARM手册,以及业内技术论文,发现cache在架构中发挥着被软件工程师低估的能力,本文从其设计角度和软件角度阐述一二;
2.Cache的设计思考
Cache的基础资料很多,多是围绕如下展开说明:cache line,组/全相连,VIVT/VIPT/PIPT等概念,一般初学者阅读后也会云里雾里,cache技术也很少被直接关注到;
所以在linux初级开发者接触cache时,脑海里会不自觉的思考:硬件行为,都是被ICer设计好的;所以他们也并没有深究cache的层次结构,也没有继续挖掘cache和驱动软件的千丝万缕的关系,脑海里想象的拓扑图,大致是这样:
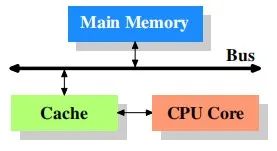
认为cache的设计就是cpu和memory之间单一的存在,从而忽略了那些ICer对cache的研究和优化,直接影响就是软件层面的优化,以及软件层面的疑难bug;这也是初学者进阶时的第一道阻碍;
那么在原厂工程师的脑海里,cache最基础的样子是这样的:
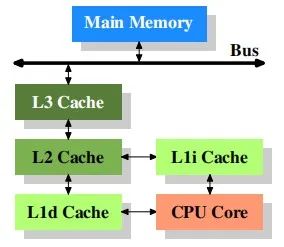
它是现在处理器基本的形态,也是最简单的形态,在ICer们的设计上,其内在协议直接影响着指令的流转:load,store等;其内在存在的load buffer和store buffer影响着你的数据一致性,你的读写指令运行速度,数据的共享属性等等,极其简单的实例:
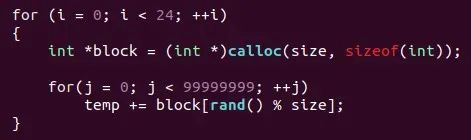
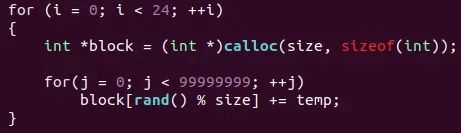
一个load执行,一个store执行,哪个快?显然prefetch最快,再深一层次思考:如果工程中,在多cpu和多thread都有数据访问需求,但是CPU和memory直接又有cache这一层大buffer,硬件和软件都做了什么,能够保证实时或访存速度?
硬件上,制定cache的各种参数时,在保证满足设计需求时,ICer们也会做这种动作:即对cache的benchmark;比如cache size和直接映射、组相连带来的收益:
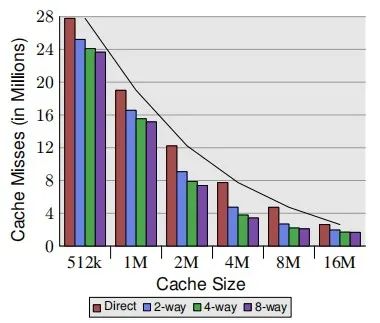
L2 cache的benchmark:
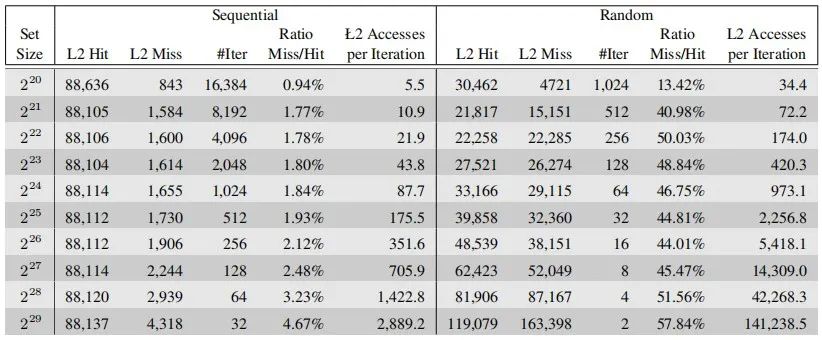
各种参数的测试结果呈现就是市面上大家可以查到的某种处理器L1 cache,L2 cache,L3 cache,以及system cache的大小,所以在大家认为很小size的cache,ICer以及架构师们,甚至是学者,都在为其能够发挥出更佳性能,更低功耗的能力,夜以继日的做研究,做实验;
进一步思考:现在处理器设计越来越复杂,越来越强,比如NUMA,大小核等等,其呈现效果又如下简单示例:
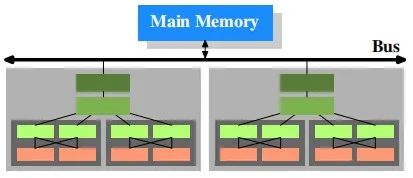
硬件层面带来了考验和升级,直接的影响给软件层面也带了考验,比如:你的数据一致性问题,IP驱动设计等等,ARM的内存模型又是弱一致性的,那么你设计的驱动,可能被动存在着潜在bug,所以进一步带来的是我们在工程问题上的思考。
1.Cache的工程思考
本人工作于ARM体系架构之上,所以日常在查阅arm官方公开的文档时,知道的愈多,疑问也愈多,思考的也愈多,但是借助linux这个开源社区,众多疑惑也慢慢得到解答,特此在工作之余将一小部分所得分享于大家,比如:cache的多个读写策略在影响着指令行为,直接导致数据的行为不一,如何在工程中认识它们?解决它们?
Cache的策略有如下:write-allocate,no write-allocate,read-allocate,read-through;
上述策略在驱动设计时,也是几乎被忽略的存在,其发挥的作用就是data是否被缓存在cache中,还是 pass到内存中,若两者皆存在,那么你的DMA在搬运数据前,有个动作就是sync,即刷新cache,保持数据在cache与内存中的一致性;
当然在内核驱动设计时,并不会指定使用哪个cache策略,因为kernel已经在某些接口中,潜在的做了相关操作,譬如大家用的ioremap_xxx这类接口就是和cache联系紧密;
可以思考:如果我不需要使用ioremap_xxx这类接口,还需要关注什么cache策略吗?
思考后的结果:dirty数据带来的不同步就是你解决不了问题的噩梦;
Dirty数据怎么处理?借助linux的驱动设计,可以给各位呈现出如下一个接口:
POC(Pointof Coherency):全局缓存一致性,即系统中所有可以发起内存访问的硬件单元的视角:CPU,DMA等;
所以虽然cache分为:L1 cache,L2 cache,L3cache,以及system cache,但是需要软件设计者必须知道的是:你想干什么?是刷新部分master所感测到的数据,还是所有master都要关注到的数据变化,这就是cache带来的可操作性;
即在不同cache层级的设计中,data的可观测性是不一样的,这也是为什么在我的脑海里,cache一直是多层级,多策略的,所以在驱动设计时,保证IP的视角看到的数据就是我设计的结果;
思考:如果只是CPU之间的data是可观测的,有没有什么指令作用域比POC更小的?
思考后的结果:POC视角太宽泛了,比POC作用域小的,即 POU:Pointof Unification;即处理器看到的视角,比如虚拟内存和物理内存映射的页表数据:TLB,MMU;
进一步思考:POC和POU又太大了,有没有只操作我dword数据的?
因为ARM的内存模型是弱一致性的,所以其在指令排序上有所行为,直接影响就是控制数据的乱序,内存屏障指令运势而生:dmb,dsb,isb;(PS:宋宝华老师的分享文章有详解);
该内存屏障指令宋老师有过介绍,不再赘述,需要关注的是:在使用上述指令时,也有作用域的区别;
Cache带给处理器的是极致性能,带给开发者是一个又一个的隐藏问题,所以剖析cache很有必要;
2.总结
本文因为篇幅问题,分享的是cache的冰山一角。cache又是体系架构中的一角,体系架构又是内核技术的一角,我又是众多读者的一角。
文献参考:论文《WhatEvery Programmer Should Know About Memory》。
审核编辑 :李倩
-
ARM
+关注
关注
134文章
9084浏览量
367371 -
cpu
+关注
关注
68文章
10854浏览量
211567 -
Cache
+关注
关注
0文章
129浏览量
28329
原文标题:cache背后的软思考
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
(分享设计)显示器上的思考者
为什么需要cache?cache是如何影响code的呢
Cache中Tag电路的设计
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速缓存(Cache),高速缓存(Cache)原理是什么?
cache结构与工作原理
什么是 Cache? Cache读写原理
CPU Cache伪共享问题
深入理解Cache工作原理
Cache的原理和地址映射
Cache分类与替换算法





 工商网监
工商网监
评论